【51CTO.com原创稿件】最近一段时间,《创造101》很火,这个火是可以理解的,毕竟这是中国首部女团节目。但是还有一个人不知道为啥突然也火了,那就是我们的菊姐。
关于菊姐为什么会火,网上有很多文章,我就不再赘述了。今天我们就来做一份菊粉陶渊明的用户画像,看看那些 Pick 菊姐的人都有什么特质?
先来看看百度指数,通过百度指数我们看出,菊姐的搜索热度在 5 月 30 开始出现顶峰,5 月 31 开始回落。
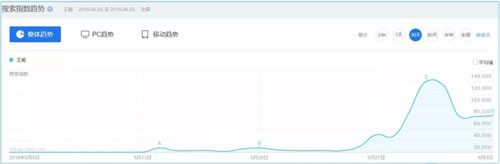
王菊百度指数
再来看看微信指数,与百度指数趋势基本一致,但起伏感要稍强于百度指数。
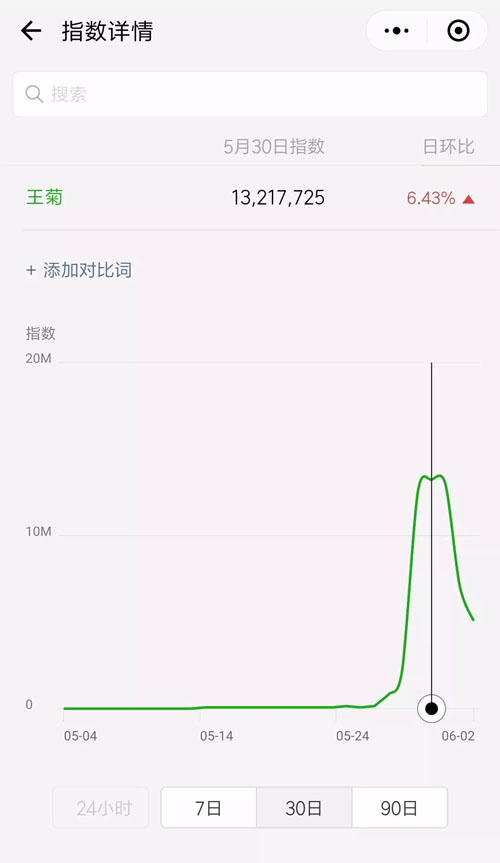
王菊微信指数
我们再来看看菊姐的需求图谱,即与菊姐相关的话题都有哪些。
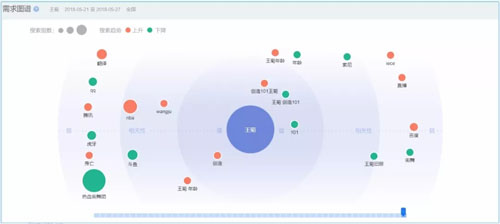
王菊需求图谱
相关词主要有:创造101,王菊,王菊旧照,王菊年龄,看来大家很关心菊姐的个人信息哈,尤其是旧照。
王菊新旧照
看看菊姐以前的照片,再看看现在的,我只想问一句,菊姐这些年都经历了什么?
了解了这些以后,我们切换到今天的主题,菊粉到底都是哪些人?于是我用 Python 爬了菊姐的两万条微博评论,并做了分析!
