一直以来都被高度曝光的人工智能领域相关应用,总是引来巨大关注。在电商搜索领域,人工智能发挥着怎样的作用?Etsy数据科学主管洪亮劼以案例为基,从人工智能技术在电商中的基本应用、电商人工智能技术与传统领域的异同等方面出发,为大家带来了一场以“人工智能技术在电商搜索的落地应用”为题的干货分享。
人工智能在电商的应用
人工智能技术在电商中的基本应用可以分为三个方面,分别是搜索、推荐和广告,主要目的是为了让顾客更加便捷的买到自己想要的商品。
电商的***要务在于是否能够利用自身的搜索、推荐、广告平台,让顾客更加快速有效的购买一件商品。其次,相对于传统平台而言电商必须具备这一功能——发现,目的是帮助用户找到他目前不太想买但仍存在潜在购买性的商品。
假设把电商购物与线下购物体验进行对比,普通人在进行线下购物时,商家未必会把顾客心仪的产品摆在最外面,那么顾客就存在一定的不购买性且在很短时间内离开购物中心。对购物中心而言,他们更希望顾客能停留尽可能多的时间,且在这段时间内能光顾更多商家;作为用户而言,虽然绝大多数用户可能没有在***时间购买商品,但这并不妨碍这些用户享受这样的购物环境。如何将线下的购物场景运用到线上购物中?是目前的电商平台所需要考虑的一个问题,也是对人工智能应用而言一个相对巨大的挑战。
电商人工智能技术与传统领域的异同
就搜索应用而言,电商搜索与普通搜索的***区别在于购买流程的建模及发现流程的建模。普通的搜索模式更希望用户尽可能在搜索页面本身停留较短的时间,它更希望用户只点击搜索页面的首页,而非翻到第二页第三页。它将最相关的内容放在首页的前几位的目的是为了让用户点击首页搜索结果后能够快速离开,将用户的这一操作过程控制在30秒甚至更短的时间内。
相反,它希望用户能够持续反复的进行这一搜索交互操作。电商搜索则与普通搜索有着很大的差别,在传统搜索中最受重视的相关性并非电商搜索的全部,只是电商搜索的一方面而已。而电商搜索更需要关注总体利润,能否通过搜索来产生效益。电商搜索的最终目的是提高用户的购买诉求,其次是激发用户的潜在购买欲望。因此,电商搜索相对于传统搜索而言,多了“如何利润***化”、“如何激发用户潜在购买欲”等维度。
就推荐应用而言,目前的推荐系统已较为完善,也出现了许多推荐方案。但电商推荐与传统推荐又有何不同?已有的推荐模型均基于Collaborative Filtering(协同过滤),一般的Collaborative Filtering是通过用户过去的行为对未来的行为进行预测推荐。以视频网站为例,假设你在某个视频网站上浏览过某部电影的***季,这一视频网站便会为你推荐这部电影的第二季、第三季。
但如果在电商场景下,假设用户已经购买某一产品,而电商推荐系统继续向你推荐相同产品时,就会暴露出这一系统的不智能性。因此,Collaborative Filtering技术对电商推荐而言是不恰当的,需要根据电商的特殊属性来对推荐系统做出大的调整。电商的最终目的是为了让用户购买商品,通过推荐的方式使用户购买***化商家的利润,这需要在过去的推荐系统上增加更多元素。如库存元素,假设商家把仅有少量库存甚至库存唯一的商品推荐给很多用户,一旦商品售出就会使得其他用户有较差的使用体验。如何利用库存来做到比较好的交互体验是电商搜索需要关心的一个内容。
就广告应用而言,电商的广告系统是双信息坊系统。对于卖家而言,更希望通过广告费用使得自己的商品出现在搜索页面的前几位。对于平台而言,通过帮助卖家获取更多的点击量来收取一定费用。对于买家而言,即使搜索页面的前几位是广告位,也不会使用户产生反感,因为买家的最终目的是买到适合自己的产品。
在这一层面,就存在买家、卖家、平台之间的三方博弈,而这三方很明显有三个不同的优化目标,因此需要针对这三个不同的目标函数进行优化。卖家希望用最少的钱打到***的效果;买家希望买到***的东西;平台则希望在这个交易过程中利益***化。如何将三种不同诉求的目标统一在同一建模中,这对于电商广告系统而言又是一大挑战。
电商搜索有别于传统搜索,不管是在搜索、推荐领域还是广告领域,基本都属于一个未知的领域,这其中的核心在于两个任务,一是如何衡量评价所做的事情是否正在优化你的目标;二是如何优化贯穿搜索、推荐及广告之间的关系。
电商搜索的优化案例
以优化GMV(搜索产生的利润)为案例作为分享,它将搜索相关性与利润相挂钩。何为GMV?
