日前,伯克利发布了迄今***、最多样化的带有丰富注释的驾驶视频数据集 BDD100K。大家可以访问 http://bdd-data.berkeley.edu 获取该数据集。同时,他们也在 arXiv 上发布了关于该数据集的报告,大家也可以利用该数据集参加他们主办的的 CVPR 2018 挑战赛。
关于该数据集的详细信息整理如下:
自动驾驶将随时改变社区中人们的生活方式。然而,最近发生的一系列事故表明,当在真实世界使用驾驶系统时,尚不清楚这种人造感知系统如何避免看起来非常明显的错误。
作为计算机视觉研究人员,我们对探索自动驾驶的前沿感知算法非常感兴趣,我们想让自动驾驶更加安全。为了设计和测试具有潜力的算法,我们想要利用真实驾驶平台收集的数据信息。这种数据有四个主要特性:大规模、多样性、在道路上收集、具备时间信息。
数据多样性对测试感知算法的鲁棒性尤为重要。然而,当前的开放数据集并不能涵盖到上面描述的所有属性。因此,在 Nexar 的帮助下,我们发布了 BDD100K 数据集,这是迄今为止计算机视觉研究中***、最多样化的开放驾驶视频数据集。
从该数据集的名字 BDD100K 就可以猜到它有多大,这一数据集包含 10 万段视频。每段视频时长大约为 40 秒,格式为 720p、30 fps。视频中还包括手机记录的 GPS/IMU 信息,可以显示出大致的驾驶轨迹。这些视频是在美国不同地方收集的,如下图所示。
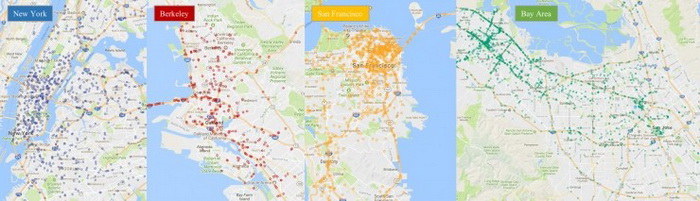
图:视频采集点
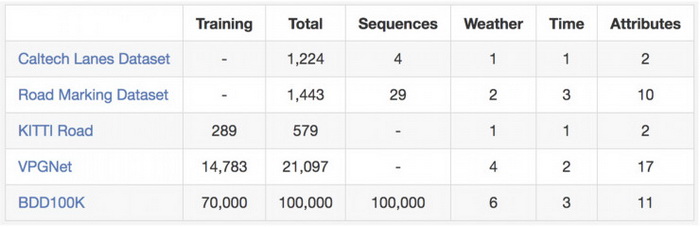
数据集中有很多不同天气,包括晴天、阴天和雨天,还有一天中的不同时间段,如白天和夜晚。下表总结了与之前数据集的比较,可以看到这一数据集更大、更多样。
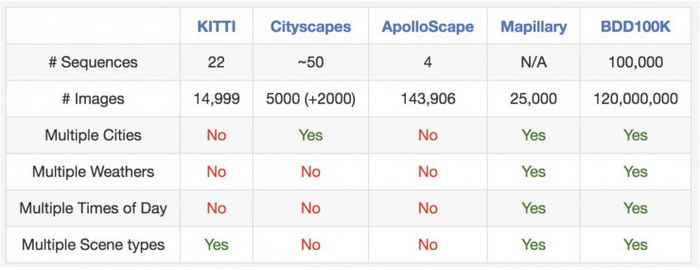
图:与其他道路场景数据集的对比
这些视频和视频中的轨迹对于驾驶策略的模仿学习很有用,正如我们 CVPR2017 的一篇的论文所示。为了助于在大数据集上进行计算机视觉研究,我们也在视频关键帧上提供基本注释,大家可以在 http://bdd-data.berkeley.edu下载数据和注释。
注释
我们在每段视频的第 10 秒进行关键帧采样,并为这些关键帧加上注释。主要有这些标记:图像标签、道路对象边界框、可驾驶区域、车道标记和全帧实例分割。这些注释将帮助我们理解不同类别场景中数据和对象统计信息的多样性。我们将在另一篇博文中讨论标注过程。
大家可以在这篇文章中看到更多关于注释的信息。

