ACID 是软件领域使用最广泛的技术之一,它是关系数据库的基石,是企业级中间件不可或缺的部分,但通常通过黑盒的方式提供。但是在许多情况下,这种古老的事务方式已经不能够适应现代大规模系统和NoSQL数据库的需要了,现代系统要求更高的性能要求,更大的数据量,更高的可用性。在这种情况下,传统的事务模型被定制的事务或者半事务模型所取代,而在这些模型中事务性并不像以往那样被看重。
在本文中我们会讨论一下key-value数据库的无锁事务操作,这种技术可以广泛应用于任何一种数据库系统。在GridDynamics中,我们就用这种技术在Oracle Coherence上实现了一个轻量级的非标准的事务机制。在***部分我们会通过几个重要的用例来了解两种简单的方法,在第二部分我们会研究更多更通用的方法,比如说PostgreSQL的MVCC实现。
原子性缓存切换,读提交隔离
让我们从一个简单易于实现的方法开始,这个方法适用于读远多于写的系统。比如说电子商务系统中每天要进行的数据更新,一些管理性操作例如无效货品的修复以及缓存更新。
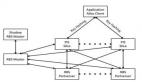
最简单的例子是把所有数据都加载进缓存里,然后通过一个代理接口来执行诸如 get() 和 put() 这样的操作。这个接口会与两个缓存打交道,A和B,按照以下逻辑运行(图 1):
任何时候只能有一个缓存处于可用状态,代理接口会把所有的请求路由给它(图1.1)。
更新数据的时候把新数据加载到目前不可用的缓存中(图1.2)。
更新进程切换标志哪个缓存可用的标记(图1.3),代理接口开始把新的读请求分发到新标记为可用的缓存。
缓存切换阶段的事务可以依据不用的持久性和隔离性要求来分别处理。如果允许“不可重复读” ,那么切换很简单,老数据会被立刻清理掉。否则,代理接口会维护一个仍未结束的事务列表,并把属于这个列表中的每一个请求都路由到原来的缓存中。只有当列表中的所有事物都提交或者放弃之后老数据才会被清空。
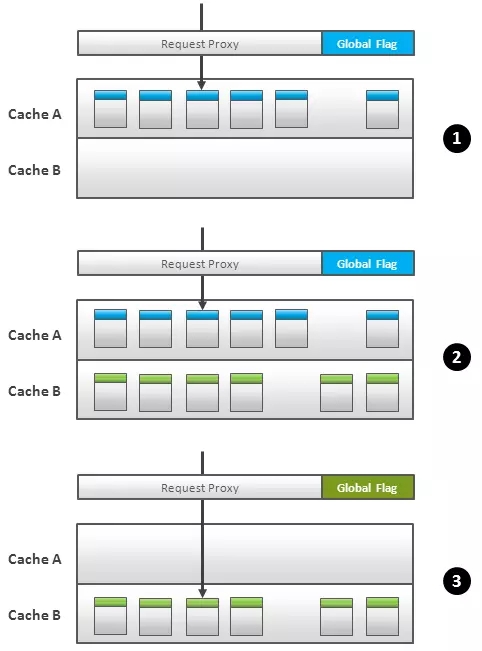
Fig.1 Cache Switch
相同的技术也可用于部分更新。依据存储方式的不同也有多种实现方法,我们来看一个有三个缓存简单例子。这个例子中的框架遇上一个类似,但是代理接口按照以下逻辑运行(图 2):
用户请求被路由到主缓存("PRIMARY"缓存)(图 2.1)
新增数据和更新数据加载进2号缓存(“NEW”缓存),删除项的key放入3号缓存("DELETE"缓存)(图2.2)
提交进程(特指写事务)切换全局标示,这个标示会告诉代理接口先去"NEW"和"DELETE"缓存去查找所请求的数据,如果在这两个区域中没有发现再去"PRIMARY"缓存查找(图2.3)。换句话说,在这一步所有的请求都被改派到了更新过的数据中查找。
提交进程将 NEW 和 DELETE 区域的变化传递给PRIMARY。也即在PRIMARY缓存区以非原子的方式更新、增加、删除数据项(图2.4)。
***,所有的提交进程把全局标识切换回来,所有的请求仍然路由到 PRIMARY 缓存区域(图2.5)。
在第4步,可以把老数据拷贝到另一个缓存区,这样就可以支持回滚操作。即使是全量更新也可以用这种方法。
