在存储设备中,使用分层技术,将冷热数据自动分层存放在具有不用读写性能的存储介质上,已经是很普遍的做法,比如 IBM 的 DS8K 中使用的 Easy Tier。这些功能都需要存储设备固件的支持,如何在 Linux 主机上,使用 Linux 现有的机制,实现数据的分层存储?本文主要介绍了 Linux 平台上两种不同的实现分层存储的方案。
背景介绍
随着固态存储技术 (SSD),SAS 技术的不断进步和普及,存储介质的种类更加多样,采用不同存储介质和接口的存储设备的性能出现了很大差异。SSD 相较于传统的机械硬盘,由于没有磁盘的机械转动,寻址速度大大提高,尤其在随机读写较多的应用环境下,性能会大大提升,但这些高性能存储设备的单位存储价格相对于传统的磁带和 SATA 硬盘也高出很多,如图 1 所示。
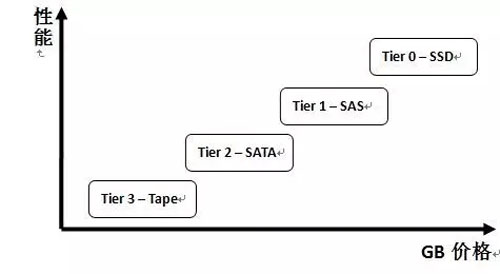
图 1 不同存储设备的性能价格对比
所以,如何高效平衡地利用这些存储设备,是所有存储厂商都在关注的问题。采用 Storage Tiering分层存储,将数据按照冷热进行自动分层,越热的数据存放在访问性能越高的设备上,而越冷的数据存放在访问性能越低的设备上,既可以获取高的性能,又可以有效节约成本。
Storage Tiering 分层存储技术在企业级的存储设备中已经被广泛使用,如 IBM 的 Easy Tier, EMC 的 FAST 等,但这些功能都集成在存储设备内部,需要存储设备固件的支持。
本文主要 Host 主机的角度,分析在 Linux 上实现 Storage Tiering 分层存储的两种方案以及其开源实现。为便于表述,本文中仅以两级 Tiering 为例,慢速设备为传统的 SATA 硬盘(DEV1),快速设备为固态存储硬盘 SSD(DEV2)。
分层存储的技术要点
要实现分层存储,首先需要将具有不同访问性能的存储设备(DEV1, DEV2)虚拟化成一个新的存储设备(VDEV)。与缓存(Cache)不同,VDEV 的存储容量是 DEV1 与 DEV2 的容量之和(需除去一些用于存放元数据的空间)。
所有用户的 IO 请求将会发给新的存储设备 VDEV,然后再按照一定的地址映射关系被转发到相应的物理设备 DEV1 或 DEV2。
同时还需要统计 IO 的热度,并根据这些热度数据,动态地在不同的 Tiering 间迁移数据,以达到性能容量的优化。
因此,实现分层存储主要包括三方面的工作,如图 2 所示。
存储设备的虚拟化
负责虚拟设备的创建,删除; 维护虚拟设备到物理设备的地址映射关系。
IO 性能的监测统计
统计 IO 的热度,以及 IO 的大小,随机性能属性,为数据迁移提供依据。
数据的迁移
根据 IO 数据的热度等统计属性,将访问频度高的数据迁移至读写性能高的 Tier 存放,而将访问频度低的数据迁移到性能低的 Tier 存放。
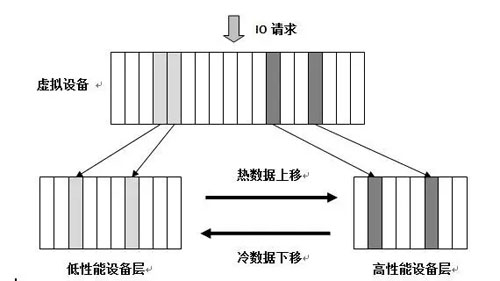
图 2 分层存储的数据迁移
基于 Block Device 的分层存储方案
该方案完整地实现了以上提到的分层存储中所有的工作,包括虚拟化,IO 性能统计以及数据的迁移。
方案结构
