2018 年世界杯小组赛已经在如火如荼的进行中。在上篇文章我用Python分析了4W场比赛,2018世界杯冠军竟然是……的基础上,我们继续分析世界杯 32 强的实力情况,以便能够更进一步分析本次世界杯的夺冠热门球队。
三十年河东三十年河西,对于世界杯而言,这个时间可能 4 年就足够。前几场爆冷,使得天台上已经拥挤不堪,跳水的股市更是让天台一度混乱。
在文章开始之前,提醒大家:赌球有风险,看球须尽兴。本文的重点是通过分析 32 强之间的比赛,透过历史数据来预测夺冠热门球队。
本次分析的数据来源于 Kaggle, 包含从 1872 年到今年的数据,包括世界杯比赛、世界杯预选赛、亚洲杯、欧洲杯、国家之间的友谊赛等比赛,一共大约 40000 场比赛的情况。
本次的环境为:
- Window 7 系统
- Python 3.6
- Jupyter Notebook
- pandas version 0.22.0
先来看看数据的情况:
- import pandas as pd
- import matplotlib.pyplot as plt
- %matplotlib inline
- plt.style.use('ggplot')
- # 解决matplotlib显示中文问题
- plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
- plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
- df = pd.read_csv('results.csv')
- df.head()
该数据集包含的数据列的信息如下:
- 日期
- 主队名称
- 客队名称
- 主队进球数 (不含点球)
- 客队进球数 (不含点球)
- 比赛的类型
- 比赛所在城市
- 比赛所在国家
- 是否中立
结果如下:
获取所有世界杯比赛的数据(含预选赛)
创建一个新的列数据,包含获胜队伍的信息,以及获取所有世界杯比赛的数据,包含预选赛。
- mask = df['home_score'] - df['away_score']
- df.loc[mask > 0, 'win_team'] = df.loc[mask > 0, 'home_team']
- df.loc[mask < 0, 'win_team'] = df.loc[mask < 0, 'away_team']
- df.loc[mask == 0, 'win_team'] = 'Draw'
- df_FIFA_all = df[df['tournament'].str.contains('FIFA', regex=True)]
结果如下:
世界杯战绩分析 (含预选赛)
从前文来看, 在世界杯历史上,实力最强的 5 支球队是德国、阿根廷、巴西、法国、西班牙。
接下来,我们将比赛的范围扩大至包含世界杯预选赛,通过 5 支球队之间的比赛情况来进行分析。
- team_top5 = ['Germany', 'Argentina', 'Brazil', 'France', 'Spain']
- df_FIFA_top5 = df_FIFA_all[(df_FIFA_all['home_team'].isin(team_top5))&
- (df_FIFA_all['away_team'].isin(team_top5))]
- df_FIFA_top5.shape
- out:
- (43, 10)
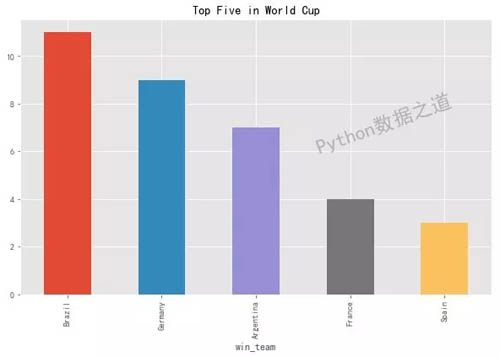
