













作者简介:Filip Piekniewski 是计算机视觉和 AI 领域的专家,还是 Koh Young Technology 公司的*** AI 科学家。
处于所谓的 AI 革命的前沿至今已有好几年;许多人过去认为,深度学习是神奇的“银弹”,会把我们带到技术奇点(general AI)的奇妙世界。许多公司在 2014 年、2015 年和 2016 年纷纷下豪赌,那几年业界在开拓新的边界,比如 Alpha Go 等。特斯拉等公司通过各自的门面(CEO)来宣布,完全自动驾驶的汽车指日可待,以至于特斯拉开始向客户兜售这种愿景(有依赖于未来的软件更新)。
我们现在进入到 2018 年年中,情况已发生了变化。这表面上暂时还看不出来,NIPS 大会仍一票难求,许多公司的公关人员仍在新闻发布会上竭力鼓吹 AI,埃隆·马斯克仍不断承诺会推出自动驾驶汽车,谷歌的***执行官仍不断高喊吴恩达的口号(AI 比电力更具革命性)。但这种论调开始站不住脚。正如我在之前的文章中预测,最站不住脚的地方就是自动驾驶――即这项技术在现实世界中的实际应用。
深度学习方面尘埃已落定
ImageNet 得到有效地解决(注意:这并不意味着视觉已得到解决)时,这个领域的杰出研究人员、甚至包括通常低调的杰夫·辛顿(Geoff Hinton)都在积极接受媒体采访,在社交媒体上大造声势,比如雅恩·乐坤(Yann Lecun)、吴恩达和李飞飞等人。大意无非是,我们正面临一场巨大的革命;从现在开始,革命的步伐只会加快。多年过去了,这些人的推文变得不那么活跃了,下面以吴恩达的推文为例来说明:
2013 年:每天 0.413 条推文
2014 年:每天 0.605 条推文
2015 年:每天 0.320 条推文
2016 年:每天 0.802 条推文
2017 年:每天 0.668 条推文
2018 年:每天 0.263 条推文(截至 5 月 24 日)
也许这是由于吴恩达的大胆言论现在受到了 IT 界会更严厉的拷问,正如下面这条推文所示:
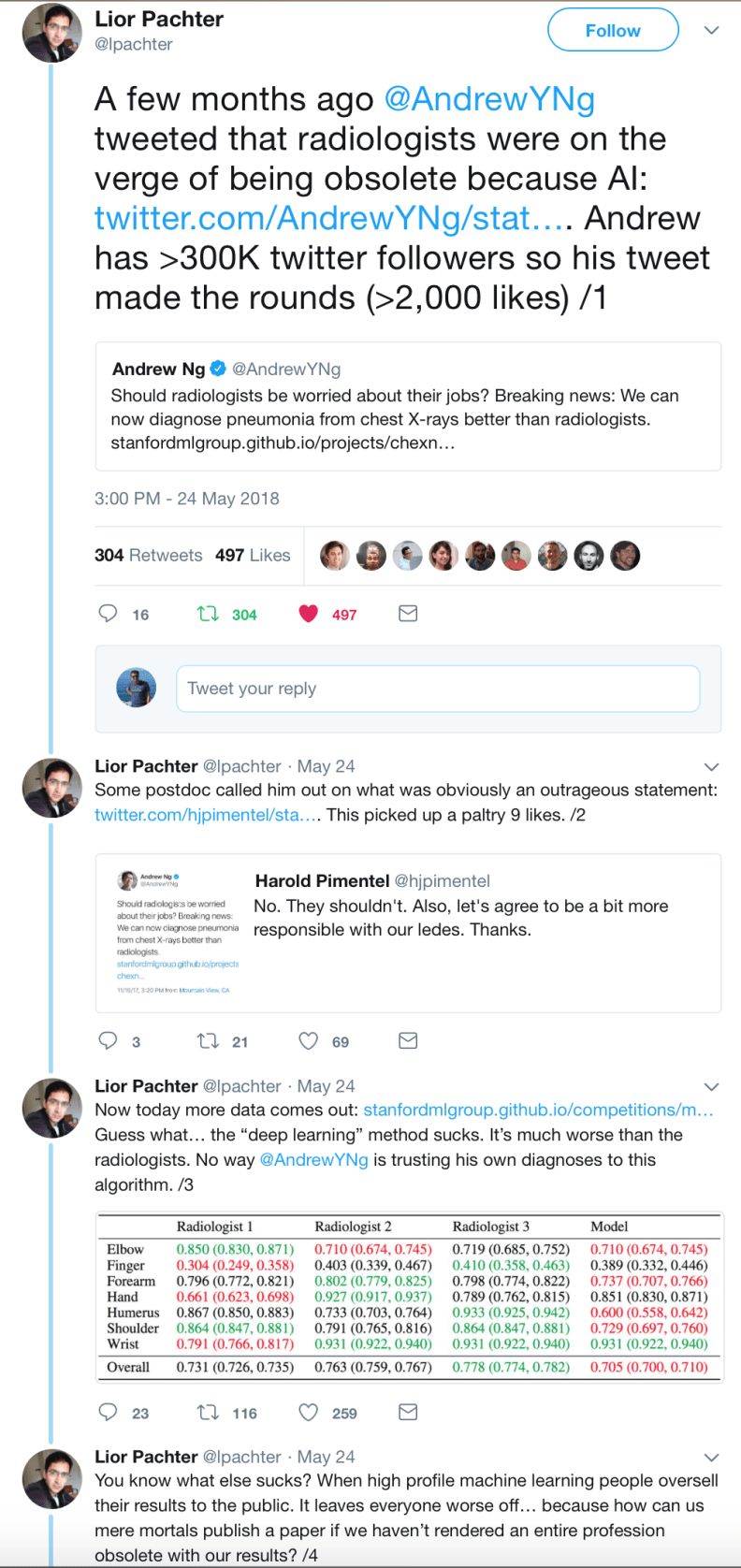
显而易见,AI 方面的声势已大幅减弱,现在盛赞深度学习是***算法的推文少多了,论文也少了“革命性”的论调,多了“演进性”的论调。自推出 Alpha Go zero 以来,Deepmind 还没有拿出任何激动人心的成果。OpenAI 相当安静,它上一次在媒体上大放异彩是玩《刀塔2》(Dota2)游戏的代理,我想它原本是为了营造与 Alpha Go 一样大的声势,但很快就没有了动静。实际上这时开始出现了好多文章,认为连谷歌实际上都不知道如何处理 Deepmind,因为它们的结果显然不如最初预期的那样注重实际……至于那些声名显赫的研究人员,他们通常在四处会见加拿大或法国的政府官员,确保将来拿到拨款,雅恩·乐坤甚至辞去了 Facebook AI 实验室主任一职,改任 Facebook *** AI 科学家。从财大气粗的大公司逐渐转向政府资助的研究机构,这让我意识到,这些公司(我指谷歌和 Facebook)对此类研究的兴趣实际上在慢慢减弱。这些同样是早期的征兆,不是大声说出来,只是肢体语言。
深度学习不具有扩展性
深度学习方面老生常谈的重要口号之一是,它几乎毫不费力就能扩展。我们在 2012 年有了约有 6000 万个参数的 AlexNet,现在我们可能拥有至少是参数是这个数 1000 倍的模型,是不是?也许我们有这样的模型,可是问题是,这种模型的功能强 1000 倍吗?或者甚至强 100 倍?OpenAI 的一项研究派上了用场:
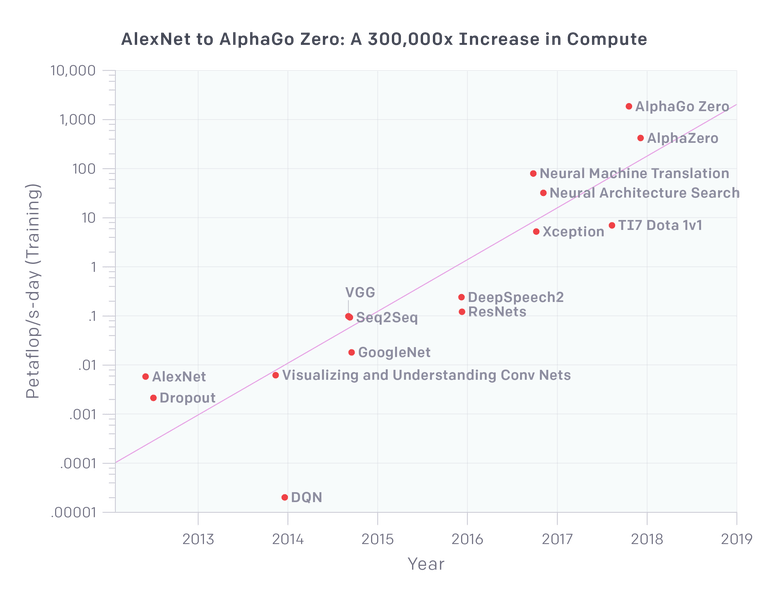
