算法是许多IT公司面试时很重要的一个环节,但也有很多人抱怨实际工作中很少碰到,实用性不高。本文描述了我们公司在面试时常用的一道题目,虽然底层用了非常简单的算法,但却是具体工作中比较容易见到的场景:大规模黑名单 ip 匹配。同时用我们在安全网关中开发的例子来做些验证。
问题和场景
问题:
有海量的 ip 网段名单,需要快速的验证某一个 ip 是否属于其中任意一个网段。
这其实是一个比较普遍的问题,以我们的安全网关为例,至少在以下场景中有需要:
场景一: 单纯的黑白名单匹配
对于网关来说,黑白名单匹配是基本功能:
- 内部 ip 需要白名单 bypass。按照公司的规模和地域所在,这里可能会有大量的白名单。
- 攻击 ip 需要黑名单 block。目前的互联网,各种扫描和攻击还是比较猖獗的,可以很容易的获得大量黑名单 ip,需要进行实时封禁。
- 类似的可以参考 nginx 的黑名单功能,通过 deny 语句 "deny 192.168.1.0/24;" 可以定义一批 ip 网段,用来做访问控制。
场景二: 真实ip获取
真实 ip 获取对有些网站来说其实是一个比较麻烦的问题,因为流量可能有不同的来源路径:
- 浏览器-->网关。这种直接取 remote_address, 即 tcp 的远端地址;
- 浏览器-->lb-->网关。中间可能有别的负载均衡,一般靠 XFF 头来识别;
- 浏览器-->cdn-->lb-->网关。有些流量走了 cdn 或者云 waf,需要对 XFF 头特别处理,识别出 cdn 的 ip;
- 浏览器-->cdn-->lb-->...-->lb-->网关。实际场景中,受到重定向,内部多层网关的影响,可能会有比较复杂的场景。
类似的可以参考 nginx 的真实 ip 功能, 原理也比较简单,通过类似 "set_real_ip_from 192.168.1.0/24;" 的语句可以设置内部 ip 名单,这样在处理 XFF 头的时候,从后往前找,递归模式下寻找第一个不是内部 ip 的值,即真实 ip。这就回归到本文的问题上来。
场景三: 流量标注
这部分功能常由后端的业务模块自行实现,我们在开发产品中希望能在请求进来的时候做一些自动标注,减轻后端的负担,比较有用的如:
- ip 归属地判断。ip 归属地一般是由数十万网段组成的索引,需要进行快速判断;
- 基站标注。目前大量使用 4g 上网,所以基站 ip 必须小心对待,而基站数据也是大量的 ip 网段;
- 云服务器标注。目前较多的攻击来自于云服务器,这些标注对后台的安全和风控业务有协助。云服务器列表也通过海量 ip 网段列表来展现。
以上场景描述了海量 ip 网段列表匹配的一些应用场景,还是比较容易碰到的。
二、算法描述
算法一: hashmap
绝大部分人第一反应是通过 hashmap 来做匹配,理论上可以实现(将网段拆分为独立的 ip),但基本不可用:
- 网段的掩码不一定是24位,可以是32内的任一数字,所以如果要保证普遍性的话,需要完全拆成独立的 ip;
- 哪怕是真实 ip 获取这样常见的场景,我们在客户这边碰到,由于使用了多家 cdn 厂家,cdn 网段有1300+,假设都为24位掩码的 c 类地址,也会有332800+的 ip,做成 hashmap 将是大量的内存开销;
- 由于网关一般是通过多进程或者多实例做水平扩展的,这个内存浪费也会成倍增加。
所以 hashmap 的方式所以查询高效,但在实现层来说不太可行。
算法二: 对网段列表进行顺序匹配
目前可以看到一些开源的实现大都采用这种方式,比如场景段落描述的 nginx 两个功能模块,可以再 accss 模块和 realip 模块发现都是将配置存储为 cidr 列表,然后逐个匹配;另外一个实现是 openresty 的 lua-resty-iputils 模块,这个代码看起来比较直观些:
local function ip_in_cidrs(ip, cidrs)
local bin_ip, bin_octets = ip2bin(ip)
if not bin_ip then
return nil, bin_octets
end
for _,cidr in ipairs(cidrs) do
if bin_ip >= cidr[1] and bin_ip <= cidr[2] then
return true
end
end
return false
end
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
开源的实现在应付绝大多数简单场景足够可用,但后面的测试可以看到,当ip网段数量上升的时候,性能还是欠缺。
算法三: 二分查找
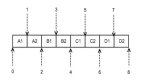
实际的算法其实很简单,二分查找即可,假设这些 ip 网段都是互不相邻的,采用类似 java 的二分查找即可,如图:
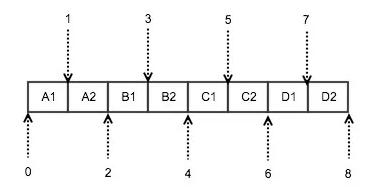
假设有 A, B, C, D 四个互不相邻的 ip 网段,每个网段可以转化为两个数字:起始ip的整型表示和终止 ip 的整型表示;比如 0.0.0.0/24 可以转化为 [0, 255]。这样四个网段转化为 8 个数字,可以进行排序,由于网段是互不相邻的,所以一定是图上这种一个 ip 段接一个 ip 段的情形。这样匹配的算法会比较简单:
- 将被查询 ip 转化为数字,并在数组中进行二分查找;
- 参考 java 的二分实现,当查询命中时,直接返回命中数字的index;当查询未命中时,返回一个负数,其绝对值表示了其插入位置(具体实现需略作变化,这里略过不计);
- 第二步如果返回值为正数,恭喜你,找到了,直接命中;
- 第二步如果返回的为负数,同时插入坐标为奇数(1, 3, 5, 7),说明插入点正好在一个网段之内,说明命中;
