【51CTO.com原创稿件】从单体程序到微服务,再到当下流行的服务网格概念,Spring 连接起了这两个时代。它曾是单体程序的代名词,但是却在微服务时代浴火重生,给我们带来了 Spring Cloud。
借助于 Spring Cloud,苏宁大数据中心完成了微服务架构转型,在实践中并不是一帆风顺,有思索、有迷茫,更有解决问题的乐趣。
为什么要微服务化?
为什么是 Spring Cloud?

苏宁数据中台后端是传统的开发架构, VIP 负载均衡 + Nginx + SpringMVC,代码以单体程序为主。
正常情况下一个项目使用统一域名,在苏宁现有开发架构下,统一域名导致后端只能有一个 war 包,程序变成单体程序变成必然。
如下图所示是典型的旧式项目代码目录:
- 项目名称-web:对外 war 包模块
- 项目名称-interface:统一定义接口
- 项目名称-service:统一定义接口实现
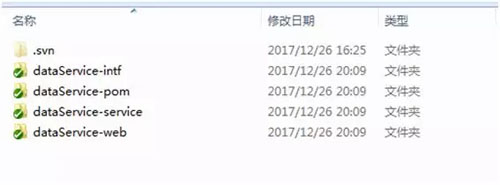
整个项目管理、开发思路,围绕单体程序开发模型设计,带来的弊端很明显:
- 代码职责不清晰,每个人都在同一模块下提交代码
- 违反高内聚低耦合
- 服务扩展不方便
首先微服务化思路,并不高大上,我们为什么选择微服务化,首要原因是管理问题。
结合苏宁现有开发架构,整个微服务架构如图:域名解析 + VIP 负载均衡 + Nginx + 服务网关 + 各个服务。
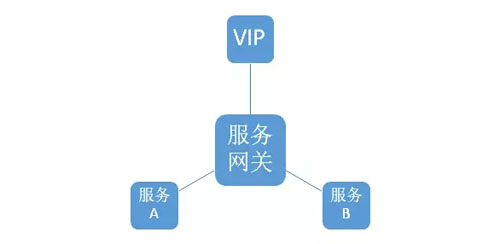
下图是某个项目采用微服务化后的工程代码目录:
- 项目名称-模块1
- 项目名称-模块2

整个代码目录更清晰,利于模块拆分、人员职责安排。
数据中台项目背景介绍

苏宁数据中台是一个大项目群:
- OLAP 是底层的加速、查询引擎,底层支持 Druid、ES、PGCitus 集群,类似 Presto,跟 Presto 不同的是 OLAP 会主动对数据进行 Cube 预加速。
- 百川是指标平台层,让用户建模、定义指标,对外提供指标查询服务。百川主要支持的建模方式是:星型模型。
- 数据建模自然离不开维表维度,UDMS 系统就是来定义、管理所有维度、维表,目前收录了整个集团近 200 多个维度,对外提供维度、维表信息服务。
- 天工是类似 Tableau、Superset 的可视化报表设计平台,与这些 BI 软件***的不同点是,天工基于百川的指标、UDMS 的维度来制作报表,数据来源已经高度标准化、归一化。
目前商业报告分析工具:Cognos、阿里 QuickBI 等,是将数据建模、可视化设计能力放到一起,这是天工与它们的***区别。
- 慧眼,是统一报表门户,所有的报表统一发布到慧眼面向业务。慧眼***的挑战在于报表权限管控与自动匹配,总共 4000 多张报表,用户 2w 多,一张报表开放给8000+人员是很常见的。
所有这一切靠人工维护,既容易出错又不利于数据安全,也不能及时响应用户需求,这些都是慧眼系统要解决的问题。
微服务框架选型
Dubbo 架构介绍
Dubbo 主要有四个模块:
- Monitor(监控)
- Regsitry(注册中心)
- Provider(服务方)
- Consumer(消费方)
Provider 注册服务到 Regsitry,Consumer 向 Regsitry 订阅服务信息,Monitor服务监控服务调用情况。
整个服务调用流程如下:
- 消费方在本地发起服务调用
- 动态代理将调用交给 Loadbalance 模块
- Loadbalance 从 Registry 拿到服务实例信息
- 将请求发送到一台服务实例
- 记录监控日志等信息

