













内存计算那点事
迄今为止,内存还是我们目前能用到的最快的存储设备,把数据尽可能放进内存成为各种应用提高数据访问性能的最有效途径。对于很多关键业务系统而言,内存又是一种“挥发性”的和大小非常有限的存储设备,如何在保证性能的同时使数据能持久化,如何把有限的内存投入到***的待处理数据上是程序设计的一个重大课题。
Oracle的内存TimesTen内存数据库为有高并发,低延时和高可用要求的关键业务系统提供了一个接近***的解决方案:把数据放进内存,使用SQL简化开发,应用开发者可以更加专注在业务实现上而不用关心底层的内存分配。TimesTen在大并发的环境中还能提供媲美Oracle数据库的数据完整性,一致性和可恢复性,内存的“挥发性”缺点也被克服,维护工作也极大地简化了。因此Oracle TimesTen被广泛地应用于电信,金融等行业已经有20多年的历史。
基于内存计算的另外一个问题始终困扰着业内人士——内存有限而数据相对***:单一服务器的内存远远不足以存储需要处理的数据,频繁的内存交换消耗太多资源,用户不得不使用手工分库的方式把数据分散到多个服务器上来处理,这又带来了管理、开发复杂,扩展性差等诸多问题。
随着技术的发展,分布式内存网格技术也开始被用于加速数据访存的速度,比如Redis,Oracle Coherence等。分布式内存网格技术采用key-value的内存数据存储方式可以方便把磁盘型数据库的数据分布到集群系统的各个节点上缓存,为简单的数据查询和事务提供了很高的性能。但这类技术的问题是:数据的强一致性,数据持久化,复杂报表和统计,大并发事务处理等。
分布式的关系型内存数据库——理想的内存数据库
对于一个高并发,实时响应需求的关键业务系统而言,一个分布式的关系型数据库是最理想的选择:它既具有关系型数据ACID的特性,可以处理高并发的用户请求,可以实时响应业务的数据访问请求,拥有完善的备份恢复和容灾机制,同时和NoSQL的内存网格技术一样,可以把需要处理的数据分散到一个集群上的所有节点上,可以根据需要扩展集群中的数据处理节点。今年5月初,Oracle分布式内存数据库——这个理想中的,综合了内存计算,分布式处理,关系型数据库的分布式内存数据库终于正式推向市场。
TimesTen 18.1 Scaleout的特点
Oracle的分布式内存数据库使用了已经20多年历史的TimesTen的内核来构建,正式发行版为被称为TimesTen 18.1 Scaleout,版本号的含义为2018年的***个主要发行版。
首先TimesTen 18.1 Scaleout是一个严格意义上的关系型数据库;它拥有和Oracle 数据库一样的ACID特性,比如:事务的原子性和持久性,事务的提交和回滚,基于版本的并发控制,读写操作互不阻塞等等。
其次,作为一个分布式的内存数据库它是一个逻辑上单一,物理上分散的分布式内存数据库,TimesTen 18.1 Scaleout中的数据分散存储到数据库集群的各个节点中,应用从任何一点接入数据库都可以访问到全部数据,应用不需要知道数据存放的位置。这一点也不同于市场上的分片式数据库,这样的设计极大地简化了应用开发和数据库管理的难度。
