












提到数据科学,我们想到的都是数字的统计分析,但如今需要对很多非结构文本进行量化分析。本文将以《圣经》为例,用 spaCy Python 库把三个最常见的 NLP 工具(理解词性标注、依存分析、实体命名识别)结合起来分析文本,以找出《圣经》中的主要人物及其动作。
引言
在思考数据科学的时候,我们常常想起数字的统计分析。但是,各种组织机构越来越频繁地生成大量可以被量化分析的非结构文本。一些例子如社交网络评论、产品评价、电子邮件以及面试记录。
就文本分析而言,数据科学家们通常使用自然语言处理(NLP)。我们将在这篇博客中涵盖 3 个常见的 NLP 任务,并且研究如何将它结合起来分析文本。这 3 个任务分别是:
- 词性标注——这个词是什么类型?
- 依存分析——该词和句子中的其他词是什么关系?
- 命名实体识别——这是一个专有名词吗?
我们将使用 spaCy Python 库把这三个工具结合起来,以发现谁是《圣经》中的主要角色以及他们都干了什么。我们可以从那里发现是否可以对这种结构化数据进行有趣的可视化。
这种方法可以应用于任何问题,在这些问题中你拥有大量文档集合,你想了解哪些是主要实体,它们出现在文档中的什么位置,以及它们在做什么。例如,DocumentCloud 在其「View Entities」分析选项中使用了类似的方法。
分词 & 词性标注
从文本中提取意思的一种方法是分析单个单词。将文本拆分为单词的过程叫做分词(tokenization)——得到的单词称为分词(token)。标点符号也是分词。句子中的每个分词都有几个可以用来分析的属性。词性标注就是一个例子:名词可以是一个人,地方或者事物;动词是动作或者发生;形容词是修饰名词的词。利用这些属性,通过统计最常见的名词、动词和形容词,能够直接地创建一段文本的摘要。
使用 spaCy,我们可以为一段文本进行分词,并访问每个分词的词性。作为一个应用示例,我们将使用以下代码对上一段文本进行分词,并统计最常见名词出现的次数。我们还会对分词进行词形还原,这将为词根形式赋予一个单词,以帮助我们跨单词形式进行标准化。
- from collections import Counter
- import spacy
- from tabulate import tabulate
- nlp = spacy.load('en_core_web_lg')
- text = """
- One way to extract meaning from text is to analyze individual words.
- The processes of breaking up a text into words is called tokenization --
- the resulting words are referred to as tokens.
- Punctuation marks are also tokens.
- Each token in a sentence has several attributes we can use for analysis.
- The part of speech of a word is one example: nouns are a person, place, or thing;
- verbs are actions or occurences; adjectives are words that describe nouns.
- Using these attributes, it's straightforward to create a summary of a piece of text
- by counting the most common nouns, verbs, and adjectives.
- """
- doc = nlp(text)
- noun_counter = Counter(token.lemma_ for token in doc if token.pos_ == 'NOUN')
- print(tabulate(noun_counter.most_common(5), headers=['Noun', 'Count']))
- Noun Count
- --------- -------
- word 5
- text 3
- token 3
- noun 3
- attribute 2
依存分析
单词之间也是有关系的,这些关系有好几种。例如,名词可以做句子的主语,它在句子中执行一个动作(动词),例如「Jill 笑了」这句话。名词也可以作为句子的宾语,它们接受句子主语施加的动作,例如「Jill laughed at John」中的 John。
依存分析是理解句子中单词之间关系的一种方法。尽管在句子「Jill laughed at John」中,Jill 和 John 都是名词,但是 Jill 是发出 laughing 这个动作的主语,而 John 是承受这个动作的宾语。依存关系是一种更加精细的属性,可以通过句子中单词之间的关系来理解单词。
单词之间的这些关系可能变得特别复杂,这取决于句子结构。对句子做依存分析的结果是一个树形数据结构,其中动词是树根。
让我们来看一下「The quick brown fox jumps over the lazy do」这句话中的依存关系。
- nlp("The quick brown fox jumps over the lazy dog.")
- spacy.displacy.render(doc, style='dep', options={'distance' : 140}, jupyter=True)

