













前几天专门花了时间开始做元数据的稽核,其实这只是一个初步的开始,也算是才开始走上正道。
后续我又推出了几个方面的改进,准备在元数据的粒度和深度上逐步改善,把已有的元数据完善起来,能够发现很多潜在的问题,然后再逐步的改进,对于团队内的同学来说,他们不需要花费很多的精力去收集信息,这个事情让任务去做,他们需要做的是确认和问题修正。
比如通用元信息部分,对于MySQL实例来说,基本就是IP,端口,机房,数据库角色(Master,Slave等),数据版本,应用信息等,系统层的元数据,比如硬盘,内存,CPU应该是由专有的模块来维护。
确切的说,上面的这些信息只是通用,很难满足业务的实际需求,比如一个MySQL服务端配置,是否开启GTID,版本,角色,socket文件路径,数据文件路径,buffer_pool大小,是否开启binlog,server_id,VIP等这些信息其实是我们需要明确了解的。
有了这些信息,其实能够让我们对于实例的属性有一个基本的了解。
整个信息的收集看起来是一个很苦逼的过程,实际上我们可以让它变得高大上一些,比如我们把信息收集后使用前端页面做汇总和信息稽核,比如让数据的收集实现自动化,批量完成,而不需要手工来触发完成。
这些工作我们可以写脚本来完成,信息可以收集到,但是信息的管理和统筹和单纯的信息收集就不是一个层级了。我们在这个地方需要做的是元数据的管理和稽核,提前发现更多的问题,来逐步的完善,这样一来元数据最起码是可以参考和依赖的。
到了这个层级之后,其实我们能够得到一个基本的实例属性列表,但是显然还是还是存在短板,我们的MySQL实例基本上是主从复制的关系,有些实例可能是测试环境,或者是数据流转的节点,所以可能没有从库也没有备份。所以对于MySQL信息的归类我会这样来分类和处理:
1.***个维度是单点实例,单点实例是那些测试环境,数据流转节点或者业务优先级不高的业务。这些业务允许数据丢失,甚至允许环境重建,有一个基本的备份即可,这类的业务我们首先剥离出来,后面处理的时候就可以可以绕过这些节点,比如对于这些节点来说,可能不需要备份,可能不需要每天备份,压根不需要增量备份,binlog备份,按照这个规划,做了这些信息确认之后,后期要完成的备份恢复就有据可依,要不费了半天劲,***发现业务优先级不高,做事情的性价比就大打折扣。
2.第二个维度是数据库角色,数据库的角色其实不能严格意义上归类为Master,Slave,其实可以有更多的类型,比如单点业务,我们可以归类为SingleDB,如果是中继节点(show master status或者show slave status持有双重角色),我们可以归类为RelayDB,如果是主库或者是从库即为Master,Slave,如果属于MHA或者MGR的集群环境等,其实这个角色可以更加清晰,对于这部分信息我们需要做减法,即MHA或者MGR的环境,这类信息可以归类为集群信息,我们可以对其他的信息按照SingleDB,RelayDB,Master,Slave这四个维度来统计即可。
要实现这个功能,就有一些技巧需要补充了。
我们在这里需要两个脚本:
1)通过IP和端口信息得知实例的角色(Master,Slave,RelayDB,SingleDB等)
2)通过Slave和RelayDB的信息来得到Master的信息,亮点也就在此,通过这些信息我们可以清晰的达到一个复制关系图,甚至可以看到一些意想不到的问题。
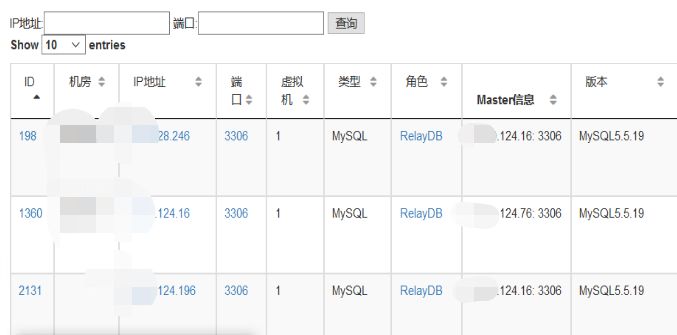
比如下面的IP信息,数据库角色是中继节点RelayDB(既是Master又是Slave)
我们根据IP的后两段内容搜索得到下面的一个基本列表。
这样一个关系,如果自己来刻意维护,其实很容易就会迷茫,或者意识不到这种级联关系的存在,但是我们对这些数据进行抽象,就很快能够得到这样的饿一个关系图,原来是这样的一个级联关系。这样一来124.16这个中继节点的角色和上下游的关系就很清晰了,那么从这个角度来看,我们是否需要对124.76做数据的备份就很容易得出结论了。
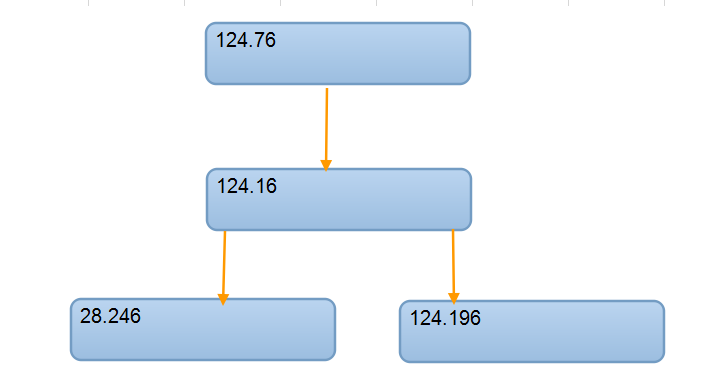
或者你可以基于这样的一个关系型结构来构建出一个更加完整的关系图,如果哪个环境缺少了信息也能够很清晰的判断出来。
到了这个阶段,就是发挥数据分析价值的时候了,数据一直在那儿,就看你是怎么处理它的。
