在世界杯历史上,5 支球队在共有 43 场比赛相遇。
通过这 43 场比赛分析后,5 支球队的胜负场数排名如下:
- s_FIFA_top5 = df_FIFA_top5.groupby('win_team')['win_team'].count()
- s_FIFA_top5.drop('Draw', inplace=True)
- s_FIFA_top5.sort_values(ascending=False, inplace=True)
- s_FIFA_top5.plot(kind='bar', figsize=(10,6), title='Top Five in World Cup')
结果如下:
下面,着重来分析下这 5 支球队,在世界杯上,两两对阵时的胜负情况。
首先自定义两个函数,分别获得两支球队获胜场数情况以及自定义绘图函数,代码如下:
- # 自定义函数,返回两支球队获胜场数情况
- def team_vs(df,team_A,team_B):
- df_team_A_B = df[(df['home_team'].isin([team_A,team_B]))&
- (df['away_team'].isin([team_A,team_B]))]
- s_win_team = df_team_A_B.groupby('win_team')['win_team'].count()
- return s_win_team
- # 如需获取本文源代码,请关注公众号“Python数据之道”,
- # 在公众号后台回复 “code” ,谢谢大家支持。
- # 自定义函数,两支球队在世界杯的对阵胜负情况制图
- def team_vs_plot(df,team_A,team_B,ax):
- s_win_FIFA = team_vs(df,team_A,team_B)
- title = team_A + ' vs ' +team_B
- s_win_FIFA.plot(kind='bar', ax =ax)
- ax.set_xlabel('')
- ax.set_title(title,fontdict={'fontsize':10})
- ax.set_xticklabels(s_win_FIFA.index, rotation=20)
基于上述函数,分析世界杯战绩的结果如下:
巴西 vs 其他 4 支球队
- f, axes = plt.subplots(figsize=(10,10), ncols=2, nrows=2)
- ax1, ax2,ax3,ax4 = axes.ravel()
- team_vs_plot(df_FIFA_all,'Brazil','Germany',ax=ax1)
- team_vs_plot(df_FIFA_all,'Brazil','Argentina',ax=ax2)
- team_vs_plot(df_FIFA_all,'Brazil','France',ax=ax3)
- team_vs_plot(df_FIFA_all,'Brazil','Spain',ax=ax4)
- # 如需获取本文源代码,请关注公众号“Python数据之道”,
- # 在公众号后台回复 “code” ,谢谢大家支持。
- # set main title of the figure
- plt.suptitle('Brazil vs other Top 4 teams in World Cup', fontsize=14, fontweight='bold', x=0.5, y=0.94)
