在本文中,提出了一种用单眼强度图像进行面部深度图估计的对抗架构。 通过遵循图像到图像的方法,我们结合了监督学习和对抗训练的优势,提出了一个有条件的生成对抗网络,有效地学习将强度人脸图像转换为相应的深度图。 两个公共数据集,即Biwi数据库和Pandora数据集,被用来证明所提出的模型生成高质量的合成深度图像,无论是在视觉外观和信息内容方面。 此外,我们证明该模型能够通过深度模型测试生成的深度图来预测独特的面部细节,深度模型是在真实的深度图上进行面部验证任务的训练。

人工智能利用单眼强度图像进行面部深度图估计的对抗架构简介:深度估计是一项任务,在这个任务中,由于存在两个高质量的立体相机(即人眼)和一个特殊的学习工具(即人类大脑),人类会自然而然地获益。什么让人类在评估单个单眼图像的深度方面如此卓越以及这种学习过程如何发生?一个假设是,我们通过过去的视觉经验来开发教师来估计世界的三维结构,这包括与触觉刺激(对于小物体)和运动(对于更宽的空间)相关的大量观察结果)[43]。这个过程允许人类开发推测他们所看到的物体和场景的结构模型的能力,甚至可以从单眼图像中推断出来。
尽管深度估计是一种自然的人类大脑活动,但由于不同的三维地图可能会生成相同的二维图像,因此该任务在计算机视图环境中是一个不适合的问题。此外,由于属于强度图像和深度图的极其不同的信息来源,纹理和形状数据分别在这两个域之间进行翻译是非常困难的。传统上,计算机视觉界广泛地以不同的方式解决了深度估计问题,如立体相机[16,40],运动结构[4,6],以及来自阴影和光扩散的深度[35,37]。所提及的方法遭受不同的问题,如深度均匀性和缺失值(导致深度图像中的空洞)。其他具有挑战性的元素与摄像机校准,设置和后处理步骤相关,这些步骤可能会耗费大量时间和计算成本。最近,由于深度神经网络的进步,研究团队已经从强度图像中研究了单一深度估计任务,以克服以前报告的问题。
人工智能利用单眼强度图像进行面部深度图估计的对抗架构贡献:本文提出了一个从人脸单眼强度图像生成深度图的框架。采用对抗方法[12,28]来有效地训练完全卷积自动编码器,该编码器能够根据相应的灰度级图像估计面部深度图。为了训练和测试所提出的方法,利用由大量成对深度和强度图像组成的两个公共数据集,即Pandora [3]和Biwi Kinect Head Pose [9]数据集。就我们所知,这是通过与全球深度场景估计不同的对抗性方法来尝试解决这一任务的最初尝试之一,它涉及小尺寸物体和充满细节的人脸:人脸。***,我们研究如何有效地衡量系统的性能,引入各种按像素指标。此外,我们引入了一个人脸验证模型,对原始人脸深度图像进行训练,以检查生成的图像是否保持原始人物的面部特征,不仅在人类视觉检查时,而且在深度卷积网络处理时。
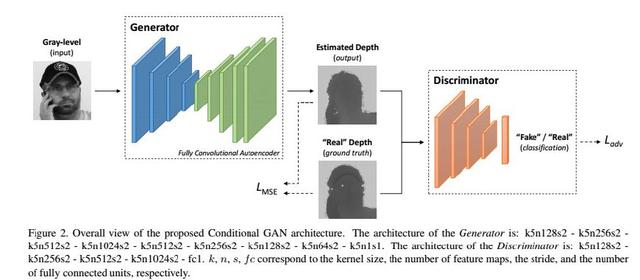
人工智能利用单眼强度图像进行面部深度图估计的对抗架构深度学习结构:在本节中,我们提出了用于人脸强度图像深度估计的模型,详细描述了cGAN体系结构,其训练过程和采用的预处理人脸裁剪算法(第3.2节)。 该模型的实施遵循[12]中提出的指导方针。在Goodfellow等人的工作之后。 [12]和米尔扎等人。 [28],所提出的体系结构由一个生成网络tt和一个判别网络d tt对应于一个估计函数,该函数预测给定人脸灰度图像强度的深度图Igen = tt(Igray) 图像作为输入并估计相应的深度图。(目标韩函数包含对抗损失和mse损失)。
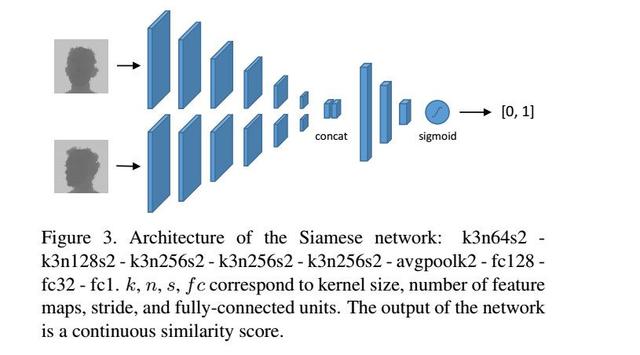
人工智能利用单眼强度图像进行面部深度图估计的对抗架构深度学习结论:在本文中,我们提出了一种从强度图像估计面部深度图的方法。 为了评估生成图像的质量,我们使用在原始深度图上预先训练好的Siamese网络执行人脸验证任务。 通过显示在生成的图像上进行测试时,连体网络的精度不会降低,我们证明了提供的框架可以生成高质量的深度图,无论是在视觉外观还是区分性信息方面。 我们还证明,提出的架构胜过自动编码器和文献竞争对手时,在训练对手政策。由于我们方法的灵活性,我们计划通过引入任务特定的损失来扩展我们的模型,并将其应用于不同的场景。