数据抓取
爬取数据来源于王菊最新微博评论数据,本次数据采集的思路主要是:
- 先获取王菊最新几条(关于创造101话题)的微博评论 url
- 然后依次去遍历每条 url 下面的留言以及 user_id
- 在拿到 user_id 以后再去依次遍历每个用户的基本信息
具体实现代码如下:
#导入所需库
import json
import time
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
import squarify
from matplotlib.patches import Polygon
from mpl_toolkits.basemap import Basemap
from matplotlib.collections import PatchCollection
#获取每条微博评论的url参数
def get_comment_parameter():
url = 'https://m.weibo.cn/api/container/getIndex?uid=1773294041&luicode=10000011&lfid=100103type%3D1%26q%3D%E7%8E%8B%E8%8F%8A&\
featurecode=20000320&type=uid&value=1773294041&containerid=1076031773294041'
c_r = requests.get(url)
for i in range(2,11):
c_parameter = (json.loads(c_r.text)["data"]["cards"][i]["mblog"]["id"])
comment_parameter.append(c_parameter)
return comment_parameter
if __name__ == "__main__":
comment_parameter = []#用来存放微博url参数
comment_url = []#用来存放微博url
user_id = []#用来存放user_id
comment = []#用来存放评论
containerid = []#用来存放containerid
feature = []#用来存放用户信息
id_lose = []#用来存放访问不成功的user_id
get_comment_parameter()
#获取每条微博评论url
c_url_base = 'https://m.weibo.cn/api/comments/show?id='
for parameter in comment_parameter:
for page in range(1,101):#提前知道每条微博只可抓取前100页评论
c_url = c_url_base + str(parameter) + "&page=" + str(page)
comment_url.append(c_url)
#获取每个url下的user_id以及评论
for url in comment_url:
u_c_r = requests.get(url)
try:
for m in range(0,9):#提前知道每个url会包含9条用户信息
one_id = json.loads(u_c_r.text)["data"]["data"][m]["user"]["id"]
user_id.append(one_id)
one_comment = json.loads(u_c_r.text)["data"]["data"][m]["text"]
comment.append(one_comment)
except:
pass
#获取每个user对应的containerid
user_base_url = "https://m.weibo.cn/api/container/getIndex?type=uid&value="
for id in set(user_id):#需要对user_id去重
containerid_url = user_base_url + str(id)
try:
con_r = requests.get(containerid_url)
one_containerid = json.loads(con_r.text)["data"]['tabsInfo']['tabs'][0]["containerid"]
containerid.append(one_containerid)
except:
containerid.append(0)
#获取每个user_id对应的基本信息
#这里需要设置cookie和headers模拟请求
user_agent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36"
headers = {"User-Agent":user_agent}
m = 1
for num in zip(user_id,containerid):
url = "https://m.weibo.cn/api/container/getIndex?uid="+str(num[0])+"&luicode=10000011&lfid=100103type%3D1%26q%3D&featurecode=20000320&type=uid&value="+str(num[0])+"&containerid="+str(num[1])
try:
r = requests.get(url,headers = headers,cookies = cookie)
feature.append(json.loads(r.text)["data"]["cards"][1]["card_group"][1]["item_content"].split(" "))
print("成功第{}条".format(m))
m = m + 1
time.sleep(1)
except:
id_lose.append(num[0])
#将featrue建立成DataFrame结构便于后续分析
user_info = pd.DataFrame(feature,columns = ["性别","年龄","星座","国家城市"])
数据预处理
根据用户基本信息的显示顺序,性别、年龄、星座、国家城市,主要用了以下几方面的数据处理逻辑:
