ServiceFabric:用于云端构建微服务的分布式平台。

微软的 Service Fabric 为 Azure 的许多关键服务提供支持。它已开发了大约 15 年,部署于生产环境已有 10 年,2015 年供外界使用。
ServiceFabric(SF)让用户能够对于由微服务组成的可扩展、可靠的应用程序进行应用程序生命周期管理――这些微服务在共享的机器集群上高密度运行,从开发到部署到管理,提供一站式功能。
在 SF 上运行的几个值得关注的系统包括:
-
Azure SQL DB(100000 台机器,含有 3.48PB 数据的 182 万个数据库)
-
Azure Cosmos DB(200 万个核心和 100000 台机器)
-
Skype
-
Azure 事件中心
-
Intune
-
Azure IoT 套件
-
Cortana
SF 在多个集群中运行,每个集群有成百上千台机器,机器总数超过 160000 台,核心数量超过 250 万个。
定位和目标
Service Fabric 不太好分类,但论文作者将其描述为“微软在云环境下支持微服务应用程序的平台”。尤其与众不同的地方是,Service Fabric 立足于强一致性(strong consistency)的基础,包括通过可靠集合(reliable collections)支持有状态服务(stateful service):可靠、持久、高效、事务性的高级数据结构。
现有系统为微服务提供不同级别的支持,市面上最主要的系统有 Nirmata、Akka、Bluemix、Kubernetes、Mesos 和 AWS Lambda[良莠不齐]。SF 功能比较强大:它是如今唯一面向有状态微服务、可识别数据的编排系统。尤其是,我们需要支持低级架构组件中的状态和一致性,这促使我们解决与故障检测、故障切换、leader 选举、一致性、可扩展性和可管理性有关的分布式计算难题。与上面这些系统不同,SF 没有外部依赖项,它是一种独立的框架。
SF 中的每一层都支持强一致性。这不是说你无法在上面构建弱一致性的服务(如果你想这么做的话),但这个难题比在不一致的组件上构建强一致性的服务来得容易解决。“基于我们的使用场景研究,我们发现需要 SF 的团队大多数都要求强一致性,比如微软 Azure DB、微软商业分析工具等,它们在执行事务时都依赖 SF。”
总体设计
SF 应用程序是独立版本控制、可升级的微服务的集合,每个微服务都执行一项独立功能,由代码、配置和数据组成。
