













云上存储产品主要有对象存储,块存储,网络文件系统(NAS),还有***钱的CDN,我们将针对这些主流产品,讲讲他们产品特点,有云上存储时候知道如何选型,当然我们是技术型作者也会简单讲讲实现思路,出于信息安全,不可能完全阐述工业界方案。 工业界各大厂商很多上层存储产品都重度依赖底层文件系统,我们也捎带说说存储祖师爷DFS。
一、Linux IO STACK

云计算本质就是单机计算能力的***扩展,我们先看看单机的文件及IO管理。 linux操作系统一个IO操作要经由文件系统vfs,调度算法,块设备层,最终落盘
- 其中vfs层有具体的NFS/smbfs 支持网络协议派生出来NAS产品
- VFS还有一个fuse文件系统,可切换到用户态上下文。上层分布式存储只要适配了Libfuse接口,就可访问后端存储
- 在设备层,通过扩展ISCSI网络协议,衍生出了块存储
二、存储产品架构流派
1. 分层或平层
如hbase,底层基于hdfs文件系统,hbase不用考虑replication,专注于自身领域问题
特点:大大降低开发成本,稳定性依赖底层存储,底层不稳定,上层遭殃。
2. 竖井
自己做replication,自己做副本recover,自己做写时recover

master-slave体系架构
两层索引体系,解决lots of small file:
- ***层,master维护一个路由表,通过fileurl找到对应slave location(ip+port)
- 第二层,slave单机索引体系,找到具体的location,读出raw data

DFS
3. 特点
丰富类posix语意,特点Append-only存储,不支持pwrite
4. 可能存在问题
- Pb级别存储方案,非EB级别。 原因namenode集中式server,内存&qps瓶颈,bat体量公司需运维上百个集群
- 默认三副本,成本高
- 强一致写,慢节点问题
5. 演进
GFS2拆分了namenode,拆分成目录树,blockservice,外加ferdaration,但namespace集中式server缺陷依旧,同时切分image是要停服,水平扩展不是那么友好。
三、对象存储

