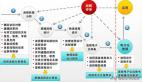
如何接手一个新业务的运维工作?有些东西我们还是要把话说在前面,以免前期不明确造成后期工作的混乱。
1、前期沟通
首先,我们要先跟研发Leader沟通,灌输运维理念,把丑话说在前头,我们不做保姆式运维,我们要致力于线上服务安全、稳定、低成本、快速迭代,从运维视角提高产品力。
开发机、测试环境,研发自己搞,我们可以协助帮忙,做专业的咨询服务,但不可能让我们直接操刀开发环境的变更。
2、业务概要了解
了解业务相关的人:对应的研发同学、研发Leader、测试同学、测试Leader、产品经理分别是谁,联系方式存下来,拉个群,出了问题可以找到对应的人。
了解服务是干什么的:解决了什么问题,业界有对标的开源产品吗……方便我们快速认识这个产品。
了解服务的上下游:依赖哪些服务、哪些服务依赖我、对应的接口人是谁……这里先简单了解一下即可。
了解服务部署情况:部署在哪些机房、用什么语言编写、基础网络、专线带宽、机房出口是否靠谱、是否曾因基础设施导致过问题,当前主要痛点是什么。
3、业务串讲
要求研发同学(或者上一任运维同学)准备PPT,做一个业务串讲,讲解一些研发同学希望传达给运维同学的信息,同事也讲解一些运维同学希望从研发这得到的信息。
比如:详细部署拓扑、服务整体架构、数据流、提测变更流程、监控方式、部署到了哪些机器、机器登录方式、每个机器上是什么模块、OS参数是否有调优,考量是什么、用到了哪些第三方软件,考量是什么,再比如为什么用了Tomcat而不是Resin、相关Wiki、故障处理预案、常见故障、当前线上问题……
如果业务有单点,不接,让研发改造。如果运维的老板的老板强制要求,丑话说前头:因单点导致的问题,运维不背锅。
4、资产梳理
正式准备接手前,第一步,梳理资产。
比如用到了哪些域名,这些域名对应哪些业务、哪些虚IP,分别是提供了什么服务、哪些机器,分别部署了什么模块、业务在哪些机房、用了多少带宽、总带宽情况、是否有其它业务共用争抢等。
机器需要拿到更详尽的信息,比如机器配置、机架位、IP、管理卡IP等等,公司应该有个CMDB供查询。如果没有,运维同学,需要你去构建这个CMDB。
后面要考虑机器是否需要有备机、备件,机型是否可以统一。
5、基础监控
知道有哪些资产了,就可以对这些资产做监控了,比如域名连通性监控/延迟监控、虚IP的连通性监控/延迟监控、机器宕机监控、机器硬件监控、sshd/crond等系统进程监控、系统运行的进程总数监控、系统参数配置监控。
6、服务梳理
吃透之前串讲时给的架构图、数据流图、部署拓扑图。从运维层面,最好还要知道公司网络拓扑图。
了解每个模块的情况,部署在哪些机器上、部署在哪个目录,用什么账号启动的、日志打到哪里了、用什么语言编写的、怎么上线的、主要吃CPU资源还是内存还是磁盘还是IO、需要预留多少资源、平时利用率是多少、应该配置多大的阈值做监控、是否需要watchdog自动拉起、日志里出现哪些关键字需要报警以及其他各种需要注意的问题。
7、业务监控
基本的进程、端口存活性监控,机器利用率监控、日志关键字监控、日志不滚动监控、关联的服务的监控等等,后面会做API粒度的监控,来推动业务优化。
8、标准化改造
机器命名方式、操作系统发行版、OS版本、第三方软件,比如JDK、Tomcat、Nginx,都要统一,要做标准化方案。
服务扩容、变更、下线做一键化,每次升级只需要给个版本号即可,此时研发操作还是运维操作效果一样,故而可以交给研发上线,释放运维人力,权限要控制好。
重复的常规操作也要固化成脚本,一键完成。
梳理故障自愈场景,看平时有哪些故障的处理方式是固定的,抽象为脚本,报警之后自动触发,无人值守处理。
公司如果有一些基础设施,比如名字服务、MQ、日志平台,推动研发改造,将新服务接入。如果公司还没有这些基础设施,作为运维这个角色,可以着手搞起。
9、SOP梳理
故障预案是一个非常重要的事情,线上没出故障之前,就应该提前去想,服务可能会出什么故障;如果真出了,应该如何处理,要把处理步骤提前记录下来。毕竟,线上出故障的时候,人都比较紧张,直接看着预案处理,就踏实不少,不容易出错。
10、故障演练
光有预案没有演练,是不靠谱的,没有经过验证的预案是不可信任的。所以,搞个放火演习,把模块搞挂试一把,把机器搞挂试一把,对线上稳定性绝对会有提升。
特别是研发说这个模块挂掉,可用性肯定没影响,OK,先搞挂试试,结果很可能会打他脸。
有些场景演练是会有损的。那这种场景还要不要演练?