Spring Cloud 架构介绍
Spring Cloud 整个架构与 Dubbo 非常类似:
- Eureka(注册中心)
- Gateway(服务网关)
- Provider(服务方)
- Consumer(消费方)
- Zipkin(监控)
不同的有如下几点:
- Spring Cloud 是 Http Rest 接口,Dubbo 不是。
- Spring Cloud 注册中心不使用 Zookeeper,使用自研的 Eureka。
关于 Zookeeper 是否适合做注册中心,请参考文章:《Eureka! Why You Shouldn’t Use ZooKeeper for Service Discovery》、《阿里巴巴为什么不用 ZooKeeper 做服务发现》
- Spring Cloud 提供了 Gateway 网关组件。
- 与 Spring 生态兼容,生态链丰富,自定义 Filter、拦截器,来加强功能, 如:权限校验、日志打印等;Spring Cloud Netflix 提供了熔断、限流等组件。
综合以上几点,考虑到架构统一,未来发展趋势,我们选择了 Spring Cloud。
Spring Cloud 主要帮助我们做系统内部服务化,REST 接口形式,不会破坏现有服务,前端服务调用无需做任何调整。
选择 Spring Cloud 还有一个重要原因是 Dubbo 与苏宁 RSF 服务框架高度重合,在对外服务接口上,我们还是以 RSF 接口为主。
基于 Spring Cloud 的服务化实践
整体架构介绍
整体有几个组件:注册中心、服务网关、服务监控、负载均衡器。注册中心使用 Spring Cloud 提供的 Eureka,服务网关使用 Spring Cloud 提供的 Zuul 组件,负载均衡器使用 Ribbon 组件。
服务网关的负载均衡策略选择的是:WeightedResponseTimeRule,根据服务器响应时间来决定路由到哪个节点。
服务监控组件,用来监控服务性能、调用情况,最重要的一点,是将整个服务链路能串联起来。

服务监控设计
监控是一个系统的眼睛,是断然不可缺少的一部分,Zipkin 提供了很好的服务链路监控,结合我们自身的使用场景,最终我们没有选择 Zipkin,为什么?
首先了解下 Zipkin 整体架构:
- 数据采集(Brave、Sleuth)
- Tranport 数据传输(支持 Kafka、直接发送 Collector)
- Collector(数据收集)
- Storage(存储:ES)
- Search + Webui(监控展示)
整体架构如下图所示,Zipkin 监控数据格式如下:
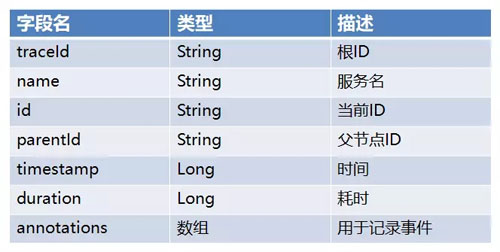
Zipkin 有如下缺点:
- 我们不止是监控 Spring Cloud 服务调用,如:苏宁 RSF 服务调用、SQL 的执行时间、本地方法执行时间等。
- 监控数据格式不满足业务需要。
- Collector 节点容易出现性能瓶颈,ES 聚合查询性能较差。
- 跨线程,链路无法串联。
基于以上几点,我们决定自研服务链路监控系统,整个系统架构如下,我们利用 Kafka、Druid,原则上提供了***扩展性。
Druid 对应 Zipkin 中的角色:Collector(数据收集) + Storage(存储:ES)。
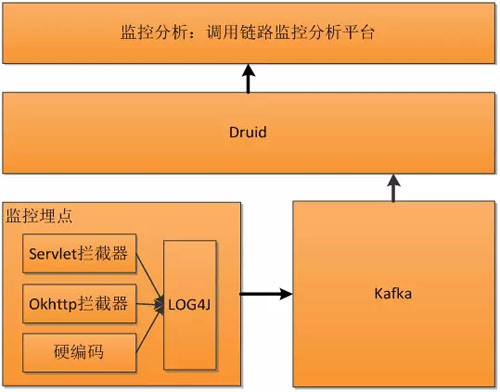
我们结合业务的需要,设计了监控日志格式,如下图所示:

一条调用链路,有相同的根 ID,服务名由三部分组成:
- 系统名
- 一级名称
- 二级名称
一级名称有 7 种值:
- url:http 接口
- url-call:调用 http 接口
- rs:rsf 接口
- rsf-call:调用 rsf 接口
- sql:执行 sql
- cache:操作缓存
- method:本地方法
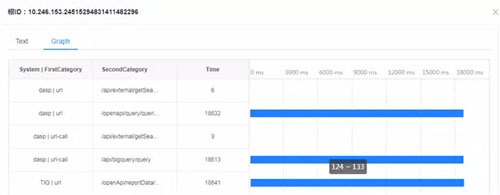
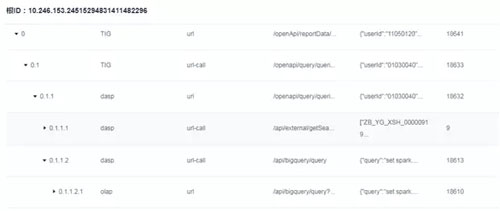
你可能会问,没有存储父 ID,如何判断一条链路中的父子关系?这里我们设计一个特殊的事务 ID 生成规则,通过事务 ID 本身即能判断父子关系,如下图所示:

下图监控系统的链路展示页面:
基于 Hystrix 的熔断设计
Hystrix 对应的中文名字是“豪猪”,豪猪周身长满了刺,能保护自己不受天敌的伤害,代表了一种防御机制,这与 Hystrix 本身的功能不谋而合。
因此 Netflix 团队将该框架命名为 Hystrix,并使用了对应的卡通形象作为 Logo。
在一个分布式系统里,许多依赖会不可避免的调用失败,比如超时、异常等。
如何能够保证在一个依赖出问题的情况下,不会导致整体服务失败,这个就是 Hystrix 需要做的事情。
Hystrix 提供了熔断、隔离、Fallback、Cache、监控等功能,它能够在一个、或多个依赖同时出现问题时保证系统依然可用。
使用 Hystrix 很简单,只需要添加相应依赖即可,最方便的方式是使用注解 HystrixCommand:
- fallbackMethod:指定 Fallback 方法
- threadPoolKey:线程池名称
- threadPoolProperties:指定线程池参数(线程池大小、***队列排队数量)
- commandProperties:CIRCUIT_BREAKER 开头的参数配置熔断相关参数,METRICS_ROLLING 开头的参数设置指标计算相关参数
- 相关参数定义,参考类:HystrixPropertiesManager
@RestController
public class HystrixTest {
@RequestMapping(value = "/query/user/name", method = RequestMethod.GET )
@HystrixCommand(fallbackMethod = "getDefaultUserName", threadPoolKey = "query_user",
threadPoolProperties = {
@HystrixProperty(name = CORE_SIZE, value = "10"),
@HystrixProperty(name = MAX_QUEUE_SIZE, value = "10")
},
commandProperties = {
@HystrixProperty(name = CIRCUIT_BREAKER_ENABLED, value = "true"),
@HystrixProperty(name = CIRCUIT_BREAKER_REQUEST_VOLUME_THRESHOLD, value = "1000"),
@HystrixProperty(name = CIRCUIT_BREAKER_ERROR_THRESHOLD_PERCENTAGE, value = "25")
}
)
static String getUserName(String userID) throws InterruptedException {
Thread.sleep(-1);
return userID;
}
public String getDefaultUserName(String userID) {
return "";