- plt.show()
结果如下:
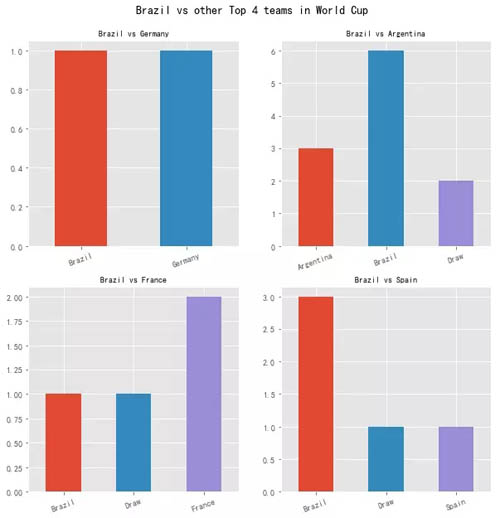
统计现象 1:
在世界杯上的战绩,统计获胜场数如下(不含平局):
巴西 1:1 德国,巴西 6:3 阿根廷,巴西 1:2 法国,巴西 3:1 西班牙
巴西队,输赢不好判断……
德国 vs 其他 3 支球队
代码跟 2.1 部分是类似的,结果如下:
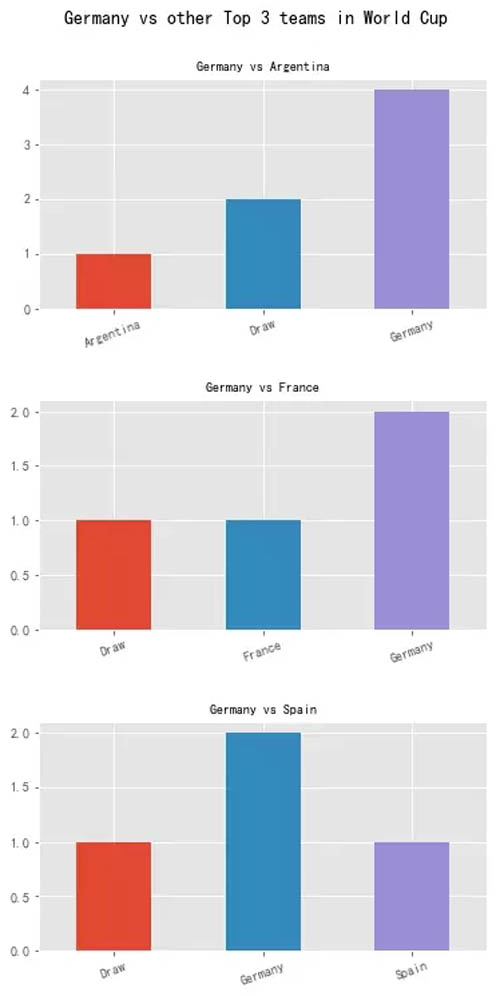
统计现象 2:
在世界杯上的战绩,统计获胜场数如下(不含平局):
德国 4:1 阿根廷,德国 2:1 法国,德国 2:1 西班牙
德国在这 5 支球队里,获胜的优势相对比较明显。
阿根廷 vs 其他 2 支球队
代码跟 2.1 部分是类似的,结果如下:
统计现象3:
在世界杯上的战绩,统计获胜场数如下(不含平局):
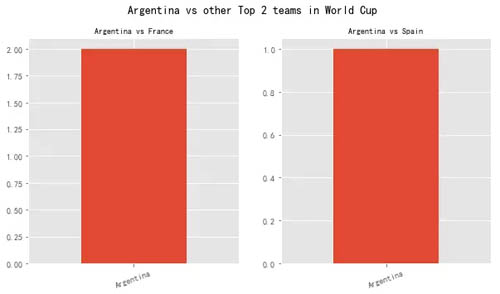
阿根廷 2:0 法国,阿根廷 1:0 西班牙
但阿根廷不敌巴西和德国
西班牙 vs 法国
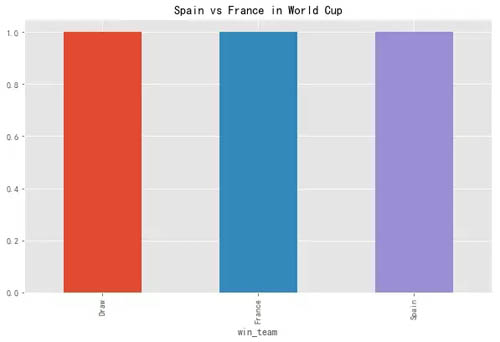
综合小结论:从历届世界杯上的表现情况来看,分析 5 强之间两两对阵后,发现德国队的表现是最好的,其次巴西和阿根廷的表现也不错。
考虑到,历届世界杯的数据,时间跨度很大,很多球队已经发生了很大变化。
球队真实的情况,可能选择近几年的比赛,以及包含不同级别的比赛,可能分析效果要更好些。
下面,重点来分析 2014 年以来包含所有比赛的情况。
2014 年以来,所有比赛的战绩对比
首先,时间选择 2014 年之后(含 2014 年),距离现在的时间比较近,相对来说,球队人员的组成变化小一些。
当然,这里的时间选择,对于结果是有影响的。 大家可以探讨下这个因素带来的影响。
2014 年以来所有球队所有比赛胜负情况概览:
- df['date'] = pd.to_datetime(df['date'])
- df['year'] = df['date'].dt.year
- df_since_2014 = df[df['year']>=2014]
- df_since_2014.shape
2014 年以来,共有 3600 多场比赛。针对 3600 多场比赛分析后,胜负场数情况如下:
- s_all = df_since_2014.groupby('win_team')['win_team'].count()
- s_all.drop('Draw', inplace=True)
- s_all.sort_values(ascending=True, inplace=True)
- s_all.tail(50).plot(kind='barh', figsize=(8,16), tick_label='',title='Top 50 in all tournament since 2014')
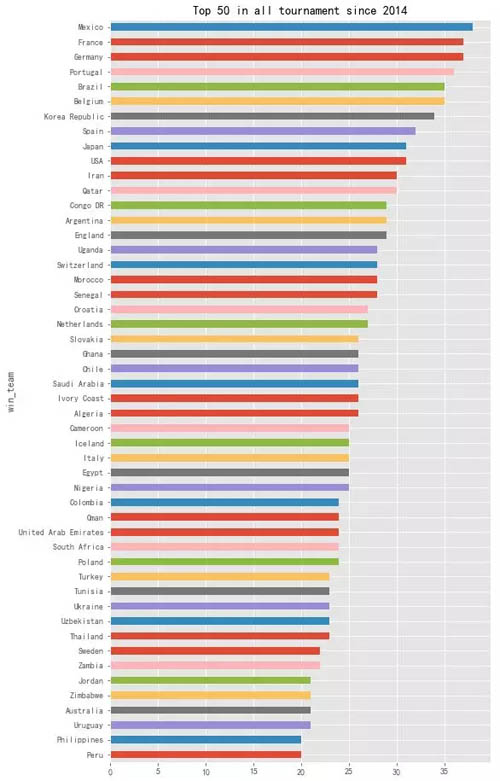
从上图来看,2014 年以来,墨西哥,法国,德国、葡萄牙、巴西、比利时、韩国和西班牙表现相对较好。
结果是不是跟想象中的有些差异?6 月 17 日的小组赛,德国不敌墨西哥,看来也不是全无理由的。
但是,本次我们主要还是要考虑 32 强之间的对阵,这样更能反映现实情况。
2014 年以来 32 强相互之间在所有比赛中的概览情况:
- team_list = ['Russia', 'Germany', 'Brazil', 'Portugal', 'Argentina', 'Belgium', 'Poland', 'France',
- 'Spain', 'Peru', 'Switzerland', 'England', 'Colombia', 'Mexico', 'Uruguay', 'Croatia',
- 'Denmark', 'Iceland', 'Costa Rica', 'Sweden', 'Tunisia', 'Egypt', 'Senegal', 'Iran',
- 'Serbia', 'Nigeria', 'Australia', 'Japan', 'Morocco', 'Panama', 'Korea Republic', 'Saudi Arabia']
- df_top32 = df_since_2014[(df_since_2014['home_team'].isin(team_list))&(df_since_2014['away_team'].isin(team_list))]
- s_top32 = df_top32.groupby('win_team')['win_team'].count()
- s_top32.drop('Draw', inplace=True)
- s_top32.sort_values(ascending=True, inplace=True)
- s_top32.plot(kind='barh', figsize=(8,12), tick_label='',title='Top 32 in all tournament since 2014')
- # plt.ylabel('')
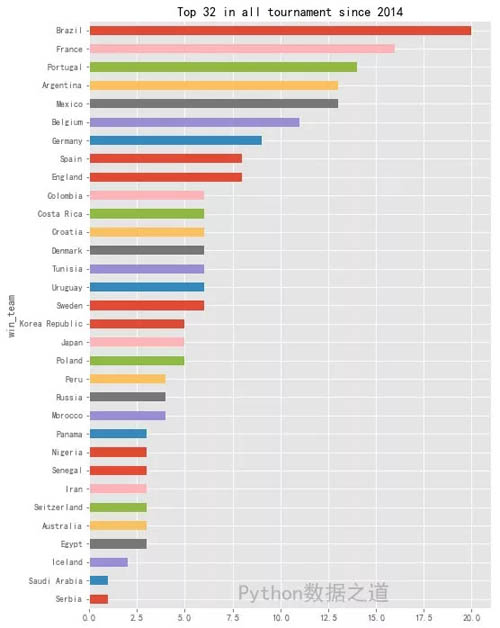
从上图来看,自 2014 年以来,巴西、法国、葡萄牙、阿根廷、墨西哥、比利时、德国、西班牙、英国为前 9 强。
下面我们来分析 Top 9 之间的胜负情况:
- team_top9 = [ 'Brazil', 'France', 'Portugal',
- 'Argentina','Mexico','Belgium',
- 'Germany','Spain','England']
- df_top9 = df_since_2014[(df_since_2014['home_team'].isin(team_top9))&
- (df_since_2014['away_team'].isin(team_top9))]
- df_top9.shape
2014 年以来,Top 9 之间一共踢了 44 场比赛(包括友谊赛)。
总体来说,比赛的场数不是太多,基于这些数据来分析,可能对结果会有较大的影响。
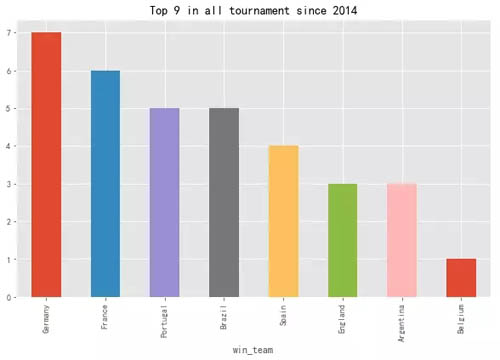
九强排名如下:
- s_top9 = df_top9.groupby('win_team')['win_team'].count()
- s_top9.drop('Draw', inplace=True)
- s_top9.sort_values(ascending=False, inplace=True)
- s_top9.plot(kind='bar', figsize=(10,6), title='Top 9 in all tournament since 2014')
来查看下都统计了哪些类型的比赛:
- s_tournament = df_top9.groupby('tournament')['tournament'].count()