这个需要case by case地看。大部分情况都是要做演练会更好,毕竟,人在这盯着的时候出问题,比晚上睡着了出问题要强太多。当然,大规模基础网络故障这种演练,还是算了吧,通常的业务都是不具备机房级容灾的。
上面做完了,基本工作就完成了。上面很多事情都是一次性的,那未来的大把时间运维做什么?
除了再花费部分时间做线上问题处理,我们应该把主要精力来提升业务产品力。做精细化运维,还记得运维九字真言么?“安全、稳定、高效、低成本”,这就是我们的工作方向。下面会举几个例子。
11、再谈业务监控
上面谈到过一次业务监控,主要是一些通用的监控指标。我们对产品了解足够之后,应该做一些业务特有的监控,推动研发去做也可以,达到效果就好。
比如你运维了一个MQ,消息堆积量是需要监控的;比如你运维了一个RPC服务,提供了三个接口,这三个接口的响应时长、成功率是需要监控的;再比如你运维了一个S3服务,每个桶的短期带宽增量你是需要监控的……
现在有那么点感觉了么?
12、API成功率、延迟统计
在流量入口的Nginx做所有业务线的所有API的成功率和延迟统计是非常有必要的。把成功率比较低的TopN找出来,把延迟比较大的TopN找出来,让业务去优化。老板会喜欢这个的。
13、线上问题梳理
整理线上所有问题,挨个解决,运维可以搞定的运维搞定,运维搞不定的找研发要排期,弄清楚每周解决了多少问题、还有多少问题待解决,用周报的方式体现出来。
14、成本优化
通过服务混部、或者统一的资源调度平台来节省机器资源,一台机器便宜的也要好几万,这个事是比较容易有产出的。
15、容量规划
容量规划和成本优化实际是紧密相关的,容量规划的重点是根据自然增量和运营需求,提前规划准备相应的容量。容量可能包括带宽、专线、网络设备、机器等等。当业务量下来的时候,可以腾挪相关资源支持其它业务线,让这些硬件尽量满负荷运转,物有所值。
业务精细化运维可以想出各种事情来搞,除了做这事,另一个需要长期投入的是构建运维基础平台,像监控系统、部署系统、产品库、资源利用率平台、域名管理、四七层接入配置平台、日志平台、Trace系统等等……
嗯,其实运维还是挺忙的。
16、关于沟通
最后说一点,接手一个新业务运维,势必与研发有各种沟通,每次沟通都要写会议纪要,发邮件出来,跟进人、时间点等都要写明白。
邮件发送双方团队邮件组,cc各方老大。事后关键节点做Check,如未完成,线下沟通,达成一致后追此邮件给结论,说明延期原因以及新的时间点。如果沟通不畅,让老大去协调。
我的看法基本就是这样,如果大家有其它的观点或是更好的建议,也欢迎在留言区一起交流。