在这个数据科学越来越火的时代,数据科学家的工作到底是怎样的呢?
数据科学越来越火,很多人都想转行入坑数据科学家,这当然是好事。可是很多人都以为数据科学、机器学习等等流行词对应的工作,就是把数据塞进Sckit-Learn这个算法库里而已。
事实远远没有那么简单,下面我带大家走进真实的数据科学世界。
让我们从数据搜集完成后开始讲起。
问题阐述
“数据消耗”反映了特定服务类别数据的下载和上传量,比如社交网络,音频等等。我们来看一个具体的例子。假设我们研究的是一个计数器,利用该计数器可以查看与亚马逊网络服务(Amazon Web Service,简称为AWS)连接的机器数量。
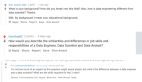
如果我们直接对原始数据进行分类,我们会得到如下结果:
我们可以注意到,这是对数据进行线性判别分析(Linear discriminant analysis,简称为LDA)后的二维示意图。理论上讲,LDA的结果可以体现出原数据的 ± 90%;虽然不是100%,但是这里我们可以看出,直接对数据进行分类完全没有意义。有人建议我换别的算法或者调整超参数,但是其实,把算法直接套在原数据上的想法糟透了。
理解数据
现在,我们来挖掘一番。数据到底长什么样?我强烈建议初学者多花些时间观察理解数据,而不要急着输入“from sklearn.cluster import KMeans”这样的代码行。这里我们研究一下这个例子的一个数据特征,但是请注意,大多数数据特征都是相似的。
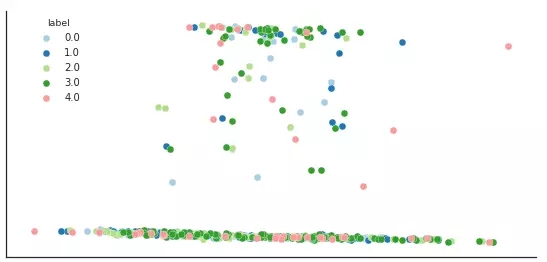
下面是AWS计数器的结果(其实不是,但是我们就假定它是吧)
从上到下:总数,平均值,标准差,最小值,25分位,中位数,75分位,***值
我们可以看到,几乎所有的数值都为0。不过您仔细看会发现,其实有些值达到3千万。您用这样的数值直接计算出来的距离值,再带入LDA算法中就不可能有意义。即使您缩小数据的规模使所有的数值都在0—1之间,那么绝大部分的数值也都会在0到大概0.0000005之间,对计算距离也没有帮助。
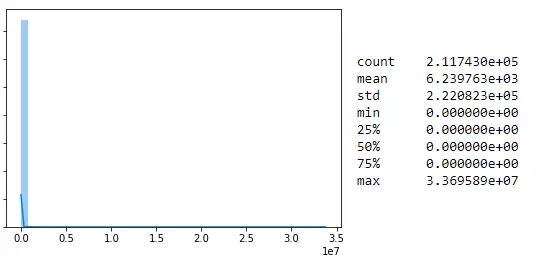
如果我们只看非零的数值,分布就很有意思了:
数据处理
上图看起来像是LogNormal分布。现在我们就可以进行简单的数据标准化了。采用Box-Cox法可以转化LogNormal分布。这个方法可以把包含LogNormal在内的许多分布尽可能的标准化。
转换的过程就是把下面公式中的lamda值最小化。
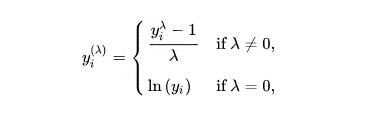
我们的数据集中有大量的0,所以lamda值最小化后的结果如下图所示:(请注意:我们需要大于0的结果,因此我们先给每个数值加上1之后再用公式计算)
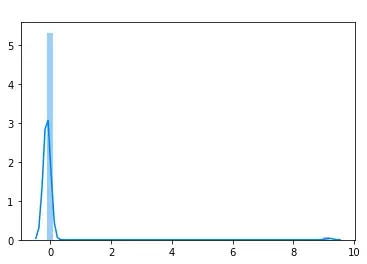
您可以看到上图中大概在9的位置有一个小突起,这就是我们大多非0值的位置。从计算距离的角度看,现在我们的数据分布已经比原来的好太多倍了,但是仍然有进步的空间。
让我们重新审视这个例子中数据的背景。我们想要根据机器的行为对其分类。在“机器对机器”的世界里,机器的行为包含了大量信息。“机器使用了亚马逊网络服务”这件事听起来很滑稽,但其实含义非常重要。
我们给这些机器编码,让它们承担特定的任务,比如报告天气、展示广告等等。它们做任务的代码都是编写好的,因而它们不可能随机的开始在脸书或者其他平台上操作。
事实上,它们可以使用一项服务(比如说AWS)本身就包含了大量信息。基于上面的分析,我决定对数据集中非零的数值进行标准化,使其规模在0.5到1之间;而对值为零的数据点保持不变。那么怎么标准化呢?当然是采用Box-Cox转化法——而且只对非零值进行转化。
请看下图的结果比较。左图是变换所有数据后得到的位于0—1区间的分布。右图是放大的0.5—1区间的分布。
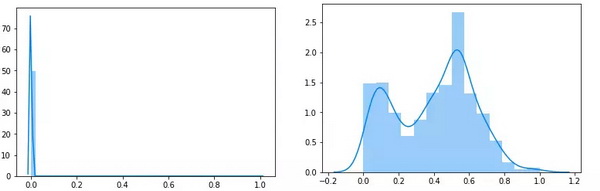
虽然说左图看起来没有比前面的方法提升很多,但是我向您保证,在后面应用算法的过程中两者的区别很大。
结果
下面我们对经过预处理的数据重新分类。不需任何手动调整我们就得到了如下结果。
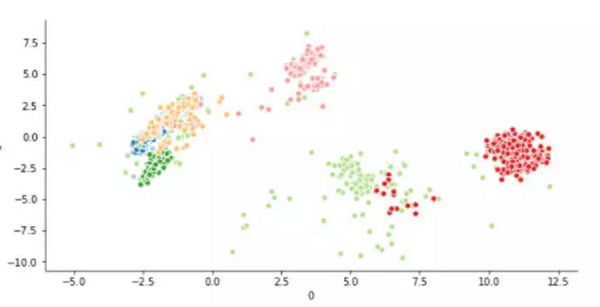
结论
我发现人们常常看到算法就如同打了鸡血,一头扎进建模的过程中。有的人甚至说,你不需要理解算法背后的数学原理。
我不赞同这个观点。我认为还是应该理解一个算法的基本原理,至少要能理解到知道什么样的数据输入才是有意义的。
比如说,我们刚才举例用的K-Means算法的基本原理就是点之间的距离,那么当您拥有“千万”这样的数量级时,您就不能期望直接把数据带入算法就会获得合适的结果,因为这时数值范围太大了。
综上所述,一遍一遍地检查数据,直到对它了然于胸,然后再让这些高级的算法完成后续的工作。