图:注释概览
道路目标检测
我们为这 10 万个关键帧中经常出现在道路上的对象标上边界框,以了解对象的分布及其位置。下面的条形图显示了对象数目。也有其他处理注释中统计信息的方法。例如,我们可以比较不同天气条件或不同场景下的对象数目。这张图还显示了数据集中的不同对象集以及数据集的规模——超过 100 万辆汽车。提醒下大家,这些是具有不同的外观和环境背景的物体。
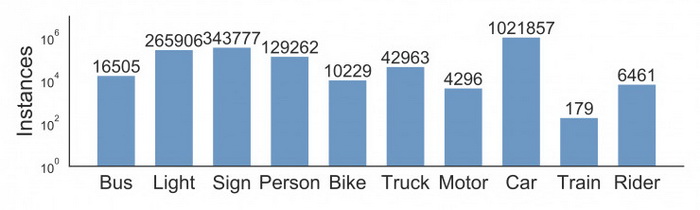
图:不同类型对象的统计信息
这一数据集也适用于某些特定领域的研究。例如,如果你对在街道上检测和避免行人感兴趣,那么你也可以研究这一数据集,因为它包含了比之前的专业数据集更多的行人实例,如下表所示。
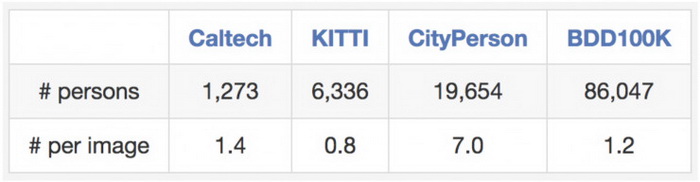
图:与其他行人数据集在训练集上的比较
车道标记
车道标记是对司机重要的道路指示。当 GPS 或地图没有准确全面覆盖时,它们也是自动驾驶系统把握驾驶方向和定位的关键线索。我们根据车道标记指示的不同将其划分为两种类型:垂直车道标记 (在下图中用红色表示) 表示沿着车道行驶方向的标记,平行车道标记 (在下图中用蓝色表示) 表示需要停车。我们还提供了一些属性,例如 solid vs. dashed、 double vs. single。

下面是与现有车道标记数据集的比较。
可驾驶区域
是否能在道路上行驶不仅取决于车道标记和交通设施,还依赖与道路上其他对象间的复杂交互。***,重要的是能知道哪些区域可以驾驶。为了研究这一问题,我们还提供了可驾驶区域的分割注释,如下图所示。我们基于车辆的轨迹将可驾驶区域分为两类:可驾驶和选择性驾驶。可驾驶用红色标记,意味着车辆享有道路优先权,可以在那个区域驾驶。选择性驾驶用蓝色标记,意味着汽车可以在该地区行驶,但必须谨慎,因为该车辆在这条道路上不具有道路优先权。

全帧分割
Cityscapes 数据集显示,全帧精细实例分割可以大大支持预测和目标检测研究。由于这次公开的视频在不同领域,我们提供了实例分割注释,也通过不同的数据集来比较相关的域转移。要实现像素级分割非常昂贵和费力,幸运的是,我们自己的标签工具可以将标签成本降低 50%。***,我们对这 10K 图像集的一个子集进行全帧分割。为了更易研究数据集之间的域转移,我们的标签集与 Cityscapes 中的训练注释可兼容。

自动驾驶挑战赛
基于这一数据集,我们在 CVPR 2018 自动驾驶研讨会上主办了三个挑战赛:道路目标检测、可驾驶区域预测和语义分割域适应。检测任务要求算法找出测试图像中所有的目标对象,可驾驶区域预测需要分割出汽车可以行驶的区域。在域适应挑战上,测试数据是在中国采集的,因此,这非常挑战,基于来自美国的数据训练的模型需要能用于北京拥挤的街道。大家可以登录如下网站提交结果:
http://bdd-data.berkeley.edu/login.html