- 对于国家列为空,星座列不空且不包含座字,则认为是国家城市名,则把星座列赋值给国家城市列。
- 对于国家列为空,星座列也为空,年龄列不为空且不包含岁或座字,则把年龄列赋值给国家城市列。
- 对于星座列为空,但是年龄列包含座字,则把年龄列赋值给星座列。
- 对于星座列不包含座的,全部赋值为“未知”。
- 对于年龄列不包含岁的,全部赋值为“999岁”(为便于后续好筛选)。
- 对于国家列为空的,全部赋值为“其他”。
具体处理代码如下:
#数据清洗
user_info1 = user_info[(user_info["性别"] == "男") | (user_info["性别"] == "女")]#去除掉性别不为男女的部分
user_info1 = user_info1.reindex(range(0,5212))#重置索引
user_index1 = user_info1[(user_info1["国家城市"].isnull() == True)&(user_info1["星座"].isnull() == False)
&(user_info1["星座"].map(lambda s:str(s).find("座")) == -1)].index
for index in user_index1:
user_info1.iloc[index,3] = user_info1.iloc[index,2]
user_index2 = user_info1[((user_info1["国家城市"].isnull() == True)&(user_info1["星座"].isnull() == True)
&(user_info1["年龄"].isnull() == False)&(user_info1["年龄"].map(lambda s:str(s).find("岁")) == -1))].index
for index in user_index2:
user_info1.iloc[index,3] = user_info1.iloc[index,1]
user_index3 = user_info1[((user_info1["星座"].map(lambda s:str(s).find("座")) == -1)&
(user_info1["年龄"].map(lambda s:str(s).find("座")) != -1))].index
for index in user_index3:
user_info1.iloc[index,2] = user_info1.iloc[index,1]
user_index4 = user_info1[(user_info1["星座"].map(lambda s:str(s).find("座")) == -1)].index
for index in user_index4:
user_info1.iloc[index,2] = "未知"
user_index5 = user_info1[(user_info1["年龄"].map(lambda s:str(s).find("岁")) == -1)].index
for index in user_index5:
user_info1.iloc[index,1] = "999岁"
user_index6 = user_info1[(user_info1["国家城市"].isnull() == True)].index
for index in user_index6:
user_info1.iloc[index,3] = "其他"
评论多为褒义词
我们抓取了菊姐的最新微博评论,将评论分词以后制作成如下词云图,代码如下:
import fool
from collections import Counter
from PIL import Image,ImageSequence
from wordcloud import WordCloud,ImageColorGenerator
#因留言结构比较乱,所以先保存到本地做进一步处理
pd.DataFrame(comment).to_csv(r"C:\Users\zhangjunhong\Desktop\comment.csv")
#处理完以后再次载入进来
comment_data = pd.read_excel(r"C:\Users\zhangjunhong\Desktop\comment.xlsx")
#将数据转换成字符串
text = (",").join(comment_data[0])
#进行分词
cut_text = ' '.join(fool.cut(text))
#将分词结果进行计数
c = Counter(cut_text)
c.most_common(500)#挑选出词频最高的500词
#将结果导出到本地进行再一次清洗,删除一些符号词
pd.DataFrame(c.most_common(500)).to_excel(r"C:\Users\zhangjunhong\Desktop\fenci.xlsx")
image = Image.open('C:/Users/zhangjunhong/Desktop/图片1.png')#作为背景形状的图
graph = np.array(image)
#参数分别是指定字体、背景颜色、最大的词的大小、使用给定图作为背景形状
wc = WordCloud(font_path = "C:\\Windows\\Fonts\\simkai.ttf", background_color = 'White', max_words = 150, mask = graph)
fp = pd.read_csv(r"C:\Users\zhangjunhong\Desktop\da200.csv",encoding = "gbk")#读取词频文件
name = list(fp.name)#词
value = fp.time#词的频率
dic = dict(zip(name, value))#词频以字典形式存储
wc.generate_from_frequencies(dic)#根据给定词频生成词云
image_color = ImageColorGenerator(graph)
plt.imshow(wc)
plt.axis("off")#不显示坐标轴
