












除了常见的redis/memcache等进程外缓存服务,缓存还有一种常见的玩法,进程内缓存。
什么是进程内缓存?
答:将一些数据缓存在站点,或者服务的进程内,这就是进程内缓存。
进程内缓存的实现载体,最简单的,可以是一个带锁的Map。又或者,可以使用第三方库,例如leveldb。
进程内缓存能存储啥?
答:redis/memcache等进程外缓存服务能存什么,进程内缓存就能存什么。

如上图,可以存储json数据,可以存储html页面,可以存储对象。
进程内缓存有什么好处?
答:与没有缓存相比,进程内缓存的好处是,数据读取不再需要访问后端,例如数据库。
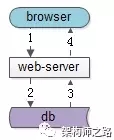
如上图,整个访问流程要经过1,2,3,4四个步骤。
如果引入进程内缓存,
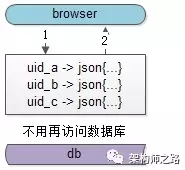
如上图,整个访问流程只要经过1,2两个步骤。
与进程外缓存相比(例如redis/memcache),进程内缓存省去了网络开销,所以一来节省了内网带宽,二来响应时延会更低。
进程内缓存有什么缺点?
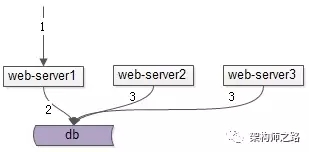
答:统一缓存服务虽然多一次网络交互,但仍是统一存储。
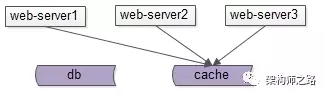
如上图,站点和服务中的多个节点访问统一的缓存服务,数据统一存储,容易保证数据的一致性。
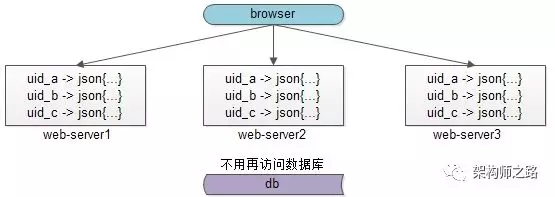
而进程内缓存,如上图,如果数据缓存在站点和服务的多个节点内,数据存了多份,一致性比较难保障。
如何保证进程内缓存的数据一致性?
答:保障进程内缓存一致性,有几种方案。
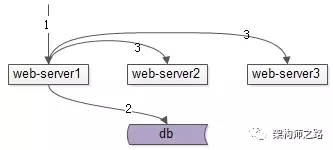
***种方案,可以通过单节点通知其他节点。如上图:写请求发生在server1,在修改完自己内存数据与数据库中的数据之后,可以主动通知其他server节点,也修改内存的数据。
这种方案的缺点是:同一功能的一个集群的多个节点,相互耦合在一起,特别是节点较多时,网状连接关系极其复杂。
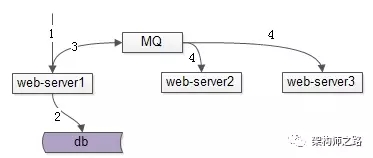
第二种方案,可以通过MQ通知其他节点。如上图,写请求发生在server1,在修改完自己内存数据与数据库中的数据之后,给MQ发布数据变化通知,其他server节点订阅MQ消息,也修改内存数据。
这种方案虽然解除了节点之间的耦合,但引入了MQ,使得系统更加复杂。
前两种方案,节点数量越多,数据冗余份数越多,数据同时更新的原子性越难保证,一致性也就越难保证。
第三种方案,为了避免耦合,降低复杂性,干脆放弃了“实时一致性”,每个节点启动一个timer,定时从后端拉取***的数据,更新内存缓存。在有节点更新后端数据,而其他节点通过timer更新数据之间,会读到脏数据。
为什么不能频繁使用进程内缓存?
答:分层架构设计,有一条准则:站点层、服务层要做到无数据无状态,这样才能任意的加节点水平扩展,数据和状态尽量存储到后端的数据存储服务,例如数据库服务或者缓存服务。
可以看到,站点与服务的进程内缓存,实际上违背了分层架构设计的无状态准则,故一般不推荐使用。
什么时候可以使用进程内缓存?
答:以下情况,可以考虑使用进程内缓存。
- 情况一,只读数据,可以考虑在进程启动时加载到内存。画外音:此时也可以把数据加载到redis / memcache,进程外缓存服务也能解决这类问题。
- 情况二,极其高并发的,如果透传后端压力极大的场景,可以考虑使用进程内缓存。例如,秒杀业务,并发量极高,需要站点层挡住流量,可以使用内存缓存。
- 情况三,一定程度上允许数据不一致业务。例如,有一些计数场景,运营场景,页面对数据一致性要求较低,可以考虑使用进程内页面缓存。
末了,再次强调,进程内缓存的适用场景并不如redis/memcache广泛,不要为了炫技而使用。
更多的时候,还是老老实实使用redis/mc吧。
画外音:额,介绍技术,不希望把大家带偏了。
【本文为51CTO专栏作者“58沈剑”原创稿件,转载请联系原作者】



