该方案的结构包括一个 Linux 设备驱动程序和若干用户态的控制程序,如图 3 所示。
驱动程序实现存储设备的虚拟化,IO 性能监测统计以及数据的迁移;
用户态控制程序负责创建、删除虚拟设备,手动触发数据迁移,以及设置获取设备状态。
该方案由于 Storage Tiering 所有的功能都在 Linux 内核实现,且需要维护虚拟设备到物理设备的地址映射表,以及保证数据一致性,所以实现难度和工作量比较大,但可扩展性和灵活性也相对较大。
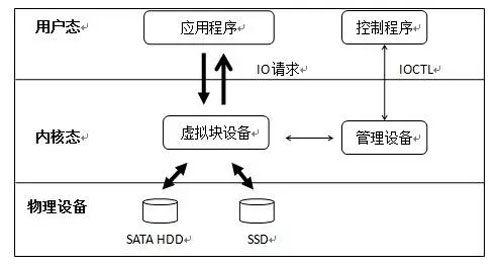
图 3 基于 Block Device 的分层存储方案
方案实现
该方案的实现主要包括以下内容:
1、管理设备的注册
管理设备主要用于与用户态程序的 IOCTL 交互,可以是一个字符设备或者 Misc 设备。Linux 下可以通过 register_chrdev 或 misc_register 注册,并实现所需要的 IOCTL 接口。
2、虚拟块设备的创建
用户态控制程序通过 IOCTL 向控制设备发起创建虚拟设备的请求,并传入所有的物理磁盘(DEV1,DEV2)的参数,如设备名,磁盘大小,虚拟磁盘的块大小等;驱动程序收到该请求后,进行必要的参数检查,然后调用 register_blkdev 创建一个新的块设备(VDEV)。并设置新设备的相关参数,如 IO 处理函数,队列大小,设备容量等。
3、虚拟设备地址与物理设备地址映射
虚拟设备地址到物理设备的地址映射表在虚拟设备创建是被初始化,并在数据迁移过程中被修改。
虚拟设备和物理设备都被分成固定大小的块,块大小可以固定或通过 IOCTL 由用户指定,但一旦确定,不能更改,一个 Block 是热度统计以及数据迁移的最小单位;每个 Block 包含若干个 sector(512 Byte)。
当 VDEV 收到一个 bio,可以由 bi_sector 和 bi_size 找出所对应的 VDEV 的 Block 以及 Block 内的偏移量,通过查询映射表,找到各个 VDEV Block 所对应的物理设备以及 Block,然后读取物理设备 Block 内的偏移量,如图 4 所示。
地址映射表以及其他的元数据需要存储在物理设备上,以便机器重启时能重构这个虚拟的块设备,且需要采取一定的备份策略,防止断电或磁盘损坏造成数据丢失。
4、IO 热度统计
IO 热度统计也以 Block 为基本单位,每个 Block 内的任何一个 sector 被访问,该 Block 的热度都为增加。由于大 IO 以及顺序 IO 在性能在传统硬盘和 SSD 上的差异并不是特别大,所以在进行热度统计是应该考虑排除大 IO 和顺序 IO。
5、数据迁移
可以采用自动方式或手动方式。自动方式由驱动内的定时器驱动,每隔一定的时间,启动数据迁移的扫描,将 IO 热度统计中的热数据向高性能存储设备迁移,冷数据向低性能存储设备迁移;手动方式由用户指定,将某块数据向高性能存储设备迁移或低性能设备迁移。手动数据迁移方式增加了更大的灵活性和可扩展性。
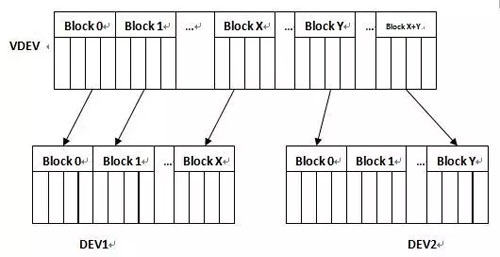
图 4 虚拟设备与物理设备的地址映射
开源实现
