对于深度学习而言,数据集非常重要,但在实际项目中,或多或少会碰见数据不平衡问题。什么是数据不平衡呢?举例来说,现在有一个任务是判断西瓜是否成熟,这是一个二分类问题——西瓜是生的还是熟的,该任务的数据集由两部分数据组成,成熟西瓜与生西瓜,假设生西瓜的样本数量远远大于成熟西瓜样本的数量,针对这样的数据集训练出来的算法“偏向”于识别新样本为生西瓜,存心让你买不到甜的西瓜以解夏天之苦,这就是一个数据不平衡问题。
针对数据不平衡问题有相应的处理办法,比如对多数样本进行采样使得其样本数量级与少样本数相近,或者是对少数样本重复使用等。最近恰好在面试中遇到一个数据不平衡问题,这也是面试中经常会出现的问题之一,现向读者分享此次解决问题的心得。
数据集
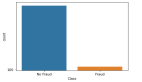
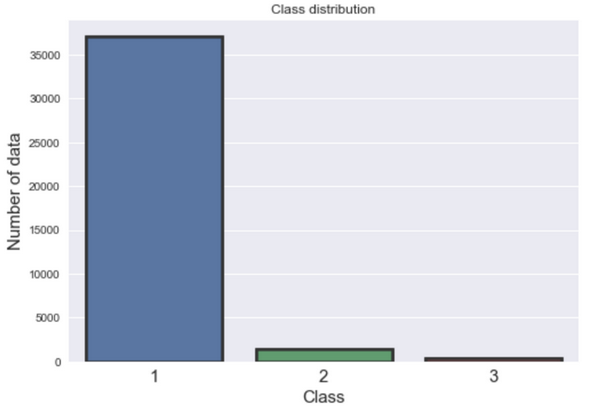
训练数据中有三个标签,分别标记为[1、2、3],这意味着该问题是一个多分类问题。训练数据集有17个特征以及38829个独立数据点。而在测试数据中,有16个没有标签的特征和16641个数据点。该训练数据集非常不平衡,大部分数据是1类(95%),而2类和3类分别有3.0%和0.87%的数据,如下图所示。
算法
经过初步观察,决定采用随机森林(RF)算法,因为它优于支持向量机、Xgboost以及LightGBM算法。在这个项目中选择RF还有几个原因:
- 机森林对过拟合具有很强的鲁棒性;
- 参数化仍然非常直观;
- 在这个项目中,有许多成功的用例将随机森林算法用于高度不平衡的数据集;
- 个人有先前的算法实施经验;
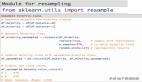
为了找到***参数,使用scikit-sklearn实现的GridSearchCV对指定的参数值执行网格搜索,更多细节可以在本人的Github上找到。
为了处理数据不平衡问题,使用了以下三种技术:
A.使用集成交叉验证(CV):
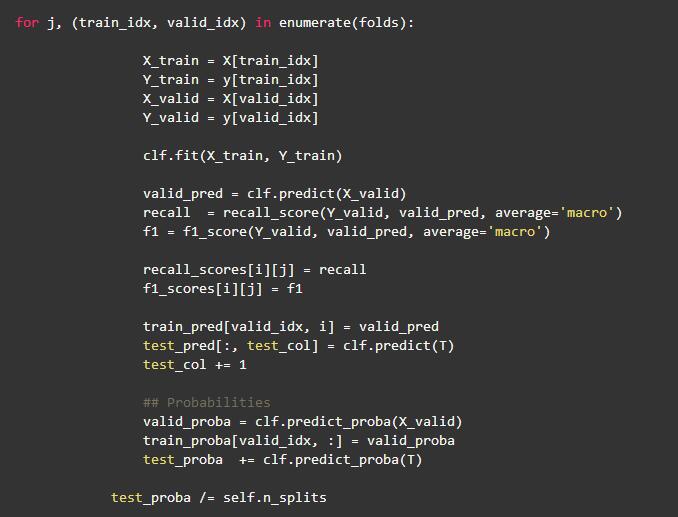
在这个项目中,使用交叉验证来验证模型的鲁棒性。整个数据集被分成五个子集。在每个交叉验证中,使用其中的四个子集用于训练,剩余的子集用于验证模型,此外模型还对测试数据进行了预测。在交叉验证结束时,会得到五个测试预测概率。***,对所有类别的概率取平均值。模型的训练表现稳定,每个交叉验证上具有稳定的召回率和f1分数。这项技术也帮助我在Kaggle比赛中取得了很好的成绩(前1%)。以下部分代码片段显示了集成交叉验证的实现:
B.设置类别权重/重要性:
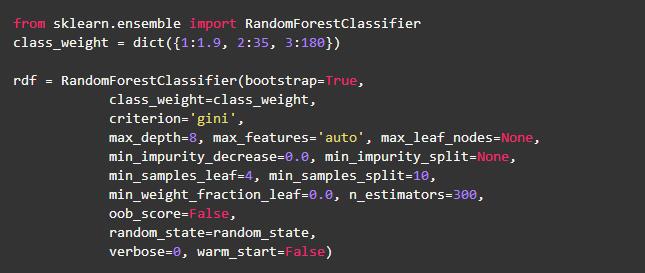
代价敏感学习是使随机森林更适合从非常不平衡的数据中学习的方法之一。随机森林有倾向于偏向大多数类别。因此,对少数群体错误分类施加昂贵的惩罚可能是有作用的。由于这种技术可以改善模型性能,所以我给少数群体分配了很高的权重(即更高的错误分类成本)。然后将类别权重合并到随机森林算法中。我根据类别1中数据集的数量与其它数据集的数量之间的比率来确定类别权重。例如,类别1和类别3数据集的数目之间的比率约为110,而类别1和类别2的比例约为26。现在我稍微对数量进行修改以改善模型的性能,以下代码片段显示了不同类权重的实现:
C.过大预测标签而不是过小预测(Over-Predict a Label than Under-Predict):
这项技术是可选的,通过实践发现,这种方法对提高少数类别的表现非常有效。简而言之,如果将模型错误分类为类别3,则该技术能***限度地惩罚该模型,对于类别2和类别1惩罚力度稍差一些。 为了实施该方法,我改变了每个类别的概率阈值,将类别3、类别2和类别1的概率设置为递增顺序(即,P3= 0.25,P2= 0.35,P1= 0.50),以便模型被迫过度预测类别。该算法的详细实现可以在Github上找到。
最终结果
以下结果表明,上述三种技术如何帮助改善模型性能:
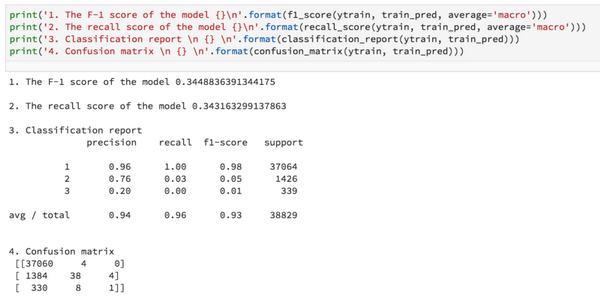
1.使用集成交叉验证的结果:
2.使用集成交叉验证+类别权重的结果:
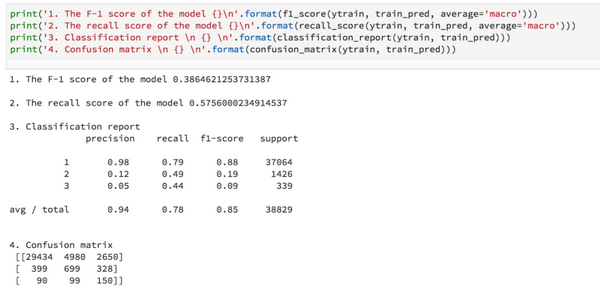
3.使用集成交叉验证+类别权重+过大预测标签的结果:
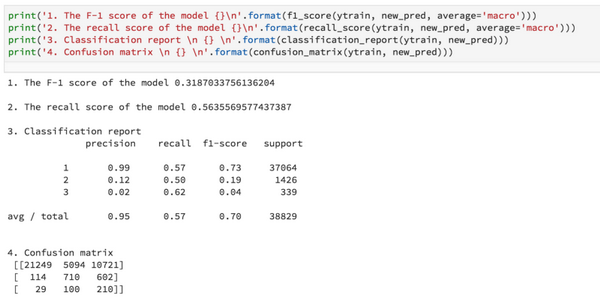
结论
由于在实施过大预测技术方面的经验很少,因此最初的时候处理起来非常棘手。但是,研究该问题有助于提升我解决问题的能力。对于每个任务而言,起初可能确实是陌生的,这个时候不要害怕,一次次尝试就好。由于时间的限制(48小时),无法将精力分散于模型的微调以及特征工程,存在改进的地方还有很多,比如删除不必要的功能并添加一些额外功能。此外,也尝试过LightGBM和XgBoost算法,但在实践过程中发现,随机森林的效果优于这两个算法。在后面的研究中,可以进一步尝试一些其他算法,比如神经网络、稀疏编码等。