TimesTen Scaleout的几个基本概念
一组内部互联的运行Oracle TimesTen Scaleout的服务器我们称为一个Grid,运行中TimesTen Scaleout代码称为实例,TimesTen Scaleout的实例又分为数据实例和管理实例,数据实例的的概念和Oracle数据库的实例是非常类似的,它包括数据缓存和后台进程。
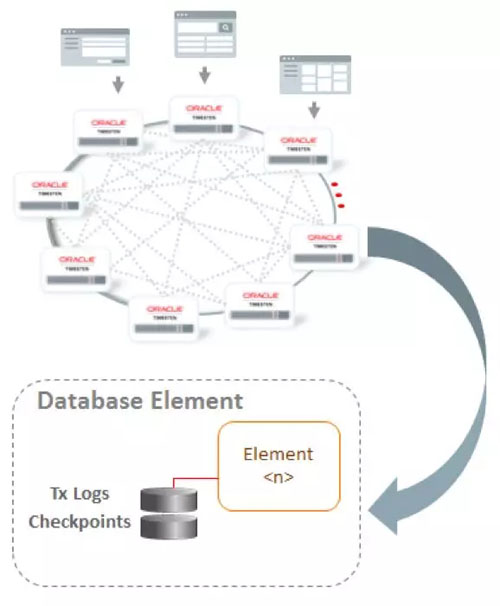
每个TimesTen Scaleout数据实例包含一个我们称之为Element的数据持久化最小的单位,Element拥有整个数据库中一部分数据和这个数据库中完整用户信息和 schema信息;每个element有自己的持久化检查点文件和事务日志文件, Element可以使用副本来实现高可用性和容灾。
在一个集群中,一般配置有1到2个管理实例来跟踪监控整个集群的运行状态。
数据分布的方式
那么如何把所有数据分配到每一个Element中呢?通常来说有以下方法:
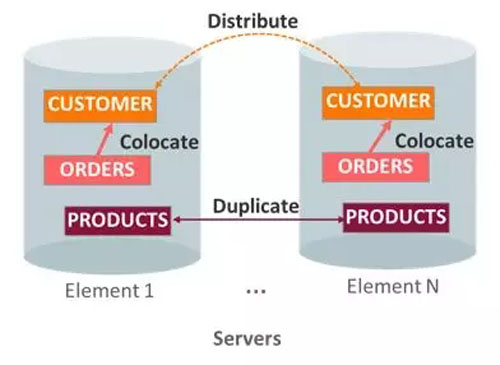
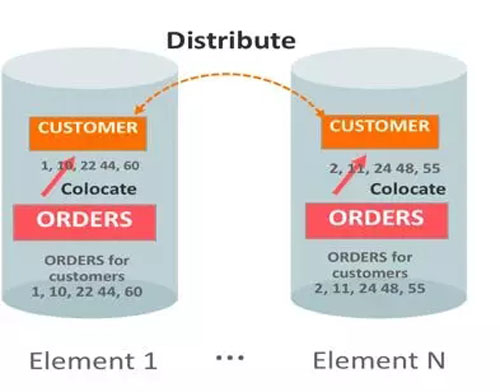
- DISTRIBUTE
基于一致性哈希算法分布,通常用于大数据库表,比如:基于Cust_ID 的哈希值,比如我们把CUSTOMER表中各行分布到所有elements 当中可以使用如下语句:
- CREATETABLE CUSTOMER (
- ID NUMBER NOT NULL PRIMARY KEY,
- NAME VARCHAR2(100),
- …
- ) DISTRIBUTE BY HASH;
- REFERENCE
子表与父表相关联的行共存于相同element,优化本地事务将 ORDERS 表中与CUSTOMER相关联的行存放于相同element当中。
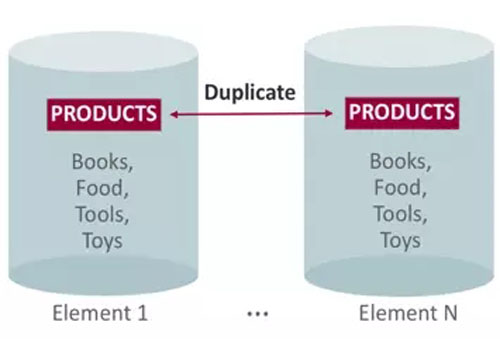
- DUPLICATE
查询为主的小表在每个element存放完整数据,优化本地事务。如将 PRODUCT 表在所有 elements 当中都存一份全量数据,这种情况适用于比较小的,同时变更不是很频繁的表
高可用的实现
前面提到了TimesTen 18.1 Scaleout是通过Element的多副本方式实现高可用性的,这种机制称为K-Safety(K>1),见下图:
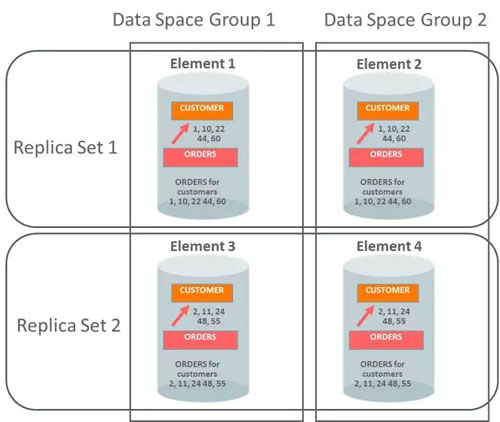
一个完整的数据集称为Data Space, 它包含这个数据库所有的Elements,上图的Dataspace Group1 包含的Element 1和Element 3 构成了一个完整的数据库。拥有相同的Element的集合被称为Replica Set,它们互为对方的拷贝,比如上图的 Replica Set1包含的Element 1和Element 2,它们位于不同的机器上从而实现数据的高可用性。
互为拷贝的Element是双活的,也就是说应用可以在其中任意一个Element上发起读写的事务操作而不相互影响,数据库系统负责这两个Element的数据同步。
