深度学习图像处理简介:耳生物识别已成为一个热门的研究课题[1]。最近的一个挑战,被称为无约束耳朵识别挑战[2],显示了从野外的耳朵图像进行人物识别的困难。为了补充来自耳部图像的身份相关信息,利用软生物特征(如年龄和性别信息)可能是辅助手段。为此,本文中,我们广泛调查了耳部图像中年龄和性别分类的任务。
预计生物识别特征不会随时间变化很大,容易获得并且对每个个体都是独特的[3]。由于其几个特征,耳朵是生物识别研究和法医科学鉴定的重要模式。例如,与受面部表情,面部毛发或化妆的变化影响的面部外观相比,耳部外观相对恒定。耳廓也是面部特征[4]。在耳部中,耳垂是法医案件中使用最频繁的部分。它是耳朵唯一持续增长和改变形状的部分[5]。在安全摄像头拍摄的图像中,耳朵在整个或部分覆盖的脸部仍可以看到,并可用作识别的辅助信息。此外,当在配置文件中查看脸部时,可以从录像或照片中轻松捕捉耳朵[6]。
尽管在人耳识别中使用人耳图像已有很多研究[1],[6],但从耳部图像中提取软生物特征(如年龄和性别)的研究数量有限。据我们所知,这项研究是从耳朵图像的年龄分类的***项工作。然而,以前有关耳朵图像用于性别分类的一些工作。在[7]中,耳孔被用作测量的参考点。计算从掩盖的耳朵图像中识别的耳孔与耳朵的七个特征之间的欧几里德距离。他们使用一个内部数据库,其中有342个样本用于实验。他们采用了贝叶斯分类器,KNN分类器和神经网络。 KNN实现了***性能,分类精度为90.42%。
在[8]中,配置文件的人脸图像和人耳图像分开使用,并通过支持向量机(SVM)与直方图相交核进行分类。他们基于贝叶斯分析进行分数级融合以提高准确性。 UND生物特征数据集集合F [11]的2D图像已被用于实验。融合导致97.65%的准确性,而面对只有性能约为95.43%,耳朵只有精确度为91.78%左右。在文献[9]中,Gabor滤波器已经被用来提取特征,并且已经利用基于字典学习的提取特征来执行分类。该字典是根据训练样本构建的,并用于测试阶段,将测试样本表示为训练数据的线性组合。 UND生物统计数据集J [11],其中包含大的外观,姿态和光照变化,已用于实验。通过使用128个功能,报告中获得的***准确度为89.49%。在[10]中,性别分类在2D和3D耳朵图像上执行。 3D耳朵会自动检测并对齐。实验是在UND数据集集合F和J2上进行的[11]。索引形状的直方图特征通过SVM提取和分类。系统的平均性能为92.94%。
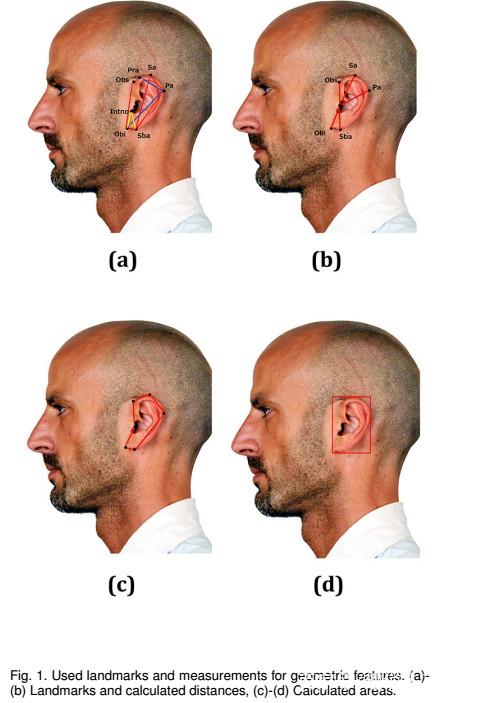
在本文中,我们对耳朵图像的年龄和性别分类进行了广泛的分析。我们已经探索了使用几何特征和基于外观的特征来表示耳朵。几何特征基于在耳朵上确定的八个地标。从这些地标中提取特征,我们计算了它们之间的14个不同距离以及执行了两个面积计算。为了对这些提取的特征进行分类,已经采用了四种不同的分类器 - 回归分析,随机森林,支持向量机,神经网络。
基于外观的方法基于众所周知的深度卷积神经网络(CNN)模型,即AlexNet [12],VGG-16 [13],GoogLeNet [14]和SqueezeNet [15]。他们已经进行了两次微调,首先是在大规模的耳朵数据集中提供领域适应,然后在小规模的目标耳朵数据集上进行。在实验中,基于外观的方法的性能优于基于几何特征的方法。我们在性别分类方面的准确率达到了94%,超过了之前研究中达到的准确率。对于年龄分类,已经获得52%的准确性。总之,论文的贡献可以列举如下:
•我们已经探索了基于几何和外观的耳部图像年龄和性别分类特征。
•对于几何特征,我们在耳朵上使用了8个地标点,并从中得出了16个特征。
•对于基于外观的方法,我们已经使用了一个大规模的ear数据集[16],该数据集是根据Multi-PIE人脸数据集中的轮廓和贴近人脸的人脸图像构建的[17]。通过这种方式,我们已经有效地从知名的CNN模型中转移并从中受益,解决了手头的问题。