- s_tournament_percentage = s_tournament/s_tournament.sum()
- # s_tournament_percentage.sort_values(ascending=False, inplace=True)
- s_tournament_percentage.tail(20).plot(kind='pie', figsize=(10,10), autopct='%.1f%%',
- startangle=150, title='percentage of tournament', label='',
- labeldistance=1.25, pctdistance=1.08)
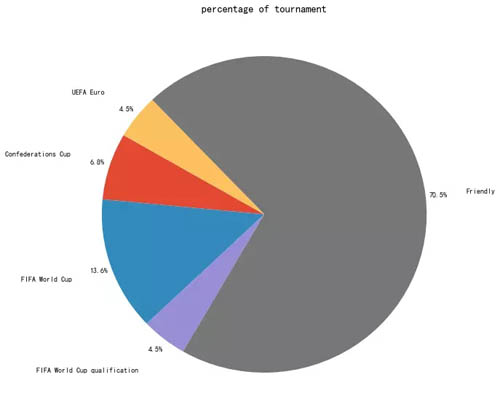
从上面来看,友谊赛占的比例较大。考虑到友谊赛在有些情况下可能不能比较准确的反映出球队的真实水平,且友谊赛占的场数比例较大,我们剔除友谊赛再来看看结果情况。
2014 年以来 32 强剔除友谊赛后的胜负情况概览:
- df_top9_no_friendly = df_top9[df_top9['tournament']!= 'Friendly']
- df_top9_no_friendly.groupby('tournament')['tournament'].count()
- out:
- tournament
- Confederations Cup 3
- FIFA World Cup 6
- FIFA World Cup qualification 2
- UEFA Euro 2
- Name: tournament, dtype: int64
剔除友谊赛后,比赛类型分布如下:
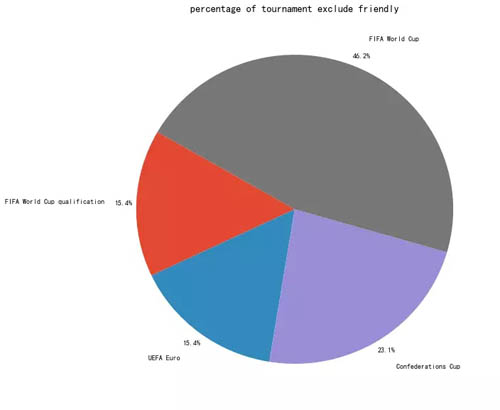
剔除友谊赛后,Top 9 的情况如下:

在概览中可以看出,是否剔除友谊赛(Friendly),对排名还是有影响的。
另外,剔除友谊赛后,总的比赛场数更少了(只有 13 场),9 强之间有些队伍没有比赛,或者没有赢过,这个数据用来分析的作用更有限。
当然,在分析中 是否要剔除友谊赛,应该是值得商榷的。
九强两两对阵的胜负情况概览
这里,我们后续分析采用包含友谊赛的数据,来分别分析9强之间两两对阵的情况,看看哪支球队的胜率更高些。
首先自定义几个函数,方便进行分析。自定义获取球队某年至今获胜比例函数:
- # 自定义获取球队某年至今获胜比例函数
- def probability(df,year,team_A,team_B):
- prob = []
- df_year = df[df['year']>= year]
- s = team_vs(df_year,team_A,team_B)
- s_team_A = 0 if s.get(team_A) is None else s.get(team_A)
- s_A_win = s_team_A/s.sum()
- s_team_B = 0 if s.get(team_B) is None else s.get(team_B)
- s_B_win = s_team_B/s.sum()
- s_draw = 1 - s_A_win - s_B_win
- prob.append(year)
- prob.append(s_A_win)
- prob.append(s_B_win)
- prob.append(s_draw)
- return prob