BTier 基于 Block Device 的分层存储方案的开源实现。BTier 最大支持 16 个设备的虚拟化,这些设备被 BTier 简单地捆绑成一个 btier 块设备,因此,其中任何一个设备的失效,都会导致整个 btier 的失效。
编译并以模块形式安装 BTier 之后,会创建一个名为 tiercontrol 的字符设备;
然后使用 BTier 提供的 btier_setup 应用可以创建一个新的块设备 btiera,然后就可以对 btiera 设备进行所有块设备的读写操作,包括分区和创建文件系统。
BTier 还提供了丰富的 sysfs 接口,进行控制和信息获取,如数据迁移的开关,间隔时间,IO 统计信息等。
不过 BTier 每个 Tier 层仅支持 1 个物理设备,同层多个设备的虚拟化需要借助其他的方法,在虚拟化上面,BTier 还有可以改善的空间。
基于 LVM 的分层存储方案
Linux 的逻辑卷管理(LVM)提供了存储虚拟化,可以将多个物理卷(PV)建成一个卷组(VG),然后再在 VG 里创建虚拟卷(VG)。而且 LVM 提供了在不同物理卷之间迁移数据的 API。因此,基于 LVM 的分层存储方案借助 LVM 的虚拟化和数据迁移的能力,实现会更简单。
方案结构
该方案中,数据一致性的问题以及数据迁移时 IO 中断的问题都由 LVM 进行处理,重点在于如何分析并统计 IO 的热度信息,并且不涉及内核态的开发。该方案的结构如图 5 所示。
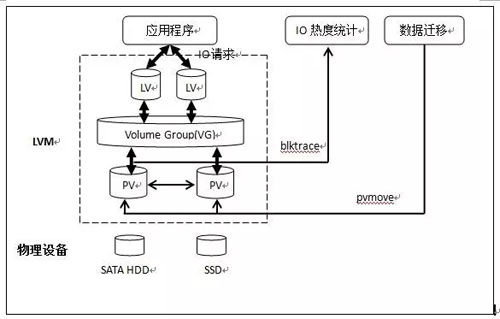
图 5 基于 LVM 的分层存储方案
方案实现
该方案的实现主要包括以下内容:
1、创建虚拟设备
使用 pvcreate 将所有的物理磁盘创建成物理卷(PV);再使用 vgcreate 将所有的 VG 创建成一个卷组(VG);最后使用 lvcreate 在创建出来的 VG 上建虚拟卷。
2、IO 热度统计
IO 热度统计可以使用 blktrace 工具,或者实现一个设备驱动来检测 IO 的热度。使用 blkparse 可以解析 blktrace 的输出,然后分析这些 IO 的分布以及读写频度,从而得到 IO 的热度统计信息。
3、数据迁移
根据 IO 的热度统计信息,使用 LVM 提供的 pvmove 工具,可以在属于同一个 VG 里的不同 PV 之间进行数据迁移,将热数据和冷数据分布存放在不同的物理卷上。
开源实现
LVMTS(LVM Tired Storage)是一个使用 SSD 和 HDD 来创建混合存储的方案,完全在用户态实现,主要由几个守护进程构成。
Lvmtscd 负责监测 blktrace 的输出并统计块设备的访问频度,并将这些统计信息记录在文件中;
Lvmtsd 负责根据用户配置的信息,启动其他的守护进程,并完成数据迁移。
实际使用中发现,LVMTS 并不是太稳定,而且在 IO 分析统计上并不是太完善,可开发的空间仍然很大。
总结
在 Linux 上实现 Storage Tiering 分层存储,方法有很多,包括使用 Linux Device Mapper 机制等。本文对比较常用的两种方案的实现进行了大概的分析,以及各个方案的优劣,在实际实现中,还有很多细节需要考虑,如 Thin Provision,SSD Trim 等的支持。