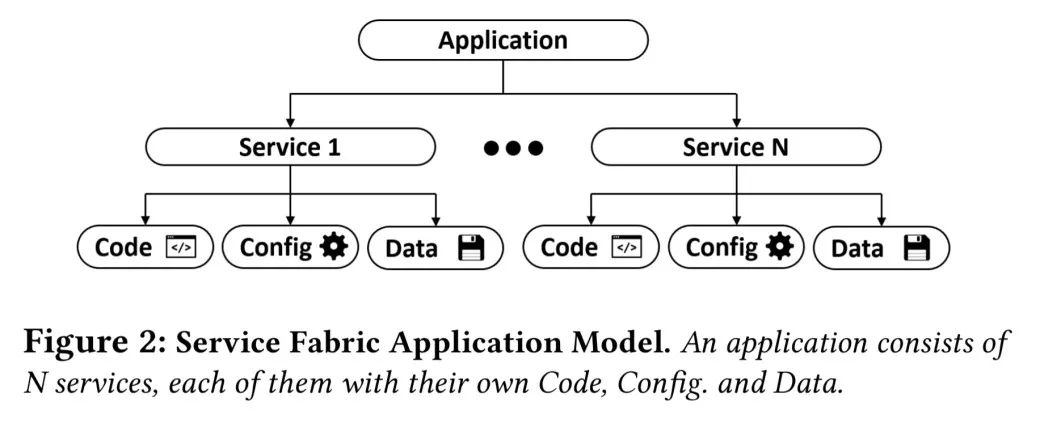
SF 本身包括多个子系统,主要的子系统如下图所示。
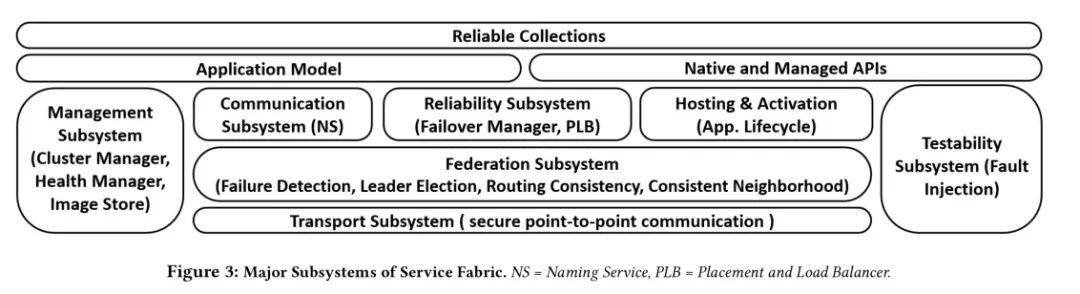
SF 的核心是联合子系统(Federation Subsystem),它处理故障检测、路由和 leader 选举。建立在联合子系统上的是提供复制和高可用性的可靠性子系统(reliability subsystem)。论文更详细地描述了这两个子系统。
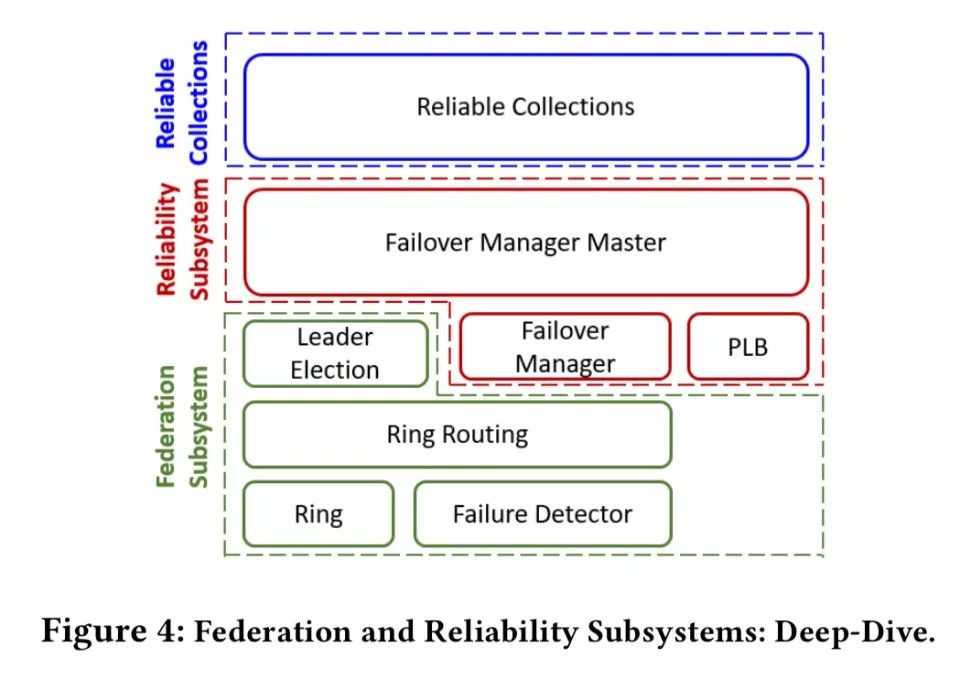
联合子系统
环
在联合子系统的核心,你会发现一个有2^m点的虚拟环,名为 SF 环(SF-Ring)。2000 年初它是在微软内部开发的,与 Chord 和 Kademlia 颇为相似。节点和密钥映射到环中的一个点,密钥由最靠近它的那个节点拥有,由前一个节点获得联系。每个节点跟踪环中紧跟它的后一个节点和前一个节点,这些节点构成了邻居节点集(neighborhood set)。
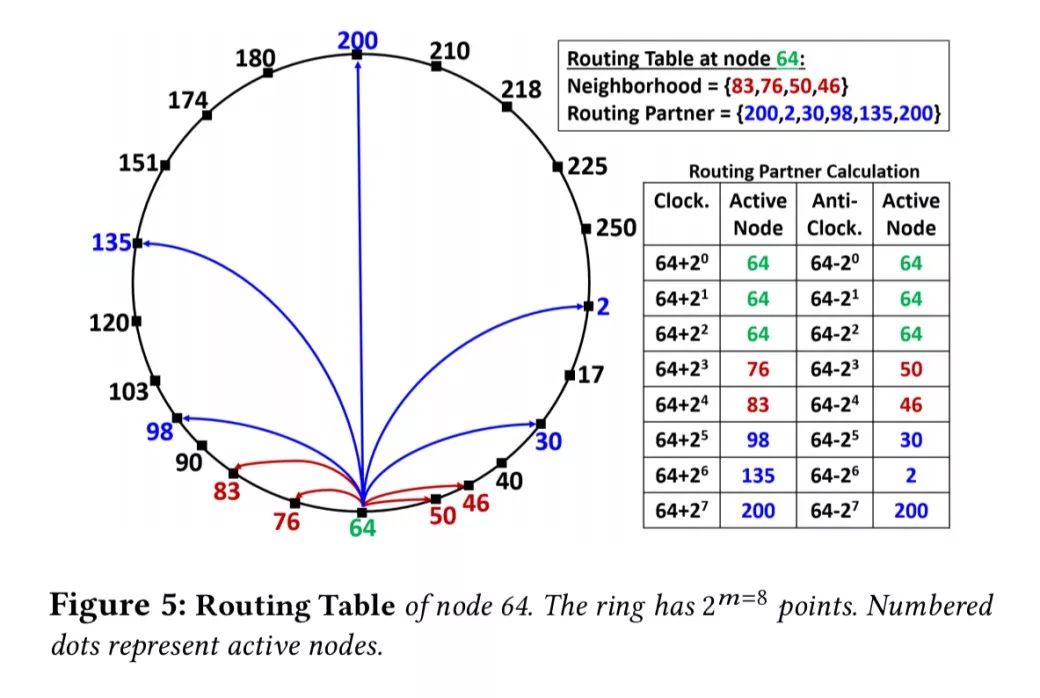
路由表条目是双向、对称的。路由伙伴在环中以急剧增加的距离来加以维持,按顺时针方向和逆时针方向。由于双向性,大多数路由伙伴最终都是对称的。这加快了路由、故障信息的传播以及节点流失后的路由表更新。
转发密钥消息时,节点以顺时针方向或逆时针方向搜索路由表中最靠近密钥的那个节点。相比只按顺时针方向的路由,我们获得了速度更快的路由,面对过期表或空白表有更多的路由选择,可以更有效地跨节点分配负载,以及避免路由环路。
路由表最终收敛。聊天协议在路由伙伴之间交换路由表信息,确保远距离邻居节点拥有最终一致性。
SF 方面的一个关键结果是,如果将强一致性成员与环上的弱一致性成员结合起来,可以大规模支持强一致性应用程序。文献常常将强一致性成员等同于虚拟同步,但这种方法在可扩展性方面存在限制。
环中的节点拥有路由令牌(routing token),路由令牌表示环中哪部分的密钥由它们负责。SF 环协议确保令牌之间永远不会有任何重叠(始终安全),每个令牌范围最终都由至少一个节点拥有(最终存活)。有节点加入时,前后两个相邻的节点各自与新节点分享其在环上的一段。有节点离开时,前后两个相邻的节点在当中将令牌范围分开来。
如果我们看一下可靠性子系统,会发现节点和对象(服务)被布置到环中,而不是简单地依赖哈希。这样一来,优先布置(preferential placement)可以考虑到故障域和负载均衡。