自定义获取两支球队历史获胜情况对比函数:
- # 自定义获取两支球队历史获胜情况对比函数
- def his_team_data(df,year_start,year_end,team_A,team_B):
- row_team = []
- # df_team = pd.DataFrame(columns=('year', 'team_A_win', 'team_B_win', 'draw'))
- for yr in list(range(year_start,year_end+1)):
- team_A_vs_team_B = probability(df,yr,team_A,team_B)
- row_team.append(team_A_vs_team_B)
- team_A_win = team_A + '_win_percentage'
- team_B_win = team_B + '_win_percentage'
- df_team = pd.DataFrame(row_team, columns=('year', team_A_win, team_B_win, 'draw_percentage'))
- return df_team
自定义两支球队历史获胜情况制图函数:
- # 自定义两支球队历史获胜情况制图函数
- def team_plot(df,year_start,year_end,team_A,team_B,ax):
- team_A_vs_team_B = team_A + '_vs_' + team_B
- team_A_vs_team_B = his_team_data(df,year_start,year_end,team_A,team_B)
- title = team_A + ' vs ' + team_B
- columns = [team_A+'_win_percentage',team_B+'_win_percentage','draw_percentage']
- team_A_vs_team_B.set_index('year')[columns].plot(kind='line',figsize=(10,6), title=title,ax=ax)
这些函数有什么用呢,首先我们来分析下巴西 vs 德国的情况,如下:
- team_A = 'Brazil'
- team_B = 'Germany'
- f, axes = plt.subplots(figsize=(6,12), ncols=1, nrows=2)
- ax1, ax2 = axes.ravel()
- team_plot(df,1930,2016,team_A,team_B,ax1)
- ax1.set_xlabel('')
- team_plot(df,2000,2016,team_A,team_B,ax2)
- ax2.set_title('')
- plt.show()
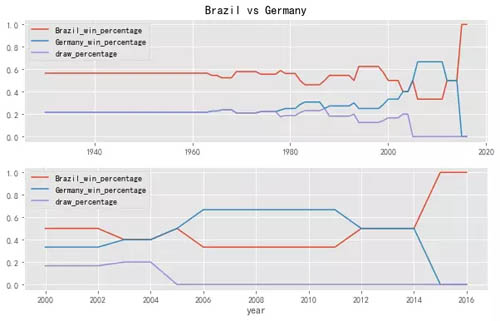
上述图中,x 轴代表的含义是从某年至今(数据集含有部分 2018 年的比赛数据),两支球队的胜负情况。
例如 2012 对应的是德国跟巴西从 2012 年至今,两支球队的胜负情况。所以,时间越早,两支球队的比赛数量越多,数据曲线的波动可能要小些。
但由于球队的成员组成在不断的变化,会导致越早的数据,其分析价值越弱。 因此,选择合适的年份进行分析就显得很重要。
有童鞋说,如果我要同时分析德国对阵另外 8 支球队呢?