依存关系也是一种分词属性,spaCy 有专门访问不同分词属性的强大 API(https://spacy.io/api/token)。下面我们会打印出每个分词的文本、它的依存关系及其父(头)分词文本。
- token_dependencies = ((token.text, token.dep_, token.head.text) for token in doc)
- print(tabulate(token_dependencies, headers=['Token', 'Dependency Relation', 'Parent Token']))
- Token Dependency Relation Parent Token
- ------- --------------------- --------------
- The det fox
- quick amod fox
- brown amod fox
- fox nsubj jumps
- jumps ROOT jumps
- over prep jumps
- the det dog
- lazy amod dog
- dog pobj over
- . punct jumps
作为分析的先导,我们会关心任何一个具有 nobj 关系的分词,该关系表明它们是句子中的宾语。这意味着,在上面的示例句子中,我们希望捕获到的是单词「fox」。
命名实体识别
***是命名实体识别。命名实体是句子中的专有名词。计算机已经相当擅长分析句子中是否存在命名实体,也能够区分它们属于哪一类别。
spaCy 在文档水平处理命名实体,因为实体的名字可以跨越多个分词。使用 IOB
(https://spacy.io/usage/linguistic-features#section-named-entities)把单个分词标记为实体的一部分,如实体的开始、内部或者外部。
在下面的代码中,我们在文档水平使用 doc.ents 打印出了所有的命名实体。然后,我们会输出每个分词,它们的 IOB 标注,以及它的实体类型(如果它是实体的一部分的话)。
我们要使用的句子示例是「Jill laughed at John Johnson」。
- doc = nlp("Jill laughed at John Johnson.")
- entity_types = ((ent.text, ent.label_) for ent in doc.ents)
- print(tabulate(entity_types, headers=['Entity', 'Entity Type']))
- print()
- token_entity_info = ((token.text, token.ent_iob_, token.ent_type_,) for token in doc)
- print(tabulate(token_entity_info, headers=['Token', 'IOB Annotation', 'Entity Type']))
- Entity Entity Type
- ------------ -------------
- Jill PERSON
- John Johnson PERSON
- Token IOB Annotation Entity Type
- ------- ---------------- -------------
- Jill B PERSON
- laughed O
- at O
- John B PERSON
- Johnson I PERSON
- . O
实例:对《圣经》进行自然语言处理
上面提到的每个方法本身就很强大了,但如果将它们结合起来,遵循语言学的模式提取信息,就能发挥自然语言处理的真正力量。我们可以使用词性标注、依存分析、实体命名识别的一部分来了解大量文本中的所有角色及其动作。因其文本长度和角色范围之广,《圣经》是一个很好的例子。
我们正在导入的数据每个《圣经》经文包含一个对象。经文被用作圣经部分的参考方案,通常包括一个或多个经文句子。我们会遍历所有的经文,并提取其主题,确定它是不是一个人物,并提取这个人物所做的所有动作。
首先,让我们从 GitHub 存储库中以 JSON 的形式加载圣经。然后,我们会从每段经文中抽取文本,通过 spaCy 发送文本进行依存分析和词性标注,并存储生成的文档。
- import requests
- r = requests.get('https://github.com/tushortz/Bible/raw/master/json/kjv.json')
- bible_json = [line['fields'] for line in r.json()]
- print('Number of Verses:', len(bible_json))
- text_generator = (line['text'] for line in bible_json)
- %time verse_docs = [doc for doc in nlp.pipe(text_generator, n_threads=-1)]

我们已经用 3 分钟多一点的时间将文本从 json 解析到了 verse_docs,大约每秒 160 个经文章节。作为参考,下面是 bible_json 前 3 行的内容。
- [{'book_id': 1,
- 'chapter': 1,
- 'comment': '',
- 'text': 'In the beginning God created the heaven and the earth.',
- 'verse': 1},
- {'book_id': 1,
- 'chapter': 1,
- 'comment': '',
- 'text': 'And the earth was without form, and void; and darkness was upon the face of the deep. And the Spirit of God moved upon the face of the waters.',
- 'verse': 2},
- {'book_id': 1,
- 'chapter': 1,
- 'comment': '',
- 'text': 'And God said, Let there be light: and there was light.',
- 'verse': 3}]
使用分词属性
为了提取角色和动作,我们将遍历一段经文中的所有分词,并考虑 3 个因素:
- 这个分词是句子的主语吗?(它的依存关系是不是 nsubj?)
- 它的父分词是不是动词?(通常是这样的,但是有时候 POS 标注和依存分析之间会存在冲突,我们会安全地使用它。此外,我并不是语言学家,所以这里还会有一些奇怪的案例。)
- 一个分词的命名实体是否为一个人物?我们不想提取任何不是人物的名词。(为了简便,我们仅仅会提取名字)
如果我们的分词满足以上 3 种条件,我们将会收集以下的属性:
- 名词/实体分词的文本。
- 包含名词和动词的范围。
- 动词。
- 动词出现在标准英语文本中的对数概率(使用对数的原因是这里的概率都很小)。
- 经文数量。
- actors_and_actions = []
- def token_is_subject_with_action(token):
- nsubj = token.dep_ == 'nsubj'
- head_verb = token.head.pos_ == 'VERB'
- person = token.ent_type_ == 'PERSON'
- return nsubj and head_verb and person
- for verse, doc in enumerate(verse_docs):
- for token in doc:
- if token_is_subject_with_action(token):
- span = doc[token.head.left_edge.i:token.head.right_edge.i+1]
- data = dict(name=token.orth_,
- spanspan=span.text,
- verb=token.head.lower_,
- log_prob=token.head.prob,
- verseverse=verse)
- actors_and_actions.append(data)
- print(len(actors_and_actions))