- 第二步如果返回的为负数,同时插入坐标为偶数(0, 2, 4, 6, 8),说明插入点正好在两个网段之间,说明此 ip 与所有网段都不命中;
- 证毕收工。
所以整个算法非常简单,不过这里假设了网段之间是互不相邻的,这个很容易被忽视掉,下面做一些简单说明。
任意两个网段 A 和 B,可能有三种关系:
- 完全不相邻。A 和 B 没有任何重复的部分。
- 相包含,即 A 包含 B 或 B 包含 A。这种情形在数据预处理的时候可以发现并排除掉(只保留大的网段)。
- A 和 B 相交,但并不包含。即两个网段存在相互交错的情形,下面通过图形说明此种情况不成立。
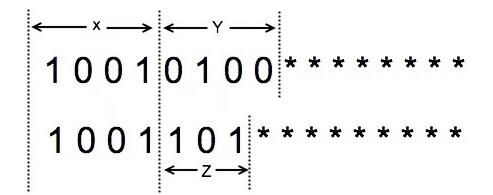
上图描述了任意两个网段:
- "*"表示掩码
- 两个网段,共32位,其中子网部分,前面 X 个连续 bit 是相同的
- 第一个网段剩余 Y 个 bit,第二个网段剩余 Z 个 bit
所以:
- 假设 Y == Z == 0, 表示两个网段完全相等,否则
- Y == 0 && Z != 0, 说明第一个网段包含第二个网段;Y != 0 && Z == 0, 则第二个网段更大
- Y != 0 && Z != 0,就是图上的直观表示,由于网段中的 ip 只能是*号部分的变化,所以两个网段不可能有相同的 ip,因为中间至少有几位是不同的
因此,如果对原始数据进行一定的预处理,二分查找是安全有效的方式。
三、测试数据
最近手机出的有点多,我们也跟风跑个分:
- 测试采用 Raspberry Pi 3 Model B, 4核 1.2GHz CPU, 1G 内存。
- 通过 wrk 进行持续30s,50个连接的性能测试。
测试一: 基准测试
Running 30s test @ http://10.0.0.5/
12 threads and 50 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 6.54ms 4.80ms 194.75ms 99.29%
Req/Sec 617.22 56.76 1.05k 80.42%
Latency Distribution
50% 6.22ms
75% 6.99ms
90% 7.78ms
99% 10.74ms
221915 requests in 30.10s, 40.62MB read
Requests/sec: 7373.42
Transfer/sec: 1.35MB
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
测试二: 10000个黑名单+hashmap
Running 30s test @ http://10.0.0.5/block_ip_1w
12 threads and 50 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 7.75ms 2.34ms 94.11ms 85.57%
Req/Sec 512.72 68.86 780.00 74.28%
Latency Distribution
50% 7.21ms
75% 8.36ms
90% 10.63ms
99% 14.07ms
184298 requests in 30.09s, 32.16MB read
Requests/sec: 6125.35
Transfer/sec: 1.07MB
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
测试三: 10000个黑名单+lua-resty-utils 模块顺序查找
Running 30s test @ http://10.0.0.5/block_iputils_1w
12 threads and 50 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 162.93ms 100.27ms 1.96s 95.22%
Req/Sec 27.47 12.28 150.00 66.46%
Latency Distribution
50% 155.88ms
75% 159.40ms
90% 161.54ms
99% 670.13ms
9164 requests in 30.09s, 1.60MB read
Socket errors: connect 0, read 0, write 0, timeout 11
Requests/sec: 304.52
Transfer/sec: 54.41KB
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
测试四: 10000个黑名单+二分查找
Running 30s test @ http://10.0.0.5/block_ipcidr_bin_1w
12 threads and 50 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 9.60ms 6.78ms 196.80ms 97.53%
Req/Sec 427.92 82.80 0.89k 60.15%
Latency Distribution
50% 8.45ms
75% 10.94ms
90% 12.55ms
99% 18.58ms
153892 requests in 30.10s, 26.85MB read
Requests/sec: 5112.69
Transfer/sec: 0.89MB
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
通过测试数据,可以看到二分搜索可以达到接近于基于 hash 的性能,但内存消耗等会少很多;而简单的顺序遍历会带来数量级的性能下降。
【本文是51CTO专栏机构“岂安科技”的原创文章,转载请通过微信公众号(bigsec)联系原作者】