这里,用上面的函数,也是很迅速的,代码如下:
- team_A = 'Germany'
- for team in ['France','Portugal', 'Argentina','Mexico','Belgium','Brazil','Spain','England']:
- team_B = team
- f, axes = plt.subplots(figsize=(6,12), ncols=1, nrows=2)
- ax1, ax2 = axes.ravel()
- team_plot(df,1930,2016,team_A,team_B,ax1)
- ax1.set_xlabel('')
- team_plot(df,2000,2016,team_A,team_B,ax2)
- ax2.set_title('')
- plt.show()
运行上述代码后,将会绘制 8 张图,下面只放上其中几张图。
同理,如果你喜欢巴西队或者别的球队,也可以用上述代码进行分析。
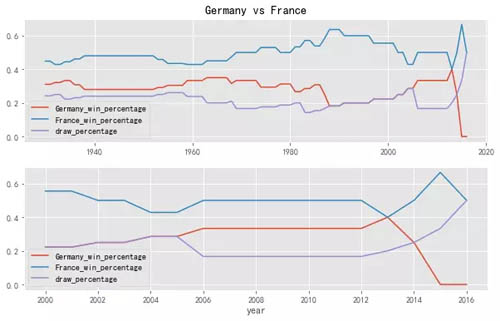
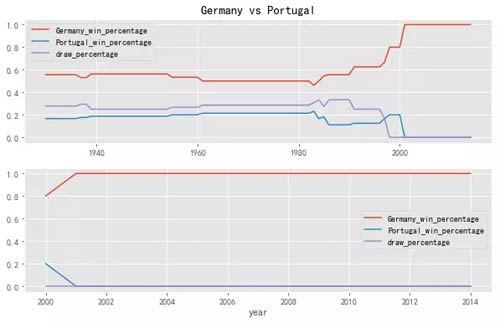
用上述函数可以快速的分析两支球队的历史胜负情况,当然,有些球队之间,相遇很少,或者近些年没有遭遇过,那分析结果可能就不好用了。
当然,数据分析的只是历史情况,足球是圆的,场上瞬息万变。比如,阿根廷现在岌岌可危,梅西内心慌得一比……
预测
本届世界杯真的是爆冷太多:
- 意大利,荷兰,连小组赛都没进
- 阿根廷,可以说现在已凉了半截
- 德国队,若不是最后的绝杀,也差不多可以送首凉凉了,不过现在看已回血大半
最后,来放上我的神预测。黑马年年有,今年特别多,预测不准,坐等 pia pia 打脸。
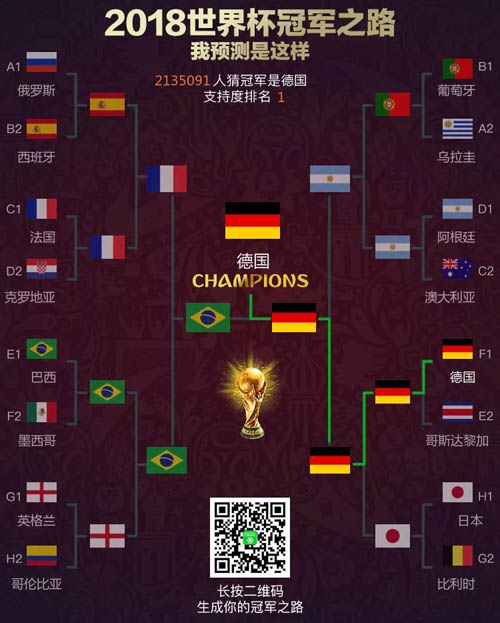
当然,其实我内心深处希望是下面这样的。怎么样,为强大的内心点赞吧~~
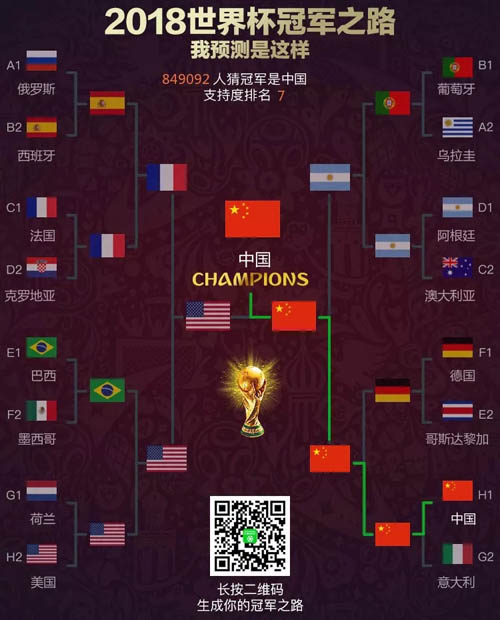
特别说明: 以上数据分析,纯属个人学习用,预测结果与实际情况可能偏差很大,不能用于其他用途。