今天介绍一种大数据时代有名的列式存储文件格式:Parquet,被广泛用于 Spark、Hadoop 数据存储。Parquet 的中文是镶木地板,意思是结构紧凑,空间占用率高。注意,Parquet 是一种文件格式!
背景
2010年 google 发表了一篇论文《Dremel: Interactive Analysis of Web-Scale Datasets》,介绍了其 Dermel 系统是如何利用列式存储管理嵌套数据的,嵌套数据就是层次数据,如定义一个班级,班级由同学组成,同学的信息有学号、年龄、身高等。
Parquet 是 Dremel 的开源实现,作为一种列式存储文件格式,2015年称为 Apache ***项目,后来被 Spark 项目吸收,作为 Spark 的默认数据源,在不指定读取和存储格式时,默认读写 Parquet 格式的文件。
今天不介绍嵌套数据是如何映射到每一列了,简单来说就是把不同层级的属性拍到一级,类似降维打击。这样,一个嵌套数据可以看成独立的多个属性,每一个属性就是一列,和表结构差不多。
写流程
虽然是按列存储,但数据是一行一行来的,那什么时候将内存中的数据写文件呢?我们知道文件只能顺序写,假如每收到一行数据就写入磁盘,那就是行式存储了。
一个解决方案是为每个列开一个文件,假如数据有 n 个属性,就需要 n 个文件,每次写数据就需要追加到 n 个文件中。但是对于文件格式来说,用户肯定希望把复杂的数据存到一个文件中,而不希望管理一堆小文件(可以想象你做了一个ppt,每一页存成了一个文件),所以一个 Parquet 文件中必须存储数据的所有属性。
另一个解决方案是在内存中缓存一些数据,等缓存到一定量后,将各个列的数据放在一起打包,这样各个包就可以按一定顺序写到一个文件中。这就是列式存储的精髓:按列缓存打包。
文件格式
按照上边这种方式,Parquet 在每一列内也需要分成一个个的数据包,这个数据包就叫 Page,Page 的分割标准可以按数据点数(如每1000行数据打成一个 Page),也可以按空间占用(如每列的数据攒到8KB合成一个 Page)。
一个 Page 的数据就是一列,类型相同,在存储到磁盘之前一般都会进行编码压缩,为了快速查询、也为了解压缩这一个 Page,在写的时候先统计一下***最小值,叫做 PageHeader,存储在 Page 的开头,其实就是 Page 的 元数据(metadata)。PageHeader 后边就是数据了,读取一个 Page 时,可以先通过 PageHeader 进行过滤。
Parquet 又把多个 Page 放在一起存储,叫 Column Chunk。于是,每一列都由多个 Column Chunk 组成,并且也有其对应的 ColumnChunk Metadata。注意,这只是一个完整数据的一个属性,一个数据的多个属性要放在多个 Column Chunk 的,这多个 Column Chunk 放在一起就叫做一个 Row Group。
下边这就是 Parquet 官方介绍:
4-byte magic number "PAR1"
<Column 1 Chunk 1 + Column Metadata>
<Column 2 Chunk 1 + Column Metadata>
...
<Column N Chunk 1 + Column Metadata>
<Column 1 Chunk 2 + Column Metadata>
<Column 2 Chunk 2 + Column Metadata>
...
<Column N Chunk 2 + Column Metadata>
...
<Column 1 Chunk M + Column Metadata>
<Column 2 Chunk M + Column Metadata>
...
<Column N Chunk M + Column Metadata>
File Metadata
4-byte length in bytes of file metadata
4-byte magic number "PAR1"
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
magic number 就类似水印,***有整个文件的 Metadata。还是看图吧,Parquet 的官方文件格式图是下面这样的:
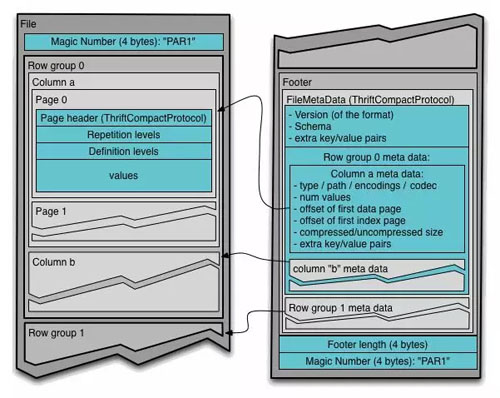
左边是数据,右边是 File Metadata。
如果觉得太复杂了,可以看我画的简洁版:
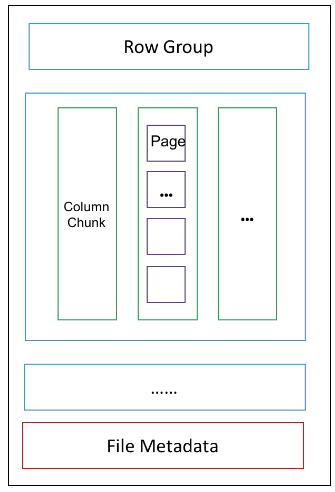
是不是清爽很多!File Metadata 中有对应的 Row Group Metadata,里面还有 Column Chunk Metadta,和数据的组织形式类似,就不展开画了。
Parquet 的接口就不介绍了,有兴趣的去吧:
https://github.com/apache/parquet-format
总结
列式存储文件格式到底有多列,取决于每列在内存中缓存的数据量,由于同一列的各个 Page 相互独立,如果每个 Page 只缓存一个数据点,就退化成行式存储了(比行式存储还差)。因此,列式存储有一个需要注意的就是列不能太多,这是个大坑。
跟我们之前介绍的文件格式比,Parquet 只是多了几层而已,只要掌握了文件格式的基本原理,各种文件格式都可以快速上手。