在这种架构下,即使多个Element发生异常,只要有一套完整可用的副本对应用就不会有影响。如果整个replica set 发生异常,应用也可以选择接受只返回剩余数据的结果集。
集中化安装与管理
TimesTen 18.1 Scaleout的管理操作都均可通过一个主机用图形界面或者命令行的方式通过一个接入点完成集群地所有操作,包括:
- 软件安装
- 补丁应用
- 配置管理
- 数据库创建与管理
- 数据库监控
- 备份与恢复
- 日志搜集
Oracle的几种内存缓存技术的比较
随着TimesTen 18.1 Scaleout的推出,Oracle进一步完善了实时内存数据处理的拼图,传统的面向OLTP的TimesTen也升级了到了18.1,这个版本称为TimesTen 18.1 Classic。让我们看一下他们之间使用场景有什么不同:
1.TimesTen18.1 Classic
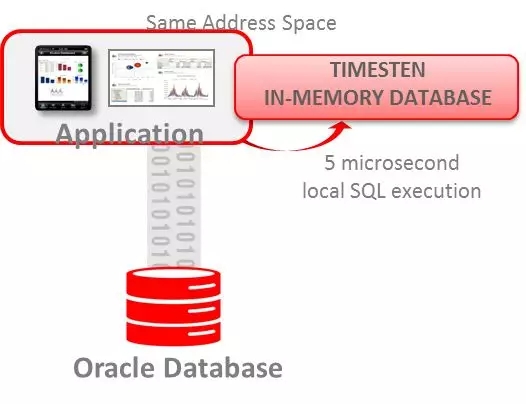
使用场景: 用于实时,准实时的OLTP系统加速。如果TimesTen18.1 Classic的机器内存足够存放需要处理的数据,TimesTen 18.1 Classic可以提供更高的数据处理实时性。
部署:可以单独运行或者作为Oracle数据库的缓冲,使用CacheGroup 或者其它方式和Oracle数据库同步数据。
2.TimesTen 18.1 Scaleout
使用场景:分布式、容错、弹性伸缩的关系型内存数据库 ,用于高并发,低延时的OLTP 为主的关键业务系统;单机内存无法存放需要实时处理处理的全部数据,不得不手工分库的场景。
部署:使用服务器集群部署。
3.Oracle Database In-Memory Option
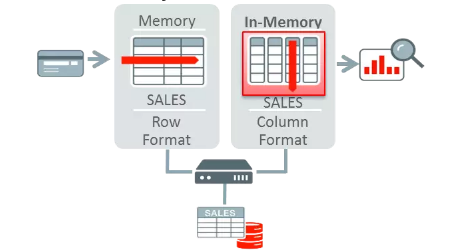
使用场景:Oracle12.1.02数据库引入的数据列式内存技术,主要用于加速数据分析和报表的速度。
部署:用户可以把数据库中需要做分析和报表的数据库表加上列式内存存储的选项,数据会在数据库启动或者***次查询这个表的时候把数据以列式或者列式压缩的方式缓存到Oracle数据库的SGA区的In Memory Area中:优化器会自动优化SQL的访问路径,让需要访问列式内存数据的SQL从In Memory Area中获取数据。
4.Oracle Coherence
使用场景:Oracle Coherence是分布式内存网格技术,一般用于中间层数据访问加速。
部署:数据以Key Value的方式存放在内存中,使用RESTAPI访问。
总结
在大数据和云时代,实时数据处理有多种方式,Oracle 提供了多种内存技术的产品和技术加速数据访问和处理的速度,这次TimesTen 18.1 Scaleout的推出进一步完善了Oracle 内存计算产品家族,它继承了久经考验的TimesTen内存数据库的内核,又吸收了No SQL数据库的一些设计理念,必将在很多对实时数据处理有很高要求的关键业务系统上得到应用。




