一致性成员和故障检测
成员和故障检测在邻居节点集里面进行。有两个关键的设计原则:
-
强一致性成员:负责监视节点X的所有节点必须就该节点是正常还是宕机达成一致。在 SF 环中,这意味着X的邻居节点集内的所有节点必须就其状态达成一致。
-
故障检测与故障决策分开:故障检测协议(心跳)检测可能的故障,而独立的仲裁节点组(arbitrator group)决定如何处理此情况。这有助于发现并阻止起连锁反应的故障检测。
节点X定期向其每个邻居节点(监视节点)发送续租请求。租赁期动态调整,但通常是 30 秒左右。X必须从它的所有监视节点获得确认(租约)。这个属性定义了强一致性。如果X未能获得全部租约,它考虑将自己从组中移除。如果监视节点错过X的续租心跳,它考虑将X标记为有故障。在这两种情况下,证据都提交给仲裁节点组。
仲裁节点充当故障检测和检测冲突的裁判。出于速度和容错方面的考虑,仲裁节点被实施成一个分散的节点组(每个节点独立运行)。一旦系统中的任何节点检测到故障,在采取与该故障相关的操作之前,它需要获得仲裁节点组中大多数(法定数额)节点的确认。
仲裁节点协议的细节可在论文第 4.2.2 节找到。使用轻量级仲裁节点组让成员、因而让环可以扩展到整个数据中心。
leader 选举
鉴于我们有一个精心维护的环,SF 为 leader 选举提供了一种巧妙而实用的解决方案:
对于 SF 环中的任何密钥k,都有一个独特的 leader:这是令牌范围包含k的节点(由于路由令牌的安全性和活跃性,这个节点具有唯一性)。任何节点都可以通过路由到密钥k来联系 leader。因此 leader 选举是隐式的,不需要额外消息。在整个环需要 leader 的情况下,我们使用 k = 0。
可靠性子系统
为了简洁起见,我将专注于可靠性子系统的布置和负载均衡器(PLB)组件。它的任务就是将微服务实例布置到节点,同时确保负载均衡。
不像传统的分布式哈希表(DHT),对象 ID 被哈希到一个环,PLB 为 SF 环中的节点分配每个服务的副本(主副本和次副本)。
布置组件会考虑节点处的可用资源、未完成的请求以及典型请求的参数。它还不断将服务从过度耗尽的节点转移到未充分利用的节点。 PLB 还将服务从即将升级的节点迁移出去。
