昨天,技术圈又出一次重大技术故障。这一故障,直接导致了国内半个互联网瘫痪。
6 月 27 日,据网友反映,阿里云官网出现大规模访问异常,图片服务等产品无法正常使用,官网账号也无法登陆。
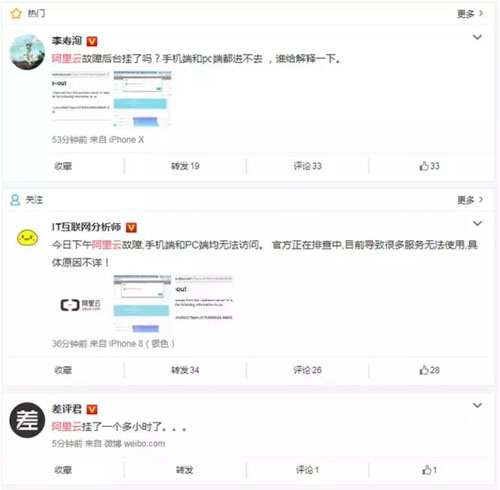
这次故障于北京时间 2018 年 6 月 27 日,16:21 左右开始,16:50 分开始陆续恢复。官方给出的故障时间大概持续 30 分钟,陆续恢复时间有一个小时多。

阿里云挂了,技术圈沸腾了,以下是各路网友的吐槽:
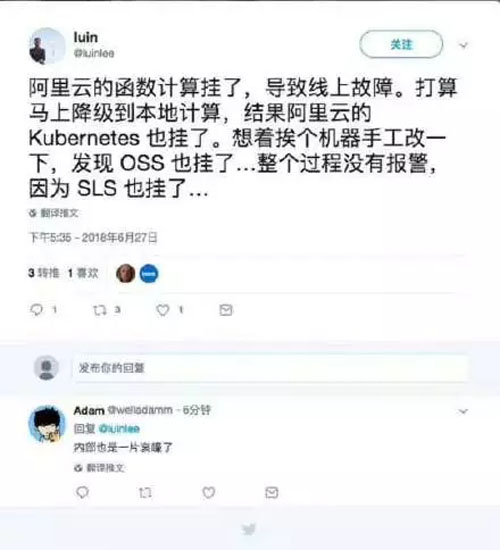
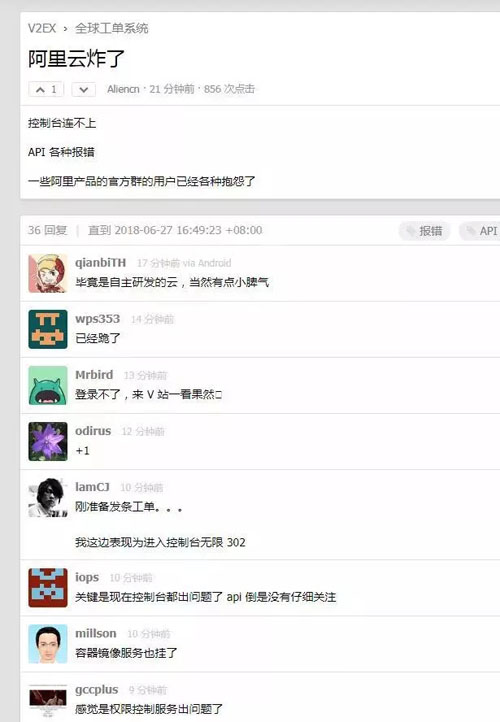

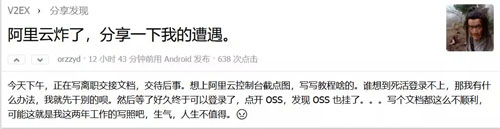
最怕就是在上线交差的时候出现了 Bug。

随后,阿里云正式发布通告称,于北京时间 2018 年 6 月 27 日 16:21 分左右,阿里云官网的部分管控功能,及 NAS、OSS 等产品的部分功能出现访问异常。阿里工程师正在紧急处理中。

在 6 月 27 日凌晨时分,阿里云给了官方说明,故障起因是上线一个自动化运维新功能时,执行了一项变更验证操作,触发了一个未知代码 Bug,错误代码禁用了部分内部 IP,导致部分产品访问链路不通。

阿里云称,“对于这次故障,没有借口,我们不能也不该出现这样的失误!我们将认真复盘改进自动化运维技术和发布验证流程,敬畏每一行代码,敬畏每一份托付。 ”
阿里云近年故障历史:
- 云盾升级触及 Bug 造成服务器大量文件被误隔离。正是因为这一低级错误,影响了大范围的用户,造成了用 top 进程、top 命令、apt-get 相继被灭。
- 阿里云北京机房内网故障引发大面积服务异常。
- 阿里云香港服务瘫痪 12 小时主要是因为机房建设方和运营商电力故障,阿里云直到电力故障发生近 12 个小时后才得以进入机房抢修。
昨日美国媒体报道,据美国市场研究机构 Synergy Research Group 的数据,今年***季度,阿里巴巴超越 IBM 成为全球第四大云基础设施及相关服务的提供商,落后于亚马逊、微软和谷歌。
阿里云故障,仅是运维操作失误?
对于昨日阿里云出现大范围故障,今天凌晨,阿里云官方微博公布了故障的原因,直接原因是由于"运维操作失误",改进措施是"复盘改进自动化运维技术和发布验证流程"。
能坦诚的公布问题,而不是用系统抖动或者光纤挖断之类的词来敷衍大家,这一点值得肯定。
除了公告提到的增强发布流程验证之外,重新审视系统整体的隔离保护体系我觉得也值得一做。故障的时间偏长,暴露了对突发问题处理手段及预案的匮乏。
一个不断演进的系统,出现问题不可避免,反复的强调或者追求不出问题未必是***的方向,让团队具备快速解决问题的能力通常来说更加可行。
出了问题后,只要有相应的手段来隔断问题的范围(类似大楼里面的防火门),减少对非故障模块的干扰,通常不会对用户整体造成干扰。
从昨天的情况来看,要么就没有防火门的设计,要么系统有类似的机制,但是处理人员不能熟练地启用。
如果是前者,则需要重新审视整体架构,如果是后者,那就是团队内部需要反思的问题。
写在***
每一次的故障确实不应该发生,但有时又难以避免。对此,不少网友表示,理解身为同行的程序员们,解决问题比解决人更重要。

但是也有不少人认为:
- 出了故障可以原谅,那客户的损失该如何算?
- 如果是没按规范操作导致的事故肯定是要处罚的,否则这次事故的复盘就是无价的经验啊。
- 技术人员肯定得背故障啊,但是这事应该要升级,不是说一个技术人或者开除就算了的。
注:部分素材来源于高可用架构,其他素材是互联网综合整理。