对分布式数据库感兴趣的朋友都知道,谷歌的 F1 和 Spanner ***了 NewSQL 技术的发展,于是很多公司去做 NewSQL,导致好多人认为基于 MySQL 的分布式数据库过时了。
其实不然,MySQL 并没有过时,本篇文章的主角 —— RadonDB ,就是把 NewSQL 领域比较流行的分布式一致性算法和 MySQL 结合起来,形成了新一代的分布式数据库 MyNewSQL,同样做到了可扩展、高可用、强一致、易部署的特点。
那么,如何将 NewSQL 领域比较流行的技术和 MySQL 结合起来,打造一款新的分布式数据库?
1、RadonDB 的架构
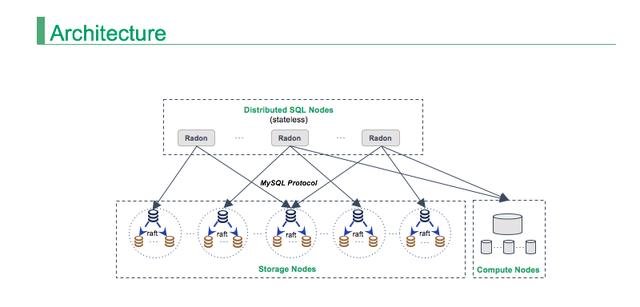
首先看一下 RadonDB 的架构,如上图所示,上半部分是分布式的 SQL 层,下面是存储层,如果我们对 F1 和 Spanner 进行抽象之后,会发现也都是这两层。
其中 SQL 层主要负责对用户 SQL 解析,然后生成分布式的执行计划和执行器,再把这些执行器下发到具体的存储节点去执行。
虽然架构看上去比较一致,但 RadonDB 比较特殊的一点是:下面的存储层有多个存储节点。图中每个圆圈里面都是一个存储节点,每个存储节点有三副本,三副本之间就是一个 Raft 协议进行数据同步,每个副本都是一个 MySQL。而其他 NewSQL 就是一个 KV 或者其他的存储。
2、RadonDB 架构层解析
下面详细阐述一下架构里面的各个技术点。
SQL 节点
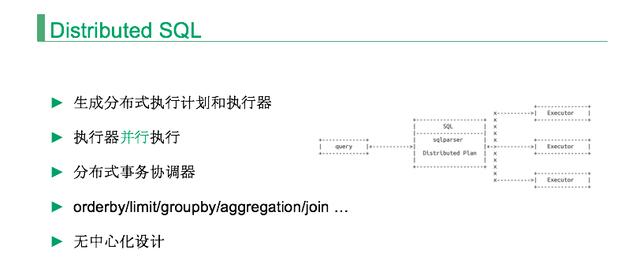
首先来看一下 SQL 节点。
用户请求到达 SQL 节点后,我们根据数据的分布规则生成一个分布式的执行计划,告诉用户的 SQL 要分发到哪些存储节点,然后根据分布式执行计划生成一个分布式的执行器,就是具体到哪些存储节点进行链接、执行、返回。
执行完之后 SQL 节点就会做二次运算,为什么叫二次运算?因为下面是 MySQL,SQL 节点把计算推到 MySQL 之后,SQL 节点再进行二次运算,包括 limit/groupby/aggregation/join。
所以说,SQL 节点是一个无中心化、无状态的,扩容性强。
3、存储层
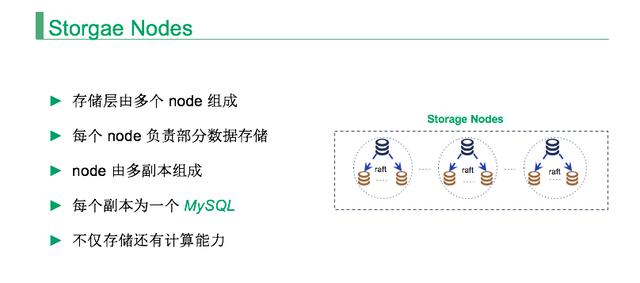
存储层由多个 Node 组成,每个 Node 就是一主两从的 MySQL,但这个 MySQL 比较特殊,因为 MySQL 没有一个高可用的方案,可能大家都是 MHA 或者自己写一个主从切换脚本来运维。
但是 RadonDB 引入了 Raft 协议,它是无中心化的, 当主库挂了后,通过 Raft 协议选择新主,而数据同步则基于 MySQL GTID 机制。
基于 MySQL 的好处是不仅有存储能力还有计算能力,如果一个副本只是一个 KV ,他的计算能力就比较有限,SQL 层把数据推到存储层,然后再返回 SQL 节点再进行运算,这样存储层和 SQL 层交互就会比较多。
我们尽量把计算能力下推到存储层让 MySQL 完成,因为 MySQL 跟数据是在一块的,不涉及网络传输,只需要几个 I/O 就将数据过滤掉了。
4、数据分布
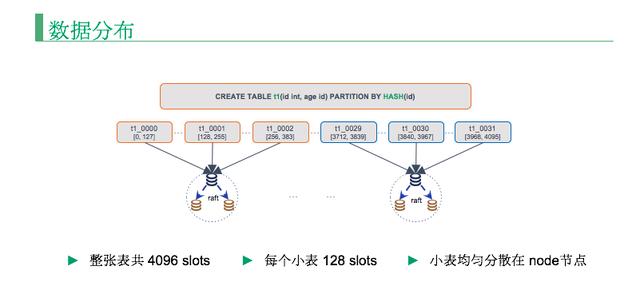
刚才说了 SQL 层和存储层,再看一下数据怎么分布?