plt.show()
wc.to_file('C:/Users/zhangjunhong/Desktop/wordcloud.jpg')
分词没有用 jieba 分词,而是用了 fool,据称是最准确的中文分词包。
GitHub 地址:https://github.com/rockyzhengwu/FoolNLTK

排名前三的热词分别是:“加油”、“哈哈”、“菊姐”,可以看出大家对菊姐的态度大多还是支持的态度。
男女比例 1:2
绘制男女比例的饼图
ax = user_info1["性别"].value_counts(normalize = True).plot.pie(title = "菊粉男女分布",autopct='%.2f')
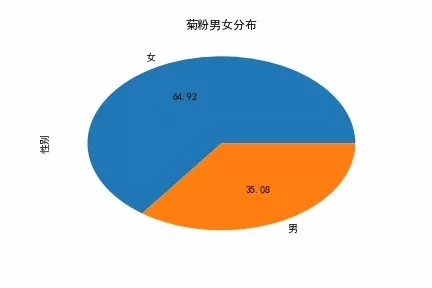
菊粉性别分布
既然是女团节目,按理来说应该男生人数要多于女生的(为什么这么说,大家应该都懂哈),但再想想,菊姐并不是因为长相甜美而走红,那男生比例少一点也就可以理解了。
关于女性,菊姐经典语录:精神独立和经济独立,对于女生而言是很重要的。
有可能是是菊姐的独立女性做自己的形象触动了各位小姐姐的内心。
20-25 岁成中坚力量
#将把年龄从字符串变成数字
user_info1["age_1"] = [int(age[:-1]) for age in user_info1["年龄"]]
#对年龄进行分组
bins = (0,10,20,25,30,100,1000)#将年龄进行区间切分
cut_bins = pd.cut(user_info1["age_1"],bins = bins,labels = False)
ax = cut_bins[cut_bins < 5].value_counts(normalize =True).plot.bar(title = "菊粉年龄分布")#将大于100岁的过滤掉
ax.set_xticklabels(["20-25岁","10-20岁","25-30岁","0-10岁","30+"],rotation = 0)
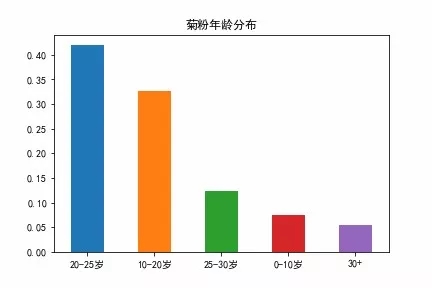
菊粉年龄分布
如上图,还有 0-10 岁的粉丝,比较神奇,不过我更愿意相信这部分是因为用户随意填写导致的。还好只有约 10% 的比例,影响不大。
20-25 岁这一部分开始对新生事物有自己的判断,比较喜欢有个性的东西,对美的定义也是各不相同,可能菊姐的特性在他们眼里就是最美的吧。
还有 30 多岁的大哥哥大姐姐们,看来菊姐的某些特质引发了大哥哥大姐姐们的共鸣。
海外粉丝数位居榜首
#将国家和城市进行分列
country_data = pd.DataFrame([country.split(" ") for country in user_info1["国家城市"]],columns = ["省份","城市"])
#将国家和城市与user表合并
user_data = pd.merge(user_info1,country_data,left_index = True,right_index = True,how = "left")
#按省份进行分组计数
shengfen_data = user_data.groupby("省份")["性别"].count().reset_index().rename(columns = {"性别":"人次"})
#导入解析好的省份经纬度信息
location = pd.read_table(r"C:\Users\zhangjunhong\Desktop\latlon_106318.txt",sep = ",")
#将省份数据和经纬度进行匹配
location_data = pd.merge(shengfen_data,location[["关键词","地址","谷歌地图纬度","谷歌地图经度"]],
left_on = "省份",right_on = "关键词",how = "left")
#进行地图可视化
fig = plt.figure(figsize=(16,12))
ax = fig.add_subplot(111)
basemap = Basemap(llcrnrlon= 75,llcrnrlat=0,urcrnrlon=150,urcrnrlat=55,projection='poly',lon_0 = 116.65,lat_0 = 40.02,ax = ax)
basemap.readshapefile(shapefile = "C:/Users/zhangjunhong/Desktop/CHN_adm/CHN_adm1",name = "china")
def create_great_points(data):
lon = np.array(data["谷歌地图经度"])
lat = np.array(data["谷歌地图纬度"])
pop = np.array(data["人次"],dtype=float)
name = np.array(data["地址"])
x,y = basemap(lon,lat)
for lon,lat,pop,name in zip(x,y,pop,name):
basemap.scatter(lon,lat,c = "#778899",marker = "o",s = pop*10)
plt.text(lon,lat,name,fontsize=10,color = "#DC143C")
create_great_points(location_data)
plt.axis("off") #关闭坐标轴
plt.savefig("C:/Users/zhangjunhong/Desktop/itwechat.png") #保存图表到本地
plt.show() #显示图表
菊粉全国分布
ax = shengfen_data[shengfen_data["省份"] != "其他"].sort_values(by = "人次",ascending = False).head(10).plot.barh(legend = False,color = "#BF0003",title = "菊粉Top10省份")
ax.set_yticklabels(["海外","广东","北京","浙江","上海","四川","江苏","山东","湖北","福建"])