分析
我们已经获得了提取到的所有角色及其动作的列表,现在我们做以下两件事来快速分析:
- 找出每个角色最常做出的动作(动词)
- 找出每个人最独特的动作。我们将其确定为英文文本中出现概率***的动词。
- import pandas as pd
- action_df = pd.DataFrame(actors_and_actions)
- print('Unique Names:', action_df['name'].nunique())
- most_common = (action_df
- .groupby(['name', 'verb'])
- .size()
- .groupby(level=0, group_keys=False)
- .nlargest(1)
- .rename('Count')
- .reset_index(level=1)
- .rename(columns={
- 'verb': 'Most Common'
- })
- )
- # exclude log prob < -20, those indicate absence in the model vocabulary
- most_unique = (action_df[action_df['log_prob'] > -20]
- .groupby(['name', 'verb'])['log_prob']
- .min()
- .groupby(level=0, group_keys=False)
- .nsmallest(1)
- .rename('Log Prob.')
- .reset_index(level = 1)
- .rename(columns={
- 'verb': 'Most Unique'
- })
- )
- # SO groupby credit
- # https: //stackoverflow.com/questions/27842613/pandas-groupby-sort-within-groups

让我们看一下前 15 个角色的动词数及其最常用的动词。
- most_common.sort_values('Count', ascending=False).head(15)

