性能测试对于大部分测试人员都是一个神秘地带,因为在很多公司,性能测试都是由一个性能测试团队来做,所以普通测试人员没有机会接触到真实的性能测试,因而很难学习到很多新的测试实践知识。
市面上现在有非常多关于性能测试的书籍,其中不少书籍都能够系统地介绍性能测试。今天我想通过另一种方式来介绍性能测试,那就是通过提出一些关于性能测试的问题,然后针对问题进行思考。希望通过不一样的方式让读者以另外一种视角来思考和学习性能测试实践。
1. 如何在敏捷开发中做性能测试?
敏捷开发,由于其持续集成、快速反馈等特点,需要性能测试工具支持轻量化、集成CI服务器、全代码化等特性,所以传统的性能测试工具比如JMeter和LoadRunner等已经很难适用于敏捷开发。在敏捷开发中,性能测试应该需要具有以下特点:
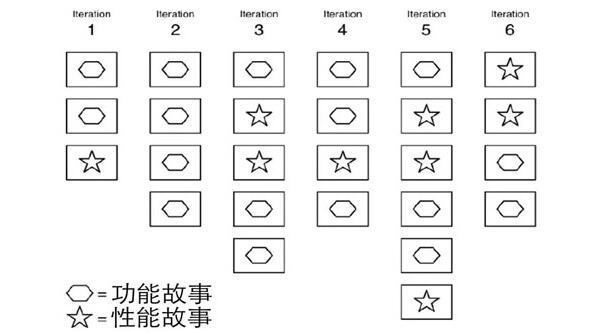
(1) 性能测试是持续集成和持续发布的一部分,尽可能早的发现性能问题,从而降低修复成本。这样可以使得很多性能问题在开发过程中被持续的尽快发现。建议将性能测试写成故事放到每个迭代里面去,见下图:
(2) 性能测试脚本易读,易维护。比如代码化的脚本Gatling,Locust等。下面是Gatling的DSL示例代码:

(3) 可视化,报表易读,每个人都能及时了解状况 。下图为Jenkins集成了一个Gatling插件后所展现的Gatling持续测试报表。
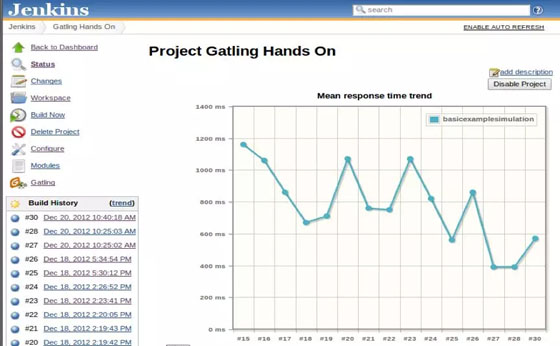
通过在敏捷开发中做持续的性能测试,使得性能测试也可以:小步快跑->快速反馈->持续改进->持续交付。
2. 如何通过数据分析更有效的做性能测试?
大部分情况下大型项目的性能测试需要的时间和人力都非常高,因为:
- 用户并发要求高,测试硬件成本高
- 测试功能点多,测试量大
- 耐久性测试,测试时间长
其次是测试的有效性差,因为测试人员在测试环境中很难模拟真实用户的操作,比如访问的顺序分布,访问的强度分布以及用户端的各种访问参数。
为了解决这两个问题,应该通过用户数据分析来获得真实的用户行为数据,并用其来构造性能测试用例,其中可以用下面这个漏斗模型来进行思考:
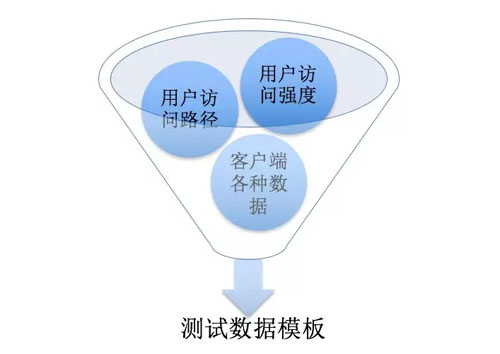
通过这个漏斗模型可以知道,为了快速得到真实有效的性能测试数据模型,需要通过筛选并整合真实的用户数据,而并不是靠测试人员在实验室中想象出来的数据。
那如何进行用户行为分析呢?下面尝试用三个例子来进行说明。
***个例子是一个用户注册流程,通过用户行为的数据分析可以得到每个功能点上用户的访问量。见下图:
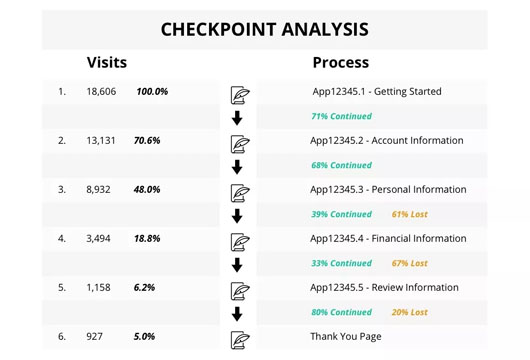
图中展示了用户注册流程的6个步骤,分别是:
- Getting Started
- Account Information
- Personal Information
- Financial Information
- Review Information
- Thank You Page
其中***个步骤有18606次访问,然后有71%的访问用户选择继续,但是只有13131(70.6%)到达了第二个步骤。最终只有925(5%)的用户完成了注册。由此可以知道不同步骤的真实访问比例,从而得到性能测试的数据模型和策略。
第二个例子是用户使用的浏览器的数据统计,如果性能测试需要模拟不同的浏览器,那么这些数据分析结果也可以用以确定浏览器在性能测试中的权重。
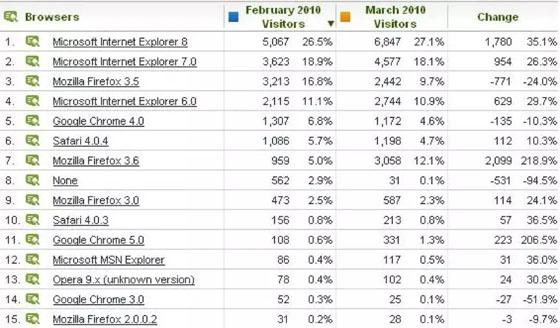
通过这个统计表可以知道使用IE浏览器的用户最多,所以在生成性能测试数据的时候应该多生成一些基于IE浏览器的数据,比如User-Agent等。
第三个例子是统计的用户访问地区,对于有些大型的互联网应用是需要进行多地区模拟来测试不同地区互相访问时的性能。这个数据统计结果可以帮助其设计更有效的这类性能测试用例。
通过这个统计表可以知道英国的用户访问量最多,而美国的访问量第二。如果应用服务器部署在美国,那么就应该尽可能的在英国架设测试服务器,通过在英国的测试服务器来测试美国的应用服务器,从而测试跨国网络的性能,并且还需要在产品环境检测英国到美国的网络性能,从而及时发现性能问题。
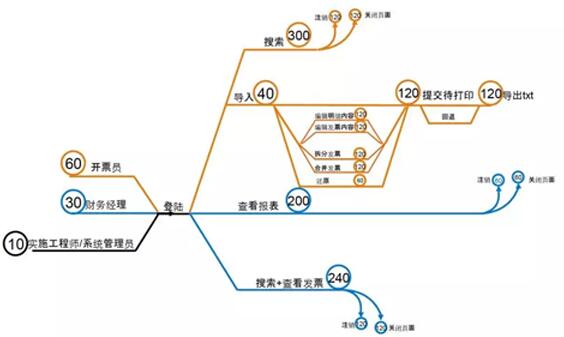
通过对这些真实用户数据的分析,可以设计更有效的性能测试模板,下面是一个性能测试模板的样例,其中每个功能点上圆圈中的数字代表这个功能点在真实环境中的用户访问权重。权重越大的功能点在整个性能测试模板中应该测试量更大,所花费的成本更高。
常见的Web系统用户数据跟踪与分析工具有:
- Adobe SiteCatalyst:功能强大,使用繁琐,收费(贵)
- Google Analytics: 功能较强,使用方便,免费和收费
- 百度统计/腾讯分析:功能一般,免费
使用数据分析来生成数据模型的流程如下:收集数据->分析数据->生成测试数据模板->使用数据模板。
3. 对大规模集群系统做性能测试应该注意什么?
通常中小型公司的IT系统都不使用大规模的集群,而只有大型公司才会大规模使用集群,导致很多测试人员没有机会实践和了解基于集群的性能测试。如果想学习基于集群的性能测试,除了常规的测试集群系统性能以外,还可以从以下几个方面进行思考,从而学习基于集群系统的性能测试:
- 测试环境的真实性,由于大规模集群包含很多节点和服务,所以搭建和产品环境一样的测试环境的成本很高,导致测试环境的规模一般都比产品环境小很多。那测试这样的测试环境还有什么意义?