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
基于服务网关 Zuul 实现的广播功能
有些时候我们希望 url 请求被所有服务实例执行,这里我们对 Zuul 做了一个改造,增加了一个 BroadCastFilter,在 url 请求 header 设置 gate_broadcast 为 true,那么这个请求,将被转发给所有服务实例。
逻辑流程如下:
- 判断 gate_broadcast 参数为 true
- 从 url 获取 ServiceId
- 从 Ribbon 获取服务所有实例
- 将请求发送给所有实例
- 将所有实例返回结果封装,返回
微服务带来的问题
服务拆分粒度不好把握
Spring Cloud 的微服务有一个 ServiceId 的概念,通常一个 war 包对应一个 ServiceId,这个 ServiceId 下可以有多个服务。粒度拆分方式主要有:横向、纵向。
纵向切分主要有如下几个方式:
- 按功能切,如用户管理、指标管理、模型管理等。
- 按角色切,如管理员、商家、用户。
横向切分,一般用来提取公共的基础服务,比如:用户名密码校验服务、用户基本信息查询。
运维、开发复杂度增加
单体程序时代只有一个 war 包,微服务鼓励服务拆分,war 数量、部署节点大大增加。
此外,一个流程处理往往会由多个分布式服务协同完成,带来了不少棘手的问题:
- 需要通过分布式事务保障数据最终一致性
- 防止单个服务问题造成雪崩
这些都给开发者提出了更高的要求。
调试难度增加
微服务方式鼓励服务拆分,通过服务间依赖完成功能,给开发、测试带来了挑战,合理选择微服务、代码复用两种方案。
后续架构演进
服务版本控制
没有版本控制,意味着我们无法做灰度发布,毁灭性版本发布后,无法做到对老版本兼容,下图为服务 A、B、C、D 间的版本依赖关系:
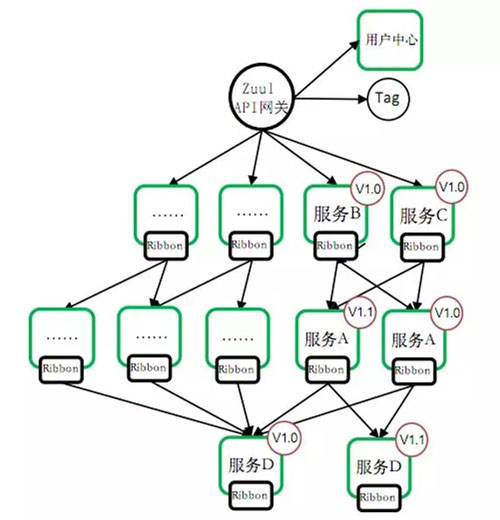
我们实现思路是对 Zuul 进行改造:
- 打版本标签,在 Zuul 对访问来源判断(比如 App 版本 5.1 对应的查询接口版本为 2.1),打上版本标签
- 根据版本信息,路由到对应版本服务实例
基于 Gateway 的服务熔断、限流机制
目前有一些开源的框架如 ratelimit,通过在 Ruul 增加 filter 来实现限流熔断。
但是有几个问题:
- 不支持动态配置
- 不能满足业务变化,如配合版本控制
综上所述,我们已经着手一些自研工作,能与我们业务场景贴合得更紧密。
总结
从 2016 年到现在,两年的时间里,苏宁大数据中心从传统的单例开发模式,切换到基于 Spring Cloud 的微服务开发模式,并摸索出了一条适合自己的路,这不只是技术框架的切换,更是开发思维的升级。
令人欣喜的是,这两年间 Spring Cloud 飞速发展,2018 年发布了革命性的 2.0 版本,这离不开社区的支持,许多像 Netflix 一样的公司在笔耕不辍地为 Spring Cloud 生态添砖加瓦。
我们基于 Spring Cloud 开发出了一些服务于自己业务的组件,让我们认识到自己也是有能力有责任去回馈社区。
路漫漫其修远兮,好的架构一定是适应业务发展的架构,对于 Spring 这不是终点,对于我们更不是。
作者:王富平
简介:苏宁易购大数据中心数据中台技术负责人,历任百度大数据部高级工程师、1 号店搜索与精准化部门架构师。多年来,一直从事大数据方向的研发工作,对大数据工具、机器学习有深刻的认知,在实时计算领域经验丰富,对 Storm、Spark Streaming 有深入了解。热爱分享和技术传播,目前关注数据分析平台的建设,旨在打通数据建模到数据分析,基于 Druid、Kylin 等 OLAP 技术,提供一个平台级别的数据指标服务,打造"数据即服务"的一站式解决方案。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】