背景
大数据时代,企业数据爆发式增长,如国内某企业平均每天有300亿笔业务,业务高峰期间每天可达600亿笔业务。随着数据的与日俱增,业务驱动下的数据分析灵活性要求越来越高,不同场景的数据分不同业务系统而构建,导致存储冗余严重,缺乏高效、统一的融合数据分析。
业界大数据分析方案,每种技术都只能解决某种场景下的诉求,不能同时满足多场景的应用,例如:MPP数据库,SQL语法支持好,小数据量下通过并行计算性能高,但支持万亿数据规模困难,不能有效与Hadoop生态集成,数据不能与其他大数据组件共享存储;搜索类技术提升了性能,但是数据膨胀很大,不支持标准的SQL,不兼容老业务。
Apache CarbonData是一种高性能大数据存储方案,与Hadoop、Spark等大数据生态组件无缝集成。针对当前大数据领域分析场景需求各异而导致的存储冗余问题,CarbonData提供了一种新的融合数据存储方案,以一份数据同时支持多种应用场景,并通过多级索引、字典编码、预聚合、动态Partition、准实时数据查询等特性提升了IO扫描和计算性能,实现万亿数据分析秒级响应。
1.架构原理

设计思路:
- 往下生态:与Hadoop HDFS(Hadoop是当前大数据生态的代名词)无缝集成,一个CarbonData文件就是一个HDFS数据块,充分利用HDFS的分布式,三份数据备份的可靠性等。
- 往上生态:与Spark做深度集成,充分利用Spark生态(当前业界***的计算引擎),支持标准SQL查询,Dataframe数据分析,支持机器学习等。随着CarbonData的用户越来越多,为了增强CarbonData的生态连接性,后续陆续支持了与Presto、Hive集成(Alpha特性)。
- 如何做到一份数据快速查询:利用多种索引(MDK,MinMax,倒排),快速找到目标数据,具体原理如下图:
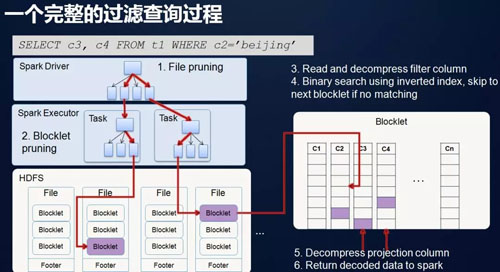
首先找到符合查询条件的CarbonData文件;如上图,***了2个文件,则启动两个Spark Task去读数据块(即 文件),在CarbonData文件里进一步细分成多个Blocklet,在Blocklet里又进一步细分成Page。
数据格式:
- 数据布局:
Block:一个hdfs文件,默认1G,可配置
Blocklet:文件内的列存数据块,是最小的IO读取单元
Column Chunk:在一个Blocklet中一列/列组的数据
Pages:Column Chunk内的数据页,是最小的解码单元
- 元数据信息:
Header:Version,Schema
Footer:BlockletOffset,Index & 文件级统计信息
- 内置索引和统计信息:
Blocklet索引:B Tree startKey, endKey
Blocklet级和Page级统计信息:min,max等
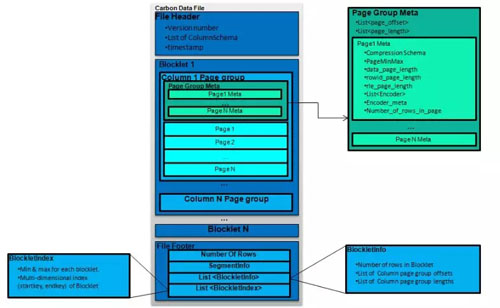
上图为CarbonData内部的文件格式,有File-header、有File-footer、有记录元数据中心,包括schema数据、偏移量数据等。我们重点看一下中间的Blocklet内容。Blocklet是数据文件内的一个列存数据块。Blocklet内部按列存储,比如说有column1_chunk、colume2_chunk,每一列数据又分为Page,Page是最小的解码单元。另外一个特点是除了元数据信息以外,还有索引信息。索引信息被统一存在File-footer内,它包括了Blocklet的索引,即主索引,它是一棵B树,里面包含了start_key和end_key之间的范围值。同时也包括 Blocklet级和Page级统计信息,这些统计信息是非常有用的,通过这些信息可以跳过 Blocklet和Page,避免不必要的 IO 和解码。
2.安装部署
CarbonData安装部署非常简单,可以参考社区文档:
https://github.com/apache/carbondata/blob/master/docs/quick-start-guide.md
https://github.com/apache/carbondata/blob/master/docs/installation-guide.md