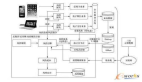
其实大数据并不是一种概念,而是一种方法论。简单来说,就是通过分析和挖掘全量的非抽样的数据辅助决策。大数据可以实现的应用可以概括为两个方向,一个是精准化定制,第二个是预测。比如像通过搜索引擎搜索同样的内容,每个人的结果却是大不相同的。再比如精准营销、百度的推广、淘宝的喜欢推荐,或者你到了一个地方,自动给你推荐周边的消费设施等等。
目前市场对大数据相关人才的需求与日俱增,岗位的增多,也导致了大数据相关人才出现了供不应求的状况,从而引发了一波大数据学习的浪潮。大家可以先了解一下关于大数据相关的岗位分类,以及各个岗位需要掌握那些相对应的技能,并想清楚自己未来的发展方向,再开始着手针对岗位所需的技术进行学习与研究。所谓知己知彼,才能更好的达成目标嘛。
大数据处理技术怎么学习呢?在做大数据开发之前,因为Hadoop是高层次的语言开发,需要懂得Java或者Python,很快的就能上手。所有的大数据生态架构都是基于linux系统的基础上的,所以你要有Linux系统的基本知识。如果你不懂Java或者Python还有Linux系统,那么这都是你必学的知识(Java或者Python可二选其一)。
***阶段
Linux系统:因为大数据相关软件都是在Linux系统上运行的,所以Linux要学习的扎实一些,学好Linux对你快速掌握大数据相关技术会有很大的帮助,能让你更好的理解hadoop、hive、hbase、spark等大数据软件的运行环境和网络环境配置,能少踩很多坑,学会shell就能看懂脚本这样能更容易理解和配置大数据集群。还能让你对以后新出的大数据技术学习起来更快。
鸟哥的Linux私房菜 是一本公认的Linux的入门书籍。
第二阶段
Python:Python 的排名从去年开始就借着人工智能持续上升,现在它已经成为了语言排行***名。
从学习难易度来看,作为一个为“优雅”而生的语言,Python语法简捷而清晰,对底层做了很好的封装,是一种很容易上手的高级语言。在一些习惯于底层程序开发的“硬核”程序员眼里,Python简直就是一种“伪代码”。
在大数据和数据科学领域,Python几乎是***的,任何集群架构软件都支持Python,Python也有很丰富的数据科学库,所以Python不得不学。
第三阶段
Hadoop:几乎已经成为大数据的代名词,所以这个是必学的。 Hadoop里面包括几个重要组件HDFS、MapReduce和YARN。
Hadoop的核心就是HDFS和MapReduce,而两者只是理论基础,不是具体可使用的高级应用,通俗说MapReduce是一套从海量源数据提取分析元素***返回结果集的编程模型,将文件分布式存储到硬盘是***步,而从海量数据中提取分析我们需要的内容就是MapReduce做的事了。当然怎么分块分析,怎么做Reduce操作非常复杂,Hadoop已经提供了数据分析的实现,我们只需要编写简单的需求命令即可达成我们想要的数据。
记住学到这里可以作为你学大数据的一个节点。
Zookeeper:是一个分布式的,开放源码的分布式应用程序协调服务,也是个万金油,安装Hadoop的HA的时候就会用到它,以后的Hbase也会用到它。它一般用来存放一些相互协作的信息,这些信息比较小一般不会超过1M,都是使用它的软件对它有依赖,对于我们来讲只需要把它安装正确,让它正常的跑起来就可以了。
Mysql:大数据的处理学完了,那么接下来要学习小数据的处理工具Mysql数据库,因为装hive的时候要用到,Mysql需要掌握到什么层度呢?你能在Linux上把它安装好,运行起来,会配置简单的权限,修改root的密码,创建数据库就可以了。这里主要的是学习SQL的语法,因为hive的语法和这个非常相似。
Sqoop:这个是用于把Mysql里的数据导入到Hadoop里的。当然你也可以直接把Mysql数据表导出成文件再放到HDFS上也是可以的,但是生产环境中使用要注意Mysql的压力。
Hive:这个东西对于会SQL语法的同学们来说就是神器,它能让你处理大数据变的很简单、明了,不会再费劲的编写MapReduce程序。有的人说Pig那?它和Pig相似掌握一个就可以了。
Oozie:既然学会Hive了,我相信你一定需要这个,它可以帮你管理你的Hive或者MapReduce、Spark脚本,还能检查你的程序是否执行正确,如果出错给你发出报警并能帮你重试程序,最重要的是还能帮你配置任务的依赖关系。我相信你一定会喜欢它的,不然你看着那一大堆脚本,和密密麻麻的crond是不是有种“即将崩溃”的感觉。
Hbase:这是Hadoop生态体系中的NOSQL数据库,他的数据是按照key和value的形式存储的并且key是唯一的,所以它能用来做数据的排重,它与MYSQL相比能存储的数据量大很多。所以他常被用于大数据处理完成之后的存储目的地。
Kafka:这是个比较好用的队列工具,队列是干什么的?排队买票你知道不?数据多了同样也需要排队处理,我们可以利用这个工具来做线上实时数据的入库或入HDFS,这时你可以与一个叫Flume的工具配合使用,它是专门用来提供对数据进行简单处理,并写到各种数据接受方的。
Spark:它是用来弥补基于MapReduce处理数据速度上的缺点,它的特点是把数据装载到内存中计算而不是去读硬盘。特别适合做迭代运算,所以算法流们特别喜欢它。它是用scala编写的。Java语言或者Scala都可以操作它,因为它们都是用JVM的。
这些东西你都会了就成为一个专业的大数据开发工程师了,月薪3W都是毛毛雨啦。
后续提高
大数据结合人工智能达到真正的数据科学家,打通了数据科学的任督二脉,在公司是技术专家级别,这时候月薪再次翻倍且成为公司核心骨干。
机器学习:是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。机器学习的算法基本比较固定了,学习起来相对容易。
深度学习:深度学习的概念源于人工神经网络的研究,最近几年发展迅猛。深度学习应用的实例有AlphaGo、人脸识别、图像检测等。是国内外稀缺人才,但是深度学习相对比较难,算法更新也比较快,需要跟随有经验的老师学习。
最快的学习方法,就是师从行业专家,学习老师多年积累的经验,自己少走弯路达到事半功倍的效果。自古以来,名师出高徒。