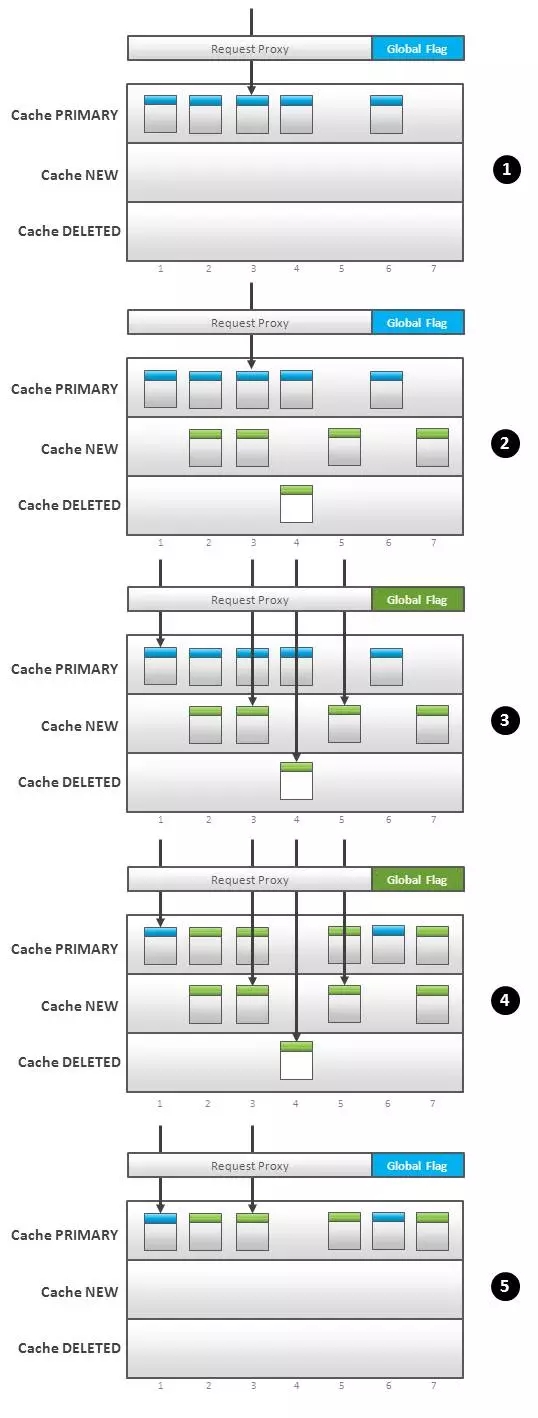
Fig.2 Partial Cache Switch
从上面的两个例子我们可以看出,专用于读的数据快照避免了数据更新的干扰,大大降低了复杂性。在一个写密集型的环境中就不容易做到这一点了。在下一节我们会讨论一种非常好的方法可以***的解决这个问题。
MVCC 事务,可重复读隔离
事物间的隔离可以通过给数据项加上版本号来实现。有许多方法能做到这一点,下面我们会介绍一种与PostgreSQL 的事务处理方法非常相似的办法。
正如前面所说,每个事务可以对应于一个部分数据快照。在同一时间,每一个数据项都有他自己的生命周期 - 从加入缓存到移出缓存或者被更新(被新版本所取代)。所以可以通过给每条数据打两个时间戳来实现隔离,每个事物通过开始时间(两个时间戳之一,译者注)来找出在事务开始时处于可见状态的数据。但在实践中常用一个单调递增的计数来代替时间戳:
- 新事务开始的时候:
它会获得一个全局唯一且单调递增的事务ID ,也叫 XID。
进程里保存着所有事务的XID.
- 缓存里的每个数据项有两个额外标记,xmin 和 xmax。按照以下规则赋值:
当数据项被某个事务建立的时候, xmin 设置为该事务的XID ,xmax 无值。
当数据被某个事务移除的时候,xmin 不变,xmax 设置为该事务的XID。数据并没有真的从缓存中清除,只是被标记为已删除。
当数据被某个事务更新的时候,老数据仍然保存在缓存里,xmax 被赋值为事务的XID,同时增加一条新的数据,新数据的 xmin 也赋值为XID 并且xmax 为空。换句话说更新操作等于一次删除加一次增加。
- 如果以下两个条件成立,那么数据对于某次事务是可见的:
xmin 有值并且小于或等于当前事务ID。
xmax 为空,或者等于未提交事务(放弃的或者还未完成的)的XID ,或者大于当前事务ID。
xmin 和 xmax 可以存储两个位标记,表明事务是否放弃或者提交,这样才能进行上面的检查(xmax 是否等于未提交事务的ID)。
逻辑如下图所示:
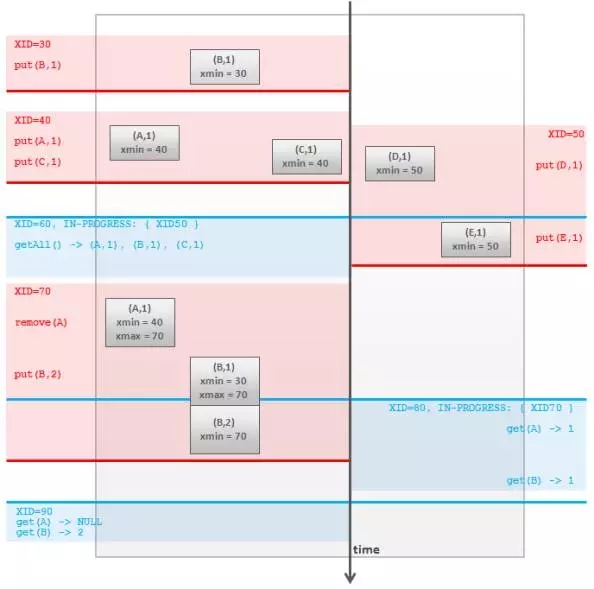
Fig.3 PostgeSQL-like MVCC
这种方法的缺点是废弃数据的移除有些繁琐。因为不同事务看到的数据版本不同,决定何时将数据标为不可见或者移除是比较复杂的。不过也有两种以上的方法能够做到,***种是PostgreSQL中使用的,第二种是Oracle使用的:
所有的版本都存储在同一个key-value空间中,对版本数量没有限制(也即可以储存任意多的版本,译者注)。由一个后台进程来回收老版本数据,这个回收可以按计划调度执行也可以再读或者写的时候触发。
主key-value 空间只储存***的版本,之前的版本储存在另外的地方,且储存老版本的空间大小是固定的。 ***的版本会指向之前的版本,但是却不能够由此上溯到之前的任意版本, 因为存储老版本数据的区域大小是固定的, 太早的版本会被移除。如果某个事务不能够找到指定版本的数据就会失败。