PLB 可能会处理不断变化的环境中成千上万个对象,因此某一时刻作出的决定在下一时刻可能不是***的。因此,PLB 偏向做出快速敏捷的决策,不断进行小幅改进。为此使用了模拟退火(Simulated annealing)。模拟退火算法设置一个计时器(快速模式下是 10s, 慢速模式下是 120s),并探究状态空间,直到收敛或直到计时器到期。每个状态都有能量。能量函数是用户可定义的,但一种常见的情况是集群中所有度量的平均标准偏差(越低越好)。
每一步生成随机移动,考虑因这个移动而导致的新预期状态的能量,并决定要不要跳跃。如果新状态的能量较低,退火过程跳跃的概率为1;否则,如果新状态的能量比当前状态高出d,当前温度是T,跳跃发生的概率是e-d/T。这个温度T在初始步中很高(允许从局部最小值跳跃),但跨迭代线性下降,以便之后收敛。
所考虑的移动是细粒度的。比如说,将次副本交换到另一个节点,或者交换主副本和次副本。
可靠集合
SF 的可靠集合提供字典和队列之类的数据结构,它们具有持久性、可用性、容错性,高效性和事务性。状态本地保存在服务实例中,同时又具有高可用性,所以读取是本地的。写入通过被动复制从主副本转发到次副本,一旦法定数额得到确认,就被认为完成。
可靠集合立足于联合子系统和可靠性子系统的服务:副本在 SF 环中加以组织,检测到故障后,选举一个主节点。PLB(与故障切换管理器配合使用)保持副本容错和负载均衡。
SF 是唯一自给自足的微服务系统,可以用来构建可靠的、自我*和可升级的事务一致性数据库。
汲取的经验教训
论文第 7 节深入谈论了开发 SF 过程中汲取的经验教训。由于篇幅所限,我在这里只给出标题,建议您参阅论文以了解详细信息:
-
分布式系统不仅仅是节点和网络。灰色故障很常见。
-
应用程序/平台的责任需要明确分离(你不能相信开发人员总是做对事情)。
-
容量规划是应用程序的责任(但开发人员需要帮助)。
-
不同的子系统需要不同级别的投入。
下一步是什么?
我们的日常工作主要解决这个问题:降低管理集群的复杂性。为此,一项工作就是改用这种服务:客户永远看不到一台台服务器......其他值得关注、长期的模式围绕着让客户拥有服务器,还要能够在那些服务器加入进来后将微服务管理作为一项服务来运行。此外从短期来看,我们考虑在可靠集合中实现不同的一致性级别,自动向内扩展和向外扩展可靠集合分区,并提供地理分布副本集的功能。从稍长远来看,我们在考虑最有效地利用非易失性内存,作为 ServiceFabric 的可靠集合的存储区。这需要处理许多值得关注的问题,从记录字节与面向块的存储、高效加密到感知事务的内存分配,不一而足。
论文: