人工智能根据正脸生成多个侧脸,利用生成对抗网络生成多角度侧脸摘要:从单视图输入生成多视图图像是一个基本而又具有挑战性的问题。它在视觉,图形和机器人方面有广泛的应用。我们的研究表明,广泛使用的生成对抗网络(GAN)可能由于单路径框架而学习“不完整”表示:编码器 - 解码器网络,后面是鉴别器网络。我们提出CR-GAN来解决这个问题。除了单一的重构路径之外,我们还引入了一代代,以保持学习嵌入空间的完整性。这两种学习途径以参数共享的方式进行协作和竞争,从而显着提高了对“未见”数据集的泛化能力。更重要的是,双路径框架可以将标记和未标记数据结合起来进行自我监督学习,进一步丰富了实际世代的嵌入空间。实验结果证明CR-GAN明显优于最先进的方法,特别是在野外条件下从“看不见的”输入产生时。

人工智能根据正脸生成多个侧脸,利用生成对抗网络生成多角度侧脸简介:从单视图输入生成多视图图像是视觉,图形和机器人中广泛应用的一个有趣问题。然而,这是一个具有挑战性的问题,因为1)计算机需要“想象”在应用3D旋转后给定对象的样子; 2)多视图生成应该保留相同的“身份”。一般来说,此问题的先前解决方案包括模型驱动的综合[Blanz和Vetter,1999],数据驱动的生成[Zhu et al。,2014; Yan et al。,2016],以及两者的结合[Zhu et al。,2016; Rezende等,2016]。最近,生成对抗网络(GANs)[Goodfellow et al。,2014]在多视图生成中显示出令人印象深刻的结果[Tran et al。,2017;赵等人,2017]。
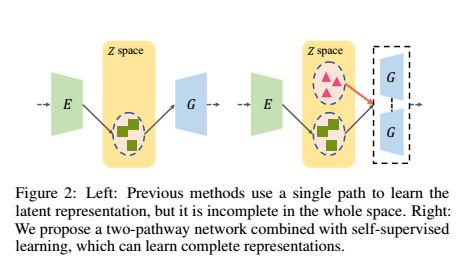
人工智能根据正脸生成多个侧脸,利用生成对抗网络生成多角度侧脸贡献:这些基于GAN的方法通常具有单路径设计:编码器 - 解码器网络之后是鉴别器网络。编码器(E)将输入图像映射到潜在空间(Z),其中嵌入首先被操纵然后被馈送到解码器(tt)以生成新颖的视图。然而,我们的实验表明,这种单通道设计可能存在严重的问题:它们只能学习“不完整”的表示,对“看不见”或无约束的数据产生有限的泛化能力。以图1为例。在训练期间,E的输出仅构成Z的子空间,因为我们通常具有有限数量的训练样本。这将使tt仅“看到”Z的一部分。在测试期间,E极有可能在子空间之外映射“看不见的”输入。结果,由于意外的嵌入,tt可能产生差的结果。
为了解决这个问题,我们建议CR-GAN学习多视图生成的完整表示。主要思想是,除了重建路径之外,我们引入另一代路径来从Z中随机采样的嵌入创建视图特定图像。请参考图2进行说明。这两条路径共享相同的tt。换句话说,在生成路径中学习的tt将指导重建路径中的E和D的学习,反之亦然。 E被迫成为tt的倒数,产生完整Z空间的完整表示。更重要的是,双路径学习可以很容易地利用标记和未标记的数据进行自我监督学习,这可以在很大程度上丰富自然世代的Z空间。总之,我们有以下贡献:
据我们所知,我们是第一个研究GAN模型的“完整表示”的人;我们建议使用双路径学习方案学习“完整”表示的CR-GAN;CR-GAN可以利用未标记的数据进行自我监督学习,从而提高生成质量;CR-GAN可以在野外条件下从甚至“看不见的”数据集生成高质量的多视图图像。

人工智能根据正脸生成多个侧脸,利用生成对抗网络生成多角度侧脸提出的方法:不完整表示的玩具示例,单路径网络,即跟随鉴别器网络的编码器 - 解码器网络,可能具有学习“不完整”表示的问题。如图2左侧所示,编码器E和解码器tt只能“触摸”Z的子空间,因为我们通常具有有限数量的训练数据。当使用“未见”数据作为输入时,这将导致测试中的严重问题。 E很可能将新的输入映射到子空间之外,这不可避免地导致穷人的世代,因为tt从未“看到”嵌入。玩具示例用于解释这一点。我们使用Multi-PIE [Gross et al。,2010]来训练单通路网络。如图1的顶部所示,只要输入图像被映射到学习的子空间,网络就可以在Multi-PIE(第一行)上生成逼真的结果。然而,当测试来自IJB-A [Klare等人,2015]的“看不见的”图像时,网络可能产生不令人满意的结果(第二行)。在这种情况下,新图像被映射到学习的子空间之外。
这个事实激励我们训练可以“覆盖”整个Z空间的E和tt,这样我们就可以学习完整的表示。我们通过引入单独的生成路径来实现这一目标,其中生成器专注于将整个Z空间映射到高质量图像。图2说明了单通路和双通路网络之间的比较。请参阅图3(d),了解我们的方法。
人工智能根据正脸生成多个侧脸,利用生成对抗网络生成多角度侧脸实验:CR-GAN的目标是在床上空间学习完整的表现形式。我们通过将双路架构与自我监督学习相结合来实现这一目标。我们进行实验以分别评估这两个贡献。然后我们将我们的CR-GAN与DR-GAN进行比较[Tran et al。,2017],显示了嵌入空间中的视觉结果和t-SNE可视化。我们还将CR-GAN和BiGAN与图像重建任务进行比较。
实验设置,数据集。我们在有和没有视图标签的数据集上评估CR-GAN。 Multi-PIE [Gross et al。,2010]是在受限环境下收集的标记数据集。我们使用了第一次会话的250个主题,其中包括60个内的9个姿势,20个照明和两个表达。前200个科目用于培训,其余50个用于测试。 300wLP [Zhu et al。,2016]通过面部剖析方法[Zhu et al。,2016]从300W增加[Sagonas et al。,2013],其中也包含视图标签。我们采用偏航角为60°到+ 60°的图像,并将它们分成9个间隔。

为了评估未标记的数据集,我们使用CelebA [Liu等人,2015年]和IJB-A [Klare等人,2015]。 CelebA包含大量具有不平衡视点分布的名人图像。因此,我们收集了72,000张图像的子集,其范围从60°到+ 60°。请注意,CelebA中图像的视图标签仅用于收集子集,而在培训过程中不使用视图或标识标签。我们还使用包含5,396个图像的IJB-A进行评估。该数据集具有挑战性,因为存在广泛的身份和姿势变化。
人工智能根据正脸生成多个侧脸,利用生成对抗网络生成多角度侧脸结论:在本文中,我们研究了GAN模型的学习“完整表示”。 我们建议CR-GAN使用双路径框架来实现目标。 我们的方法可以利用标记和未标记的数据进行自我监督学习,从而在野外条件下从甚至“看不见的”数据中产生高质量的多视图图像。