•与以前的工作相比,我们在性别分类方面取得了出色的表现。我们从耳朵图像中提出了***部关于年龄分类的工作。

深度学习前沿算法Gender分类结果:性别分类结果列于表4中。在表中,***列包括分类器的名称,第二列包含相应的分类准确度。为了提醒读者使用的功能,功能的类型包含在第二列的括号内。从表中可以看出,基于外观的方法优于利用几何特征的分类器。考虑到正确的性别分类的机会水平是50%,使用几何特征获得的结果非常差。这种劣势表现的一个主要原因可能是已经应用于几何特征的标准化步骤。在规范化过程中 - 制作特征具有零均值和单位差异 - 有关性别的区分信息可能已经丢失。因此,规范化的影响需要进一步分析。基于外观的方法已经实现了大约90%的准确性。使用GoogLeNet架构获得***性能[14],分类正确率为94%。这种准确性超过了先前对耳朵图像中性别分类研究所取得的性别分类准确性[7],[8],[9],[10]。表5给出了这些方法的比较。总的来说,根据以前的研究结果,我们发现耳朵图像提供了有用的信息来分类主题的性别。
深度学习前沿算法年龄分类结果:年龄分类结果列于表6中。***列包括分类器的名称,第二列包含相应的分类准确度。为了提醒读者使用的功能,功能的类型包含在第二列的括号内。基于几何特征的方法和基于外观的方法之间的这种性能差距非常接近。但是,基于外观的方法已经被发现再次优越。使用几何特征,通过3个隐藏层神经网络和逻辑回归实现***性能,准确度达到43%。使用GoogLeNet体系结构的基于外观的方法[14]获得了***性能,其分类正确率为52%。与性别分类所取得的成绩相比,年龄分类准确性相对较低。这一结果的一个可能原因是每个年龄组的样本数量有限。由于年龄分类的班级数量较高,因此每班的样本量较少。我们计划扩展数据集并进一步分析结果。由于基于几何特征的方法和基于外观的方法获得的精度非常接近,所以结合这两种方法可能是另一种提高性能的方法。总体而言,外观提供了更多的信息与地理特征相比,因此,已被发现更有用的年龄和性别分类。
深度学习前沿算法结论:在本文中,我们对耳朵图像的年龄和性别分类进行了深入的研究。据我们所知,这项研究是***部关于耳朵图像年龄分类的研究,也是为数不多的利用耳朵图像进行性别分类的研究之一。在研究中,我们采用几何特征和基于外观的特征来表示耳朵。几何特征是针对耳朵上的八个人体测量地标进行计算的,包括14个距离测量和两个面积计算。然后用四种不同的方法对这些特征进行分类:逻辑回归,随机森林,支持向量机和神经网络。基于外观的方法基于深度卷积神经网络。众所周知的CNN模型,即AlexNet [12],VGG-16 [13],GoogLeNet [14]和SqueezeNet [15]已被采纳用于研究。
为了有效地将它们转移到手头的任务上,他们首先在一个大规模的耳朵数据集上进行了微调,这个数据集是根据配置文件和Multi-PIE人脸数据集中可用的贴近人脸的人脸图像构建的[17] 。之后,更新后的模型再次在小尺度目标耳数据集上进行了微调。作为实验的结果,基于外观的方法已经被发现优于基于几何特征的方法。我们的性别分类准确性达到了94%,而年龄分类准确率达到了52%。这些结果表明耳朵图像为年龄和性别分类提供了有用的线索。但是,使用几何特征的性别分类需要进一步的工作已经注意到,对于性别分类,几何特征对归一化是敏感的。因此,必须探索更好的标准化方案。对于年龄估计,我们认为造成性能下降的主要原因是缺乏每个年龄组的足够数量的训练样本。我们计划扩展数据集并训练年龄分类系统,并提供更多的样本。我们还旨在通过对常用数据集进行实验进行比较,如UND-F和UND-J2 [11]。此外,我们还计划研究几何和基于外观的特征之间的互补性。此外,我们计划将年龄和性别分类的侧面人脸图像和耳朵图像结合起来。