建一个 T1 表,后面指定的分区方式是 HASH,在 RadonDB 里面默认整张表共 4096 slots, 每个小表默认是 128 slots, 其实就是一个大表分成 32 个小表,比如两个存储节点,这个 T1 表的 32 个小表,前 16 个小表在***个存储节点上,后 16 个小表是在第二个节点上,是均分布的。
可能很多人认为基于 MySQL 扩容是个问题,但是如上所说,表分完之后,RadonDB 以小表为单位做数据迁移,所以扩容非常方便。如果是加了一个新的节点,RadonDB 就会把动态的一些小表迁移到新的节点上,因为我们是基于 MySQL 做的,首先会做一个全量,然后把位点记下来,等全量做完再追增量,这个迁移过程基本不影响业务了。
所以这样每个小表就可以在多个存储节点上动态的漂移。这些迁移规则也可以进行自定制,比如说先迁移较大的表或者热度比较高的表,让整体资源分配最快达到***化。
5、如何保障高可用?

一个存储节点内三个副本怎么保证高可用的?我们将分布式一致性算法 Raft 和 MySQL 自身的 GTID 结合起来。
Raft 主要做两件事,一个是选主,第二个是数据同步。MySQL 5.7 GTID,类似于 Raft 里面的一个 log index, 数据同步是通过 GTID,选主是通过 Raft,我们开发了一套 Raft 框架,实时监测 MySQL 状态,如果主不正常了,就发起重新选主。
选完后新主与其他两个从库数据怎么同步呢?两个从根据自己的 GTID 向主那去拉数据,进行数据同步。MySQL 5.7 可以并行复制,过程非常迅速,主从基本没有延迟,在高压情况下延迟也非常小。而且,通过比较强的 semi-sync 确保事务不丢失。
存储节点里 Raft 和 GTID 是没有中心化的,可以跨机房部署,非常灵活。
6、分布式事务
下面看一下分布式事务,为什么分布式数据库需要分布式事务呢?
因为数据在存储节点是分布式存储的,比如说一个表在节点 1、节点 2、节点 3 都有存储,然后执行了一个操作,在节点 1 成功了,在节点 2 失败了,节点 3 成功了。这时如果没有分布式事务,那这个表其实是坏的。
如果没有分布式事务保证的话,数据随时都处于不可用的状态,只能用来存不重要的业务。
所以 RadonDB 就提供了分布式事务,比如说刚才这个情况,就是 2 失败之后,这个 1 和 3 存储节点自动回滚,这是分布式事务保障。
RadonDB 分布式事务也是基于 MySQL 实现的,在 MySQL 里面分两阶段提交。
首先它会做 xa start,然后执行 SQL,做 xa end,第四做 xa prepare,这是***阶段,此时事务才会从副本复制过去;第二个阶段是 xa commit。
所以 RadonDB 在 SQL 层进行了事务管理,把 MySQL 的五个步骤抽象成三个,***是 Begin,第二是执行,第三是提交,如果 Prepare 失败,可以进行 Rollback。
提到分布式事务,大家可能会问,这个事务是什么隔离级别?
RadonDB 实现 Snapshot Isolation 也就是快照隔离级别,这是个什么概念呢?当部分分区没有提交时,这个事务对其他事务不可见,这就是部分提交不可见。另外就是未提交不可见,也就是说做了 prepare,但没有 Commit,那也是不可见的。
7、SI 隔离级别

大家可以看一下上图右边两个 SQL 语句,两个 Client 连上来,一个 Client 是扫表,第二个 SQL 语句就是不停更新这个表。
对于 SI 隔离级别我们用了 XeLabs/go-jepsen ,1 个更新线程,16 扫表线程,通过 100 多亿次操作和监测没有发现问题,并且可以随机 KILL 存储节点主副本,这些都证明 MySQL XA 已经很强大了。
RadonDB 还支持 HTAP 混合模式,在传统的解决方案里,一般都是两套系统,就是两个端口。在需要事务和需要分析的时候,分别在两个端口处理,中间通过ETL通道进行数据同步。
但是,在 RadonDB 里就一个端口,如果是 OLAP 的操作,我们会自动路由到计算节点,而且 OLTP 和 OLAP 这两个计算的资源是隔离的,互不影响。
8、性能
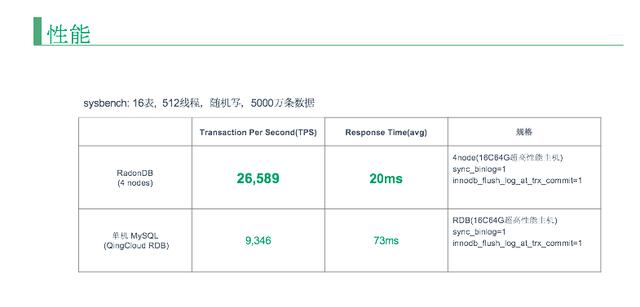
***看一看 RadonDB 的性能。上图是单机 MySQL 和四个存储节点的 RadonDB 的对比。
我们用 sysbench 16 个表、512 个线程,随机写了 5000 万条数据,测试得出来的结果,RadonDB 基本上可以做到 26589 TBS,单机是 9346 TBS,可以看到在 TBS 层面 RadonDB 性能将近是单机的三倍,延迟却只有的三分之一。
这就是分布式数据库的威力,性能和容量可以通过节点的增加而线性增长。
作者简介
张雁飞,青云QingCloud 数据库高级技术专家。TokuDB 内核贡献者、维护者,TokuDB 企业级热备工具作者。