貌似《圣经》里面很多人都说了很多话,而所罗门简直是个例外,他做了很多事情。
那么从出现概率来看,最独特的动词是什么呢?(我们将在此处删去重复项,以便每个单词都是唯一的)
- (most_unique
- .drop_duplicates('Most Unique')
- .sort_values('Log Prob.', ascending=True)
- .head(15)
- )
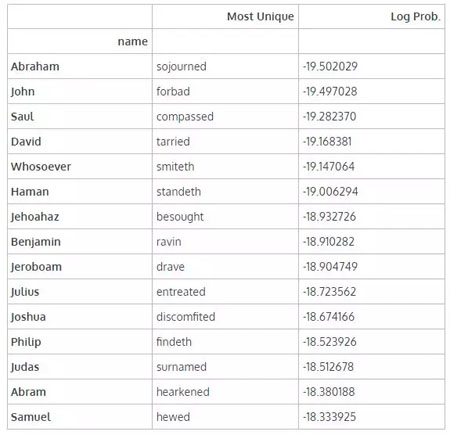
看来我们要学习一些有趣的新词汇了!我最喜欢的是 discomfited 和 ravin。
可视化
接下来可视化我们的结果。我们将选取行动最多、情节最多的前 50 个名字,这些行动发生在整篇文章中。我们还会在《圣经》每本书的开头画垂直线。姓名将按***出现的顺序排序。
这可以让我们知道圣经中每个角色最活跃的时候。
我们将添加一些分隔符来分隔《圣经》的不同部分。我自己并非研究《圣经》学者,所以我参考了如下分隔法
(https://www.thoughtco.com/how-the-books-of-the-bible-are-organized-363393):
《旧约》:
- 摩西五经或律法书:《创世纪》、《出埃及记》、《利未记》、《民数记》和《申命记》。
- 旧约历史书:《约书亚记》、《士师记》、《路得记》、《撒慕耳记》上下、《列王记》上下、《历代志》上下、《尼希米记》、《以斯拉记》、《以斯帖记》
- 诗歌智慧书:《约伯记》、《诗篇》、《箴言》、《传道书》和《雅歌》;
- 大先知书:《以赛亚书》、《耶利米书》、《耶利米哀歌》、《以西结书》、《但以理书》、《何西阿书》、《约珥书》、《阿摩司书》、《俄巴底亚书》、《约拿书》、《弥迦书》、《那鸿书》、《哈巴谷书》、《西番雅书》、《哈该书》、《撒迦利亚书》、《玛拉基书》。
《新约》:
- 福音书:《马太福音》、《马可福音》、《路加福音》、《约翰福音》
- 新约历史书:《使徒行传》
- 保罗书信:《罗马书》、《哥林多前书》、《哥林多后书》、《加拉太书》、《以弗所书》、《腓立比书》、《歌罗西书》《帖撒罗尼迦前书》、《帖撒罗尼迦后书》、《提摩太前书》、《提摩太后书》、《提多书》、《腓利门书》、《希伯来书》、《雅各书》、《彼得前书》、《彼得后书》、《约翰壹书》、《约翰贰书》、《约翰叁书》和《犹大书》
- 语言/启示录:《启示录》
此外,我们还会用一条红色的标志线分割《旧约》和《新约》。
- import seaborn as sns
- import matplotlib.pyplot as plt
- %matplotlib inline
- sns.set(context='notebook', style='dark')
- most_frequent_actors = list(action_df['name'].value_counts().index[:50])
- top_actors_df = action_df[action_df['name'].isin(most_frequent_actors)].copy()
- book_locations = (pd.DataFrame(bible_json)
- .reset_index()
- .groupby('book_id')['index']
- .min()
- .to_dict()
- )
- fig, ax = plt.subplots(figsize=(8,12), dpi=144*2)
- sns.stripplot(x='verse', y='name',
- data=top_actors_df, axax=ax,
- color='xkcd:cerulean',
- size=3, alpha=0.25, jitter=0.25)
- sns.despine(bottom=True, left=True)
- for book, verse_num in book_locations.items():
- ax.axvline(verse_num, alpha=1, lw=0.5, color='w')
- divisions = [1, 6, 18, 23, 40, 44, 45, 65]
- for div in divisions:
- ax.axvline(book_locations[div], alpha=0.5, lw=1.5, color='grey')
- ax.axvline(book_locations[40], alpha=0.5, lw=1.75, color='xkcd:coral')
- ax.set_xlim(left=-150)
- ax.set_title("Where Actions Occur in the Bible\nCharacters Sorted by First Appearance");

可视化分析
- 在《圣经》开头的《创世纪》中,上帝(God)被密集地提到。
- 在《新约》中,主(Lord)不再作为一个实体使用。
- 我们***次看到保罗是在《使徒行传》中被提及。(福音书后的***本书)
- 在《诗歌智慧书》里没有提到很多实体。
- 耶稣的生活在《福音书》中被密集地记录了下来。
- 彼拉多出现在《福音书》的末尾。
这种方法的问题
- 实体识别无法区分两个名字相同的人扫罗王(《旧约》)直到《使徒行传》的中途,保罗(使徒)一直被称作扫罗
- 有些名词不是实际的实体(如 Ye)
- 有些名词可以使用更多的语境和全名(如 Pilate)
下一步
一如既往,有办法扩展和改进这一分析。我在写这篇文章的时候想到了以下几点:
- 使用依存关系来寻找实体之间的关系,通过网络分析的方法来理解角色。
- 改进实体提取,以捕获单个名称之外的实体。
- 对非人物实体及其语言关系进行分析——《圣经》中提到了哪些位置?
写在结尾
仅仅通过使用文本中分词级别的属性我们就可以做一些很有趣的分析!在本文中,我们介绍了 3 种主要的 NLP 工具:
- 词性标注——这个词是什么类型?
- 依存分析——该词和句子中的其他词是什么关系?
- 命名实体识别——这是一个专有名词吗?
我们结合这三个工具来发现谁是《圣经》中的主要角色,以及他们采取的动作。并且我们还绘制了这些角色和动作的图表,以了解每个角色的主要动作发生在何处。
原文链接:https://pmbaumgartner.github.io/blog/holy-nlp/
【本文是51CTO专栏机构“机器之心”的原创文章,微信公众号“机器之心( id: almosthuman2014)”】




















