引言
用最短的时间写一个最简单的爬虫,可以抓一些简单的论坛、帖子、网页。
入门
1.准备工作
- 安装Python
- 安装scrapy框架
- 一个IDE或者可以用自带的
2.开始写爬虫

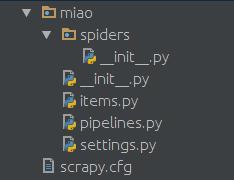
在spiders文件夹中创建一个python文件,比如miao.py,来作为爬虫的脚本。
代码如下:
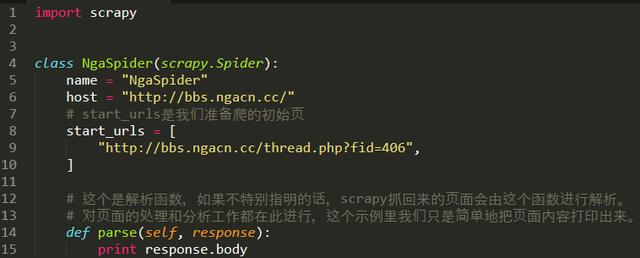
3.运行一下
如果用命令行的话就这样:


解析
1.试试神奇的xpath

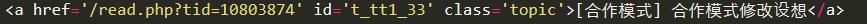

2.看看xpath的效果
在最上面加上引用:
from scrapy import Selector
把parse函数改成:
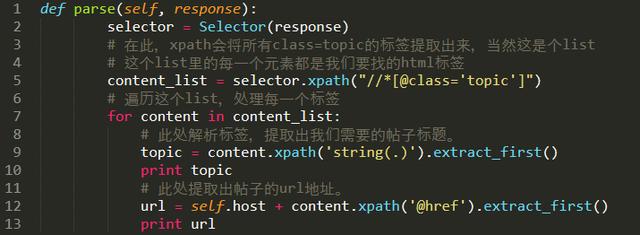
我们再次运行一下,你就可以看到输出“坛星际区”***页所有帖子的标题和url了。
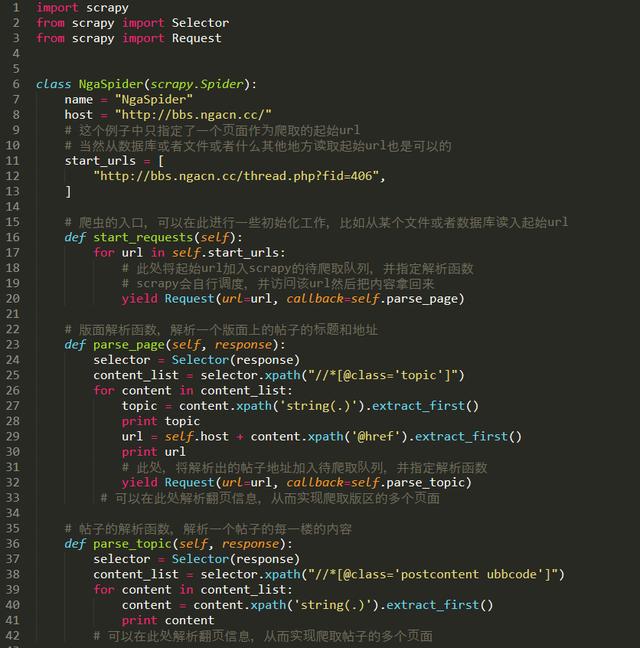
递归

完整的代码如下:

Pipelines——管道
现在是对已抓取、解析后的内容的处理,我们可以通过管道写入本地文件、数据库。
1.定义一个Item
在miao文件夹中创建一个items.py文件
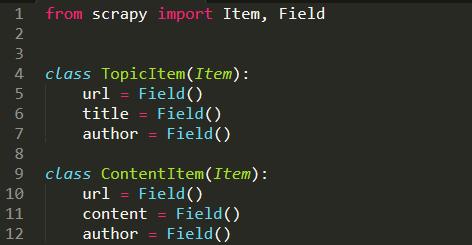
这里我们定义了两个简单的class用来描述我们爬取的结果。
2. 处理方法

