












近日,Kyligence参加了微软加速器上海联合普华永道加速器举办的零售及消费品行业客户对接会,Kyligence 解决方案架构师海书山受邀参加大会,并发表题为《大数据分析:赋能创新零售战略》的演讲。

在他的演讲中,不仅对大数据时代零售企业普遍面临的数字化转型挑战抛出了自己的观点,也通过案例分享,对Kyligence的大数据分析解决方案Kyligence Analytics Platform如何解决这一困境做了分享。以下是现场演讲实录:
大家好,首先感谢PwC和微软的这次活动,先自我介绍一下,我叫海书山,是Kyligence的解决方案架构师,从个人层面来说我有一些零售行业架构、实施和咨询的经验,从公司的角度我们主要是通过大数据技术来帮助企业在不同的职能层面来提升数据洞察力和分析效率,所以我的主题是《大数据分析:赋能创新零售战略》。
从我之前的项目经验,和现在作为数据厂商跟不同的客户沟通中,发现我们零售行业因为数据问题有很多痛点,比如因为渠道不同而造成消费者体验的一个割裂,这也导致了消费者的忠诚度、成交率和转化率比较低。另外就是因为很多零售企业数字化转型程度还不是很高,所以就会有很多数据碎片,数据口径不一致等问题。也因此带来了管理成本很高,企业的数字化决策困难等等。
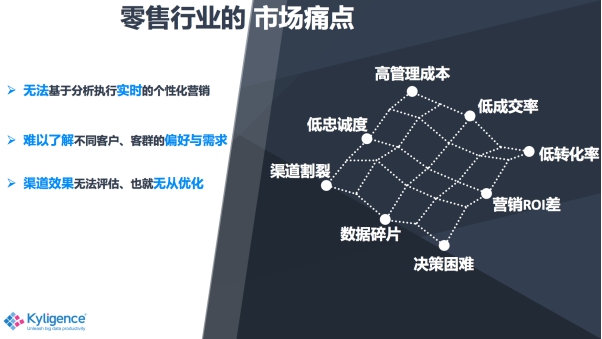
那这些问题在大数据时代怎么去解决呢?
现在很多零售企业都在做转型,比如从IT到DT的一个转型,我们来看一下大数据能带来什么。首先大数据能让我们对客户有更好的洞察力,比如将不同渠道、来源的客户进行统一整合和识别,这也给实时个性化推荐或者精准营销等等提供了基础。然后我们可以针对进销存、物流效率等等做一些供需链的优化和相应的风险管控。***呢我们可以把这些关于客户和运营的应用和场景,以大数据分析和可视化的形式呈现出来,并且给我们做一些决策上的支持。那这些就是我们叫做大数据零售的核心能力,也就是通过大数据分析的手段给零售行业的赋能。
为了达到或者实现这些应用,我们在技术上需要做到什么?
首先我们面临的肯定是海量数据,不管是数据量还是数据的复杂程度都比传统的数据应用提升了一个等级;同时不管是实时分析,还是交互式分析,都对数据的实时性要求更高,也就是我们要低延迟;接着在海量数据和低延迟的基础之上,我们还要求并发性,因为我们面临的可能是一线运营人员,甚至说终端消费者,并发量从几十上百,到成千上万,所以高并发是很重要的,甚至是必须的。***我们还希望资源可以弹性伸缩,因为数据量可能有波峰波谷,并发水平也有高有低,所以计算和存储资源***能随时的scale in/scale out。
这些是我们想要大数据能达到的技术要求,那现在的大数据分析平台是不是能做到呢?
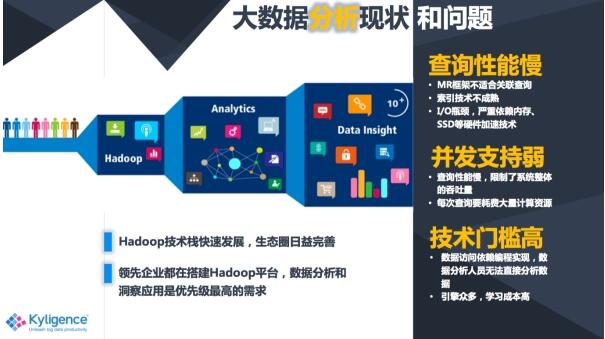
首先说到大数据,离不开的话题肯定是Hadoop,Hadoop已经基本成为大数据领域的标配,它的生态系统也比较完善,大家都在各自的Hadoop平台上面去实现数据分析和洞察的一些应用。但与此同时呢,其实我们发现了一些问题,比如说查询性能比较慢,对并发支持也很弱等等一些Haddop的技术特性所决定的弱点,另外呢就是因为技术门槛高,所以大数据的人才比较难找。
正是因为看到了大数据分析平台的这些问题,所以我们Kyligence提出有针对性的解决方案,其实就是在数据中心和数据应用之间搭建了一个桥梁,或者说数据加速层,我们融合了现在比较流行的ABC技术,那A就是用AI分析引擎,去智能化的完成数据准备和查询优化,降低使用门槛;B就是我们的Big Data,实现数据应用的高并发和加速,甚至可以支持实时分析;C就是Cloud,云,那我们同时支持本地和云端部署,实现统一的数据访问入口。这就是我们叫Kyligence Analytics Platform,或者我们的大数据分析解决方案。
那这套解决方案的应用场景到底有哪些呢?
其实有很多,比如说我们最常用到的多维分析报表,还有在预定义指标和维度的基础上实现灵活分析,或者说自助分析;另外比如说用户画像应用,还有将数据和平台以云计算的方式提供服务(DaaS),这些都是我们已经实现的应用场景。