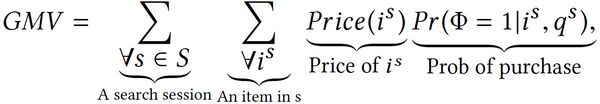
GMV是在搜索过程中所能衡量的期望利润,针对每一个商品关键字,用户存在一定购买概率。这一概率乘以商品本身的价格,再对所有的商品和所有的搜索绘画进行加和,得出一个期望利润,再将这一利润***化。目标在于估计用户究竟有多大可能购买一个商品,同时,这些商品也是价格较贵或是能让商家从中赚取更多利润的产品。有了这一目标后,重新评估电商搜索领域用户的决策行为,将这个决策行为进行简化至两个步骤,***步是在搜索页面输入关键字后进行比较,在经过比较后的排序结果里点击某一结果,针对这个点击结果进行建模。点击结果后,页面跳转至下一页面,进入第二个页面后,用户可以根据页面内容、商品价格等进行建模,以确定自己是否需要购买这一商品。
简单来说,是将整个购买过程简化成两个步骤,一是选择、二是决定;也将如何产生GMV分成两个步骤,***个步骤是从搜索页面产生“点击”的决策动作,二是从产品页面进行“购买”的决策动作。
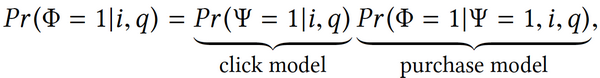
回到GMV公式中的购买概率,将这一概率拆成两个部分,分别为点击概率及基于点击的购买概率。拆分后即可对两个部分进行单独建模。首先是点击建模,点击建模存在于搜索页面的基础之上,当页面呈现出一个搜索结果后再启动点击。这一部分存在可直接借鉴的模型——Learning to Rank(学习排序),两者***的区别仅在于传统的Learning to rank是从用户的相关度来学习,或者是查询关键字的相关度。这里仅需要将相关度在NDCG中从页面相关程度标签转化为点击标签。下图为NDCG的公式。
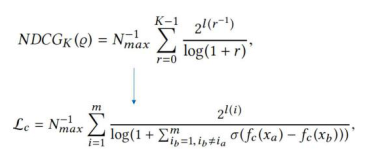
在这一公式中,未知数为Fc,这也是需要建模来表达的未知数(点击概率)。通过深度网络对点击概率进行建模,这也是这一过程中的***个步骤。
第二个步骤为二元决策,也就是当用户到达某一个产品的页面时,所做出的“是否购买”的决策行为。运用logistic regression,学习logistic regression中的wp系数。
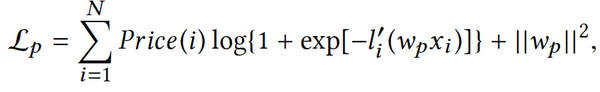
与标准二元决策的差异在于需要对logistic regression重新通过价格进行权重分类。从中可以看出,价格是决定用户是否购买的重要因素,其中优化目标不再是相关度而是GMV。
从下图的数据中可以看出,用户的点击存在商品位置的偏见。
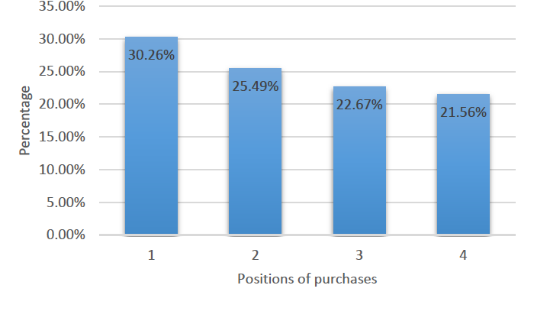
排在前几位的商品点击率较高,这也是与传统搜索相似之处,用户希望他所预期的产品能够排在相对靠前的位置,但这一基于位置的递减点击速率远远低于传统搜索。
(注:以上内容根据数据侠洪亮劼在数据侠线上实验室的演讲实录整理。图片来自其现场PPT,已经本人审阅。本文仅为作者观点,不代表DT财经立场。)