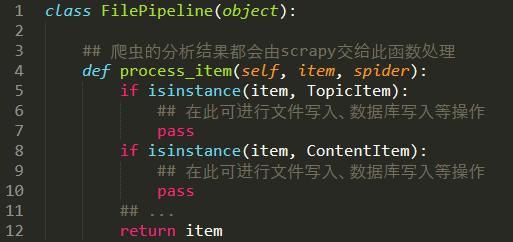
3.在爬虫中调用这个处理方法。

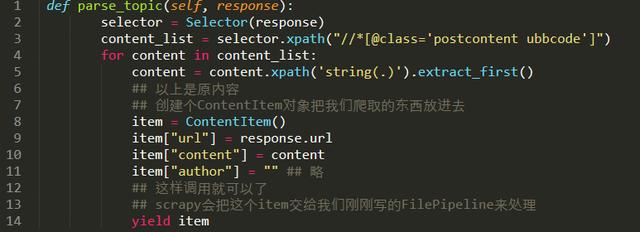
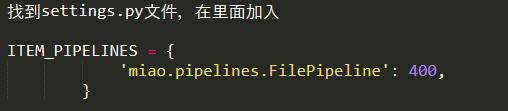
4.在配置文件里指定这个pipeline

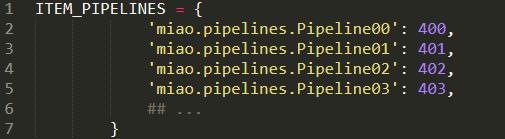
可以这样配置多个pipeline:
Middleware——中间件

1.Middleware的配置


2.破网站查UA, 我要换UA

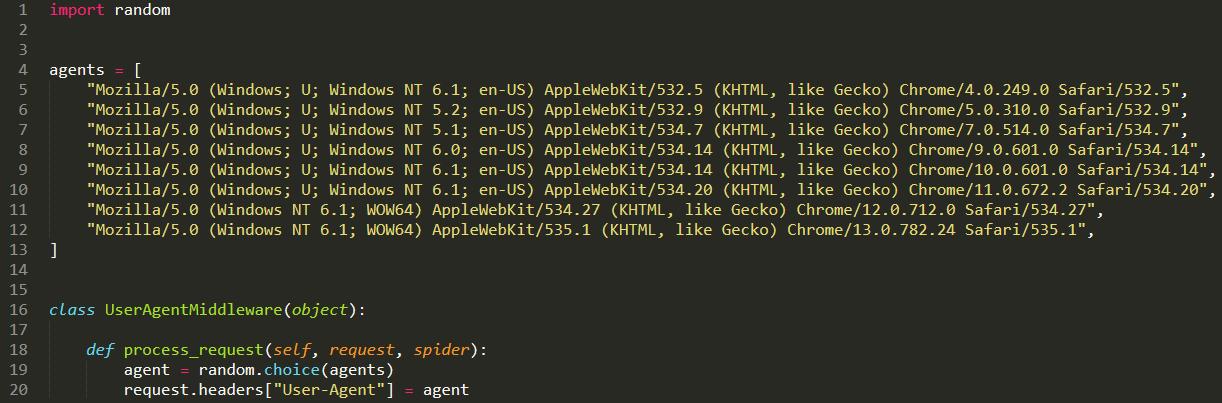
这里就是一个简单的随机更换UA的中间件,agents的内容可以自行扩充。
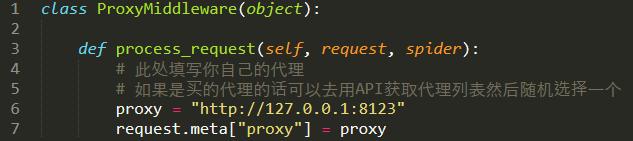
3.破网站封IP,我要用代理


结束
看懂了吗 ?是不是超简单!