我们来看一个客户案例,这是我们帮某全球跨国连锁餐厅的市场部门做的一个大数据分析平台的case,他们在数字营销的过程中呢,确实遇到了一些问题,比如数据口径不一致、分析周期太长、不能探索式的数据分析等等,相对来说制约了市场部门的活动和营销效率。那我们的方案呢,是在他们现有的数据平台上,搭建统一的大数据分析平台,并且能直接给到市场部门的运营人员去自助地分析,极大的降低了分析的门槛。从商业的角度来说,提高了活动效率和ROI,也给一些市场决策提供了更好的分析支持,这也就是我们说大数据分析给数字营销带来的价值。
那介绍了完场景和案例,我们的核心技术到底是什么?
Apache Kylin!做技术或者数据圈的应该都知道Apache基金会在大数据领域的影响力,比如Hadoop、Spark其实都是在Apache下面开源的。Kylin是我们***个Apache的***开源项目,作为有独立知识产权的***项目,我们也非常自豪,主要解决的就是前面一直说的大数据分析问题,也就是在海量数据下实现高并发和亚秒级响应。那现在在全球已经有超过1000家公司在用Kylin作为数据分析的解决方案,这也证明了我们技术的先进性。

那说到我们公司呢,Kyligence,这下就很好理解,是Kylin+Intelligence的合写,其实就是用Kylin实现数据上的智能,我们也是Apache Kylin的原创团队组建的,在商业上首先我们有Kylin的企业级产品KAP,和相关的一些基于Cloud的产品生态圈,另外我们的团队会提供基于大数据或者行业的解决方案,包括平台实施,架构咨询等等一些专业的服务。
除了刚才说的案例,我们在各个行业都有一些典型案例,特别是金融、保险、互联网等等在大数据方面走在前面的行业,比如说国泰君安的客户洞察和营销分析,OPPO的手机日志分析平台等等,也确实在不同的客户和场景下都验证了我们的技术和解决方案的优势。
我的分享就到这,希望有机会跟在座的各位做一些深入的沟通,谢谢!
关于Kyligence
Kyligence 由***来自中国的 Apache 软件基金会***开源项目 Apache Kylin 核心团队组建,是专注于大数据分析领域创新的数据科技公司。Kyligence 提供基于 Apache Kylin 的企业级大数据智能分析产品 Kyligence Enterprise,以及基于公有云的托管式 Kylin 在线服务 Kyligence Cloud。目前,Kyligence 已赢得了海内外多家金融、保险、证券、电信、制造、零售、广告等企业级客户。













