













Apache Spark是处理和使用大数据最广泛的框架之一,Python是数据分析、机器学习等领域最广泛使用的编程语言之一。如果想要获得更棒的机器学习能力,为什么不将Spark和Python一起使用呢?
在国外,Apache Spark开发人员的平均年薪为110,000美元。毫无疑问,Spark在这个行业中被广泛使用。由于其丰富的库集,Python也被大多数数据科学家和分析专家使用。二者集成也并没有那么困难,Spark用Scala语言开发,这种语言与Java非常相似。它将程序代码编译为用于Spark大数据处理的JVM字节码。为了集成Spark和Python,Apache Spark社区发布了PySpark。
Apache Spark是Apache Software Foundation开发的用于实时处理的开源集群计算框架。Spark提供了一个接口,用于编程具有隐式数据并行和容错功能的整个集群。
下面是Apache Spark的一些特性,它比其他框架更具优势:
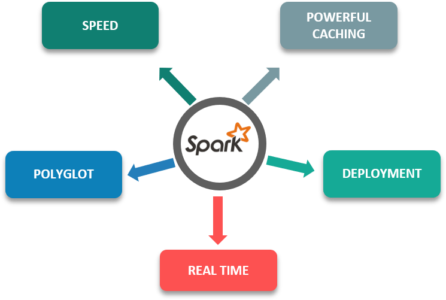
- 速度:比传统的大型数据处理框架快100倍。
- 强大的缓存:简单的编程层提供强大的缓存和磁盘持久性功能。
- 部署:可以通过Mesos、Yarn或Spark自己的集群管理器进行部署。
- 实时:内存计算,实时计算且低延迟。
- Polyglot:这是该框架最重要的特性之一,因为它可以在Scala,Java,Python和R中编程。
虽然Spark是在Scala中设计的,但它的速度比Python快10倍,但只有当使用的内核数量少时,Scala才会体现出速度优势。由于现在大多数分析和处理都需要大量内核,因此Scala的性能优势并不大。
对于程序员来说,由于其语法和标准库丰富,Python相对来说更容易学习。而且,它是一种动态类型语言,这意味着RDD可以保存多种类型的对象。
尽管Scala拥有SparkMLlib,但它没有足够的库和工具来实现机器学习和NLP。此外,Scala 缺乏数据可视化。
使用Python设置Spark(PySpark)
首先要下载Spark并安装,一旦你解压缩了spark文件,安装并将其添加到 .bashrc文件路径中,你需要输入source .bashrc

要打开PySpark shell,需要输入命令./bin/pyspark
PySpark SparkContext和数据流
用Python来连接Spark,可以使用RD4s并通过库Py4j来实现。PySpark Shell将Python API链接到Spark Core并初始化Spark Context。SparkContext是Spark应用程序的核心。
- Spark Context设置内部服务并建立到Spark执行环境的连接。
- 驱动程序中的Spark Context对象协调所有分布式进程并允许进行资源分配。
- 集群管理器执行程序,它们是具有逻辑的JVM进程。
- Spark Context对象将应用程序发送给执行者。
- Spark Context在每个执行器中执行任务。
PySpark KDD用例
现在让我们来看一个用例:数据来源为KDD'99 Cup(国际知识发现和数据挖掘工具竞赛,国内也有类似的竞赛开放数据集,比如知乎)。这里我们将取数据集的一部分,因为原始数据集太大。
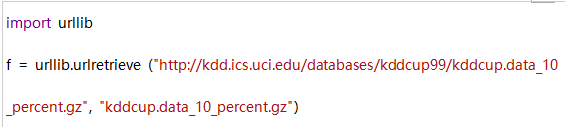
创建RDD:
现在我们可以使用这个文件来创建我们的RDD。

过滤
假设我们要计算我们在数据集中有多少正常的相互作用。,可以按如下过滤我们的raw_data RDD。

计数:
现在我们可以计算出新RDD中有多少元素。
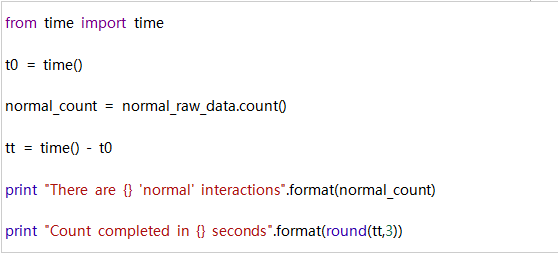
输出:

制图:
在这种情况下,我们想要将数据文件作为CSV格式文件读取。我们可以通过对RDD中的每个元素应用lambda函数。如下所示,这里我们将使用map()和take()转换。
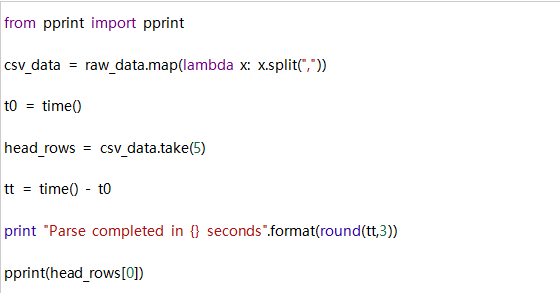
输出:
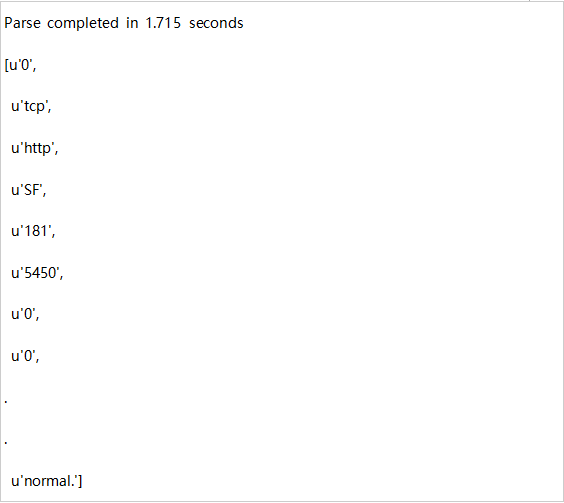
拆分:
现在,我们希望将RDD中的每个元素都用作键值对,其中键是标记(例如正常值),值是表示CSV格式文件中行的整个元素列表。 我们可以按如下进行,这里我们使用line.split()和map()。
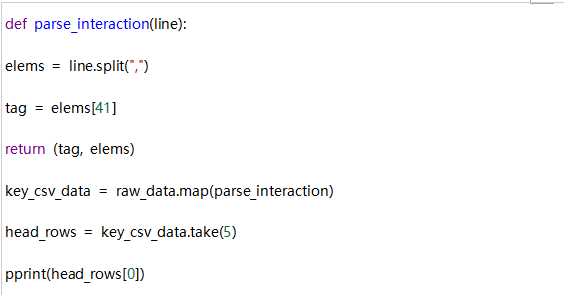
输出:

收集:
使用collect()动作,将RDD所有元素存入内存。因此,使用大型RDD时必须小心使用。

输出:
当然,这比我们之前的任何操作花费的时间都要长。每个具有RDD片段的Spark工作节点都必须进行协调,以便检索其各部分内容,然后将所有内容集合到一起。
作为结合前面所有内容的最后一个例子,我们希望收集所有常规交互作为键值对。

输出:



