1. 元数据管理
Blobstorage: blobid->[raw data]
Metastore,aws s3又称为keymap,本质上是个kv系统。存储内容file_url->[blobid list]
2. I/O 路径
- httpserver收到muti-part form,收到固定大小raw data,切成K份等长条带
- 条带做EC,生成(N-K)份编码块,共得到N份shard。现在的问题变成了这N份数据存哪
- 客户端的代理继续向blobstorage申请一个全局的id,这个id代表了了后端实际node的地址,以及这个node管理的实际物理卷,我们的每个分片数据均等的存在这些物理卷上。
- 分发写N份数据,满足安全副本数即可返回写成功,写失败的可延时EC方式修复
- httpserver将文件file及对应的分片列表以KV形式写入metastore。
3. 特点
基于http协议 ws服务,接口简单,put/get,延时高。 EB级别存储方案,适合云上产品形态。深度目录树变成两层目录结构(bucket+object)。
4. 缺点
posix语意接口太少,不提供append语意(其实是通过覆盖写提供),更别说随机写。
四、块存储
1. iscsi模型
与后端交互的的部分在内核实现,后端target解析iscsi协议并将请求映射到后端分布式存储
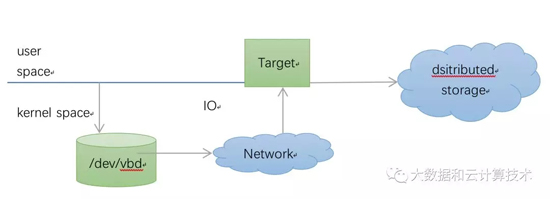
2. 特点
- 绝大多数请求大小是4K对齐的blocksize. 块设备的使用一般上层文件系统,而大多数主流文件系统的块大小是4KB,文件最小操作粒度是块,因此绝大多数的IO请求是4KB对齐的。
- 强一致. 块设备必须提供强一致,即写返回后,能够读到写进去的数据。
- 支持随机写,延时要低 用户基于虚拟块设备构建文件系统(ext4),对于文件编辑操作很频繁,所以需要支持随机写。 比NAS/Fuse类产品性能好,只hack块设备读写,上层dentry lookup还是走原来的IO path,没有像NAS/FUSE dentry的lookup发起多次rpc问题
- 产品层面需要预先购买容量,扩容需要重新挂载,跟NAS比容易浪费空间
3. 实现模型
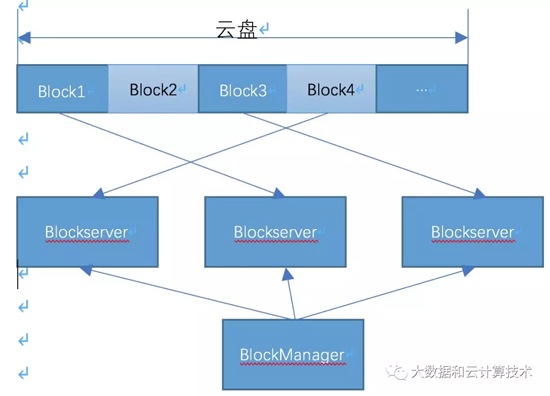
云盘逻辑卷按block切分,为了便于recover,按1G切分,***层路由由blockManager管理,按volumeid+offset 映射到逻辑block,逻辑block location在三台blockserver上。Blockserver预先创建一个1G文件(falloc,防止写过程中空间不够),称为物理block。对于逻辑卷这段区间所有的IO操作都会落到这个物理block文件上,很容易实现pwrite。当然也可以基于裸盘,在os看来是一个大文件,分割成不同的1G文件
4. IO路径
块设备上层会有文件系统,经过io调度算法,合并io操作,isici协议发出的IO请求的都是对扇区LBA的操作,所以可以简单抽象成对于卷id加上偏移的操作,我们简单讲讲EBS(Elastic Block Store)层IO路径:
- 网络发出来的IO请求是针对volume+offerset操作,假定是个写请求
- 通过blockManager查找到逻辑block
- 在内存中找到block对应的物理地址(ip+port),block的replicationGroup
- 使用业界通用复制链方式如raft协议向replicationGroup发送io请求,raft帮我们解决写时失败tuncate问题
- 单节点接到IO请求,把LBA换算成真实的文件偏移,pwrite写下去
5. 优化
- 可想而知,这种存储模型下,后端node会有大量的随机写,吞吐肯定不高,有很大的优化空间 可以通过类似LSM引擎方式,将随机写变成顺序写,读者可深入思考,本文不详细探讨了。
- 虚拟磁盘可以切条掉,相当于raid盘思路,单块盘的IO变成多多块盘,增大吞吐。
五、NAS
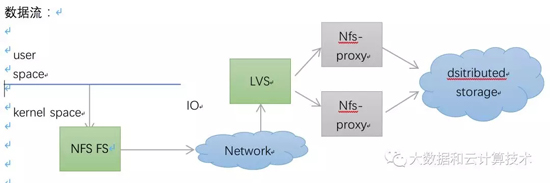
用户通过mount目录访问共享文件,mount点挂在的是一个NFS协议的文件系统,会通过tcp访问到NFS server。
NFS server是一个代理,通过libcfs最终会访问到我们后端的存储系统。
1. 后端存储系统
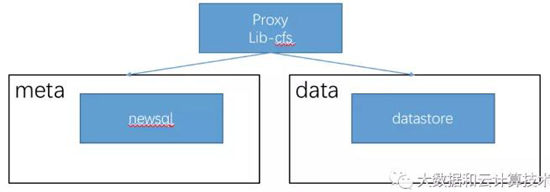
DS包含管理inode的metastore和datastore
(1) metastore
我们充分吸取业界DFS缺点,解决Namenode集中式server瓶颈,充分考虑bigtable的各种优点。Metastore可基于分布式数据库(newsql),回想一下bigtable,一个用户的文件散落在多个tabletserver上,允许用户跨tabletserver rename操作,所以需要分布式事务完成上述保证,出于对DFS改进,我们把目录树持久化 模仿linux fs dentry管理,映射规则如下 两张表,dentry表和inode表,dentry表描述目录树,inode表描述文件block列表及atime,mtime,uid,gid等源信息,一般来讲硬链够用,该场景下dentry可以多份,共同指向一个inode。 dentry通过外健关联到inode表
(2) Dentry表

(3) Inode表

比如lookup 子节点
SELECT i.* FROM Dentry d, Inode i WHERE d.PARENT_DID=$PARENT_ID AND d.NAME=$NAME AND d.FSID=$FSID and i.inode_id = d.inode_id;
- 1.
(4) datastore
特点:要求提供随机写,所以跟块存储EBS设计思路是一样的,大文件切块,按块组织,dataserver上有真实的物理block文件,提供pwrite操作。
2. 特点
弹性容量,不限容量,多机挂载并行读写,IO线性增长,支持随机写 比块存储优势在于用多少花多少,不需要提前申请容量,真弹性
3. 缺点
vfs层 dentry lookup每个层级目录会发起rpc,延时高。
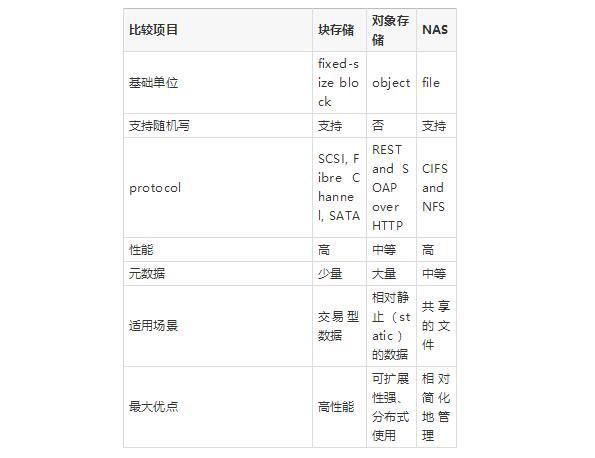
六、总结
【本文为51CTO专栏作者“大数据和云计算”的原创稿件,转载请通过微信公众号获取联系和授权】