- 一般集群都会使用负载均衡,但是由于存在多种负载均衡算法和配置,那么怎么才能保证负载均衡功能是按照设计和配置的进行工作?
- 除了对集群系统进行整体的性能测试外,还需要单独对不同的服务和节点进行性能测试吗?
所以针对集群系统做性能测试不仅仅能测试系统的性能,还可以解决以上三个问题:性能规划,配置测试,隔离测试。
(1) 性能规划
对于一个大型的服务器应用系统,一般情况下都是由规模化的集群组建而成的。所以测试这类基于集群的服务器系统的时候,也需要将测试环境配置成和产品环境类似的集群系统。不过因为成本的原因,测试环境中的集群规模大都要小很多。可以通过测试小规模的集群,然后使用其测试结果,并通过数学建模推算产品环境的性能或者对产品环境进行性能规划。由于每个集群系统拥有各自不同的架构,配置和服务,所以其数学模型也是不同的。
(2) 配置测试
通过更改集群系统的各种配置,并在不同的配置下对集群系统进行性能测试,从而获得***配置。比如辅助开发人员完成集群功能的开发与验证,比如负载均衡算法,热备等;以及辅助运维团队配置和调试产品环境的集群配置等。
(3) 隔离测试
对于集群系统的服务或者节点,开发这些服务的团队应该在隔离(stub)第三方依赖的环境下,各自对自己团队开发的服务进行独立的性能测试。从而尽早发现性能问题,尽早修复,避免在集群环境下发现同样的问题,增加调试和时间成本。
大规模集群系统基本都是复杂架构,环境也都是较为复杂的组织结构,而只有深入理解整个业务流程,系统架构以及环境结构才能有效地设计测试方案。
4. 性能测试中的测试数据有几种类型?
测试数据一直是软件测试中的一个头疼的问题,特别是在性能测试中测试数据尤为重要,因为越真实的数据越能获得更好的结果。对于测试数据的类型可以分为以下四种:单一型,随机型,模板型,真实型。
(1) 单一型
它是通过录制或者观察,使用一个或者一类单一的测试数据来进行性能测试。这种数据的构建简单,但是数据过于单一,无法模拟真实用户。由于其数据构建简单,所以可以用于敏捷开发中的早期性能测试。
(2) 随机型
它是通过一些简单的数据规则,并结合随机算法生成的测试数据。这种数据和单一型比较,虽然增加了随机性,但是仍然缺乏真实性,并且其构建成本和性能问题的分析成本也相对较高。它可以用于上线前的大规模的多样化的综合性能测试。
(3) 模板型
它主要是通过数据分析并生成模板来构建测试数据。虽然它较随机型在一定程度上增加了用户真实性,但是准备数据的成本很高。在项目成本和资源允许范围内,可以结合模板型和随机型的方法,从而更为有效的进行性能测试。
(4) 真实型
它是通过直接导出或者重定向产品数据来做性能测试数据。它完全是真实的用户数据,构建成本较低,但是存在数据安全性的问题,比如数据泄露。在数据安全性可以得到有效保护的情况下是可以使用真实型数据来进行性能测试。
测试数据生成和管理对于一个大型项目的性能测试是十分重要的,所以如何高效的生成有效的测试数据成为了首要的任务。通过这四种测试数据类型,可以快速的判断在项目当前阶段适合使用那种类型的数据,从而避免一些弯路。
5. 其他问题
除了以上问题和思考,我还准备了一些其他的基本问题给读者自己去思考,从而通过思考问题来学习性能测试。
- 性能测试主要包含哪些类型以及分别的作用是什么?
- 前台页面的性能测试应该注意哪些问题?
- 对于并发用户很少但是稳定性要求很高的系统需不需要做性能测试?为什么?
- 对于后台有大量异步批处理需求的系统应该怎样进行性能测试?
- Profiling是不是性能测试?什么时候应该做它?
- 常见的性能测试工具有哪些?怎么选择性能测试工具?
- 如果测试环境和产品环境的硬件配置不同,如何通过测试环境的测试结果评估产品环境的性能?
- 在设计性能测试用例时需不需要考虑Think Time?
- 中小型项目的性能测试都需要注意些什么?
- 性能需求的来源有哪些?
- 如何使用云服务进行超大规模性能测试?
【本文是51CTO专栏作者“ThoughtWorks”的原创稿件,微信公众号:思特沃克,转载请联系原作者】