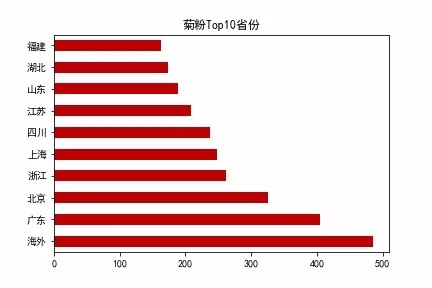
菊粉分布 Top10 省份
这里的海外是指大陆+港澳台以外的其他所有地方。除海外用户以外就北上广的用户最多了,这些地方的互联网用户基数本来就大。
#Top10城市图表绘制
chengshi_data = user_data.groupby("城市")["性别"].count().reset_index().rename(columns = {"性别":"人次"})
ax = chengshi_data[chengshi_data["城市"] != "其他"].sort_values(by = "人次",ascending = False).head(10).plot.barh(legend = False,color = "#BF0003",title = "菊粉Top10城市")
ax.set_yticklabels(["广州","成都","杭州","武汉","长沙","朝阳区","西安","深圳","美国","福州"])
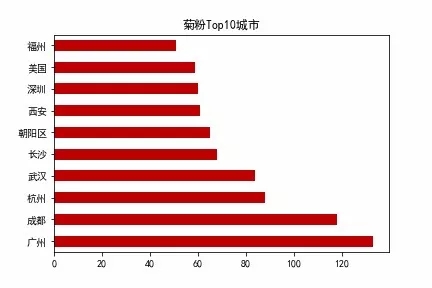
菊粉分布 Top10 城市
因为北京上海比较特殊,北京上海的一些区相当于北京上海这两个省下面的市区,所以你会看到一些北京上海的区域也进入了榜单,比如说朝阳群众。
摩羯座粉丝人最多
#菊粉星座树地图绘制
# 创建数据
xingzuo = user_info1["星座"].value_counts(normalize = True).index
size = user_info1["星座"].value_counts(normalize = True).values
rate = np.array(["34%","6.93%","5.85%","5.70%","5.62%","5.31%","5.30%","5.24%","5.01%","4.78%","4.68%","4.36%"])
# 绘图
colors = ['steelblue','#9999ff','red','indianred',
'green','yellow','orange']
plot = squarify.plot(sizes = size, # 指定绘图数据
label = xingzuo, # 指定标签
color = colors, # 指定自定义颜色
alpha = 0.6, # 指定透明度
value = rate, # 添加数值标签
edgecolor = 'white', # 设置边界框为白色
linewidth =3 # 设置边框宽度为3
)
# 设置标签大小
plt.rc('font', size=10)
# 设置标题大小
plt.title('菊粉星座分布',fontdict = {'fontsize':12})
# 去除坐标轴
plt.axis('off')
# 去除上边框和右边框刻度
plt.tick_params(top = 'off', right = 'off')
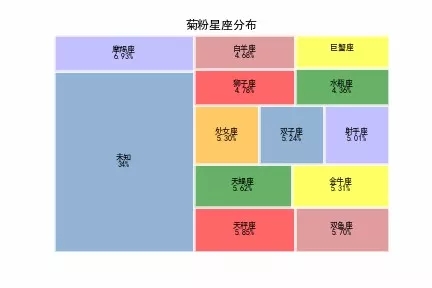
菊粉星座分布
除了未知星座以外,菊姐的粉丝中摩羯座的粉丝最多。我们看看摩羯座都有哪些特性。
摩羯座男性:摩羯座男生特别细心有责任感,对待谁,都会问心无愧,仁至义尽。这是摩羯座整个人生当中的核心信条,只有在做到了自己该做到的事情之后摩羯座才能够坦然的去批评别人,去申述理论,因此摩羯座一直都站在正义的一方和大义的立场上。
摩羯座女性:一板一眼的,戴着厚厚的平底眼镜,梳着中规中矩的头发,就连自己的衣着,也尽量以不突出不惹人瞩目为目标,摩羯座的女生就是这样,貌似不起眼的外表,耐力惊人(怎么感觉是在说菊姐)。
摩羯座可以连续十年作同一件普通简单的事情,只是单一重复仍然感觉乐趣无穷,这样的事情,在别的星座女生看来,简直不敢想象,不过摩羯座却能完成,而且津津有味。
菊姐语录:没有奇迹,只有累积,更是完美匹配了摩羯女十年做同一件事情的坚强毅力。
"陶渊明"究竟是何方神圣
最后将菊粉上面的几个特征综合了做了一个词云图,得到了菊粉的一个大概画像,代码如下:
image = Image.open('C:/Users/zhangjunhong/Desktop/图片1.png')#作为背景形状的图
graph = np.array(image)
#参数分别是指定字体、背景颜色、最大的词的大小、使用给定图作为背景形状
wc = WordCloud(font_path = "C:\\Windows\\Fonts\\simkai.ttf", background_color = 'White', max_words = 150, mask = graph)
name = ["女性","摩羯座","20岁","21岁","22岁","23岁","24岁","25岁","广州","杭州","成都","武汉","长沙","上海","北京","海外","美国","深圳"]
value = [20,20,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10]#词的频率
dic = dict(zip(name, value))#词频以字典形式存储
wc.generate_from_frequencies(dic)#根据给定词频生成词云
image_color = ImageColorGenerator(graph)
plt.imshow(wc)
plt.axis("off")#不显示坐标轴
plt.show()
wc.to_file('C:/Users/zhangjunhong/Desktop/wordcloud.jpg')菊粉画像
通过该词云图可以看出,“陶渊明”主要有以下特质:
- 女性
- 20-25 岁
- 海外、北京、上海、广州
- 摩羯座
关于菊粉陶渊明的用户画像就到这了,关于菊姐你有什么想说的,我们留言区见。
知名互联网公司数据分析师,擅长 Python、SQL、Tableau 等,对机器学习、网络爬虫和数据分析等领域都比较熟悉。个人微信公众号:张俊红(ID:zhangjunhong0428),定期推送机器学习、网络爬虫、数据分析、Python 编程系列文章。

【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】