所以,从视觉应用这方面来看,我们看到 VGG 和 Resnets 在运用的计算资源大约高出一个数量级后趋于饱和(从参数的数量来看实际上更少)。Xception 是谷歌 Inception 架构的一种变体,实际上只是在 ImageNet 方面比 Inception 略胜一筹,可能比其他各种架构略胜一筹,因为实际上 AlexNet 解决了 ImageNet。所以在计算资源比 AlexNet 多 100 倍的情况下,我们实际上在视觉(准确地说是图像分类)方面几乎让架构趋于饱和。神经机器翻译是各大互联网搜索引擎大力开展的一个方向,难怪它获取所能获取的所有计算资源(不过谷歌翻译仍很差劲,不过有所改进)。上面图中最近的三个点显示了与强化学习有关的项目,适用于 Deepmind 和 OpenAI 玩的游戏。尤其是 Alpha Go Zero 和更通用一点的 Alpha Go 获取的计算资源非常多,但它们并不适用于实际应用,原因是模拟和生成这些数据密集型模型所需的数据需要这些计算资源中的大部分。OK,现在我们可以在几分钟内、而不是几天内训练 AlexNet,但是我们可以在几天内训练大 1000 倍的 AlexNet,并获得性质上更好的结果吗?显然不能……。
所以实际上,旨在显示深度学习扩展性多好的这张图恰恰表明了其扩展性多差。我们不能简单地通过扩展 AlexNet 来获得相应更好的结果,我们不得不调整特定的架构,如果不能在数据样本的数量上获得数量级的提升,实际额外的计算资源无法换来太大的效果,而这种量级的数据样本实际上只有在模拟游戏环境中才有。
自动驾驶事故不断
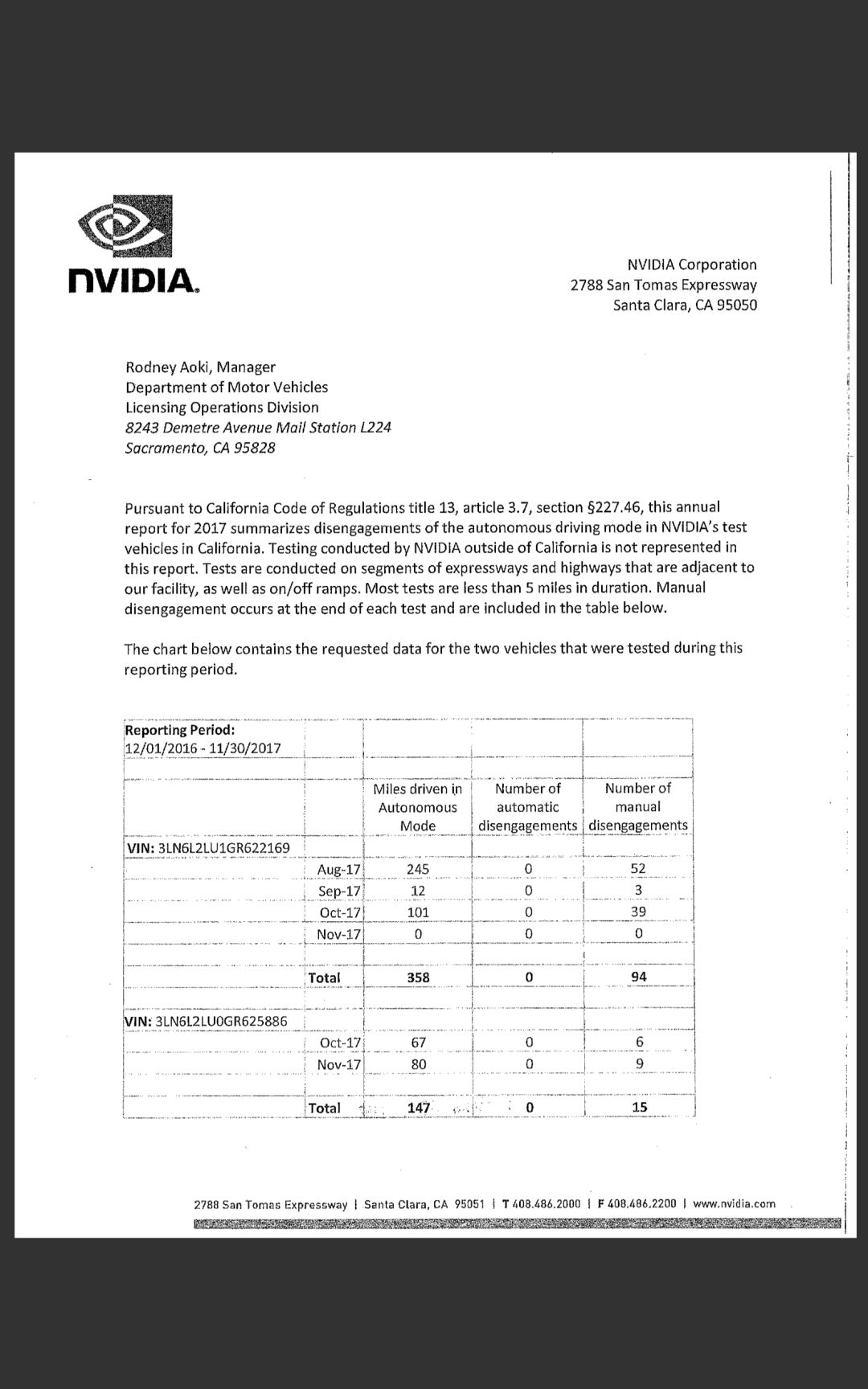
对深度学习名声打击***的无疑是自动驾驶车辆这个领域(我很早以前就预料到这一点,比如 2016 年的这篇文章:https://blog.piekniewski.info/2016/11/15/ai-and-the-ludic-fallacy/)。起初,人们认为端到端深度学习有望以某种方式解决这个问题,这是英伟达大力倡导的一个观点。我认为世界上没有哪个人仍相信这一点,不过也许我是错的。看看去年加利福尼亚州车辆管理局(DMV)的脱离(disengagement)报告,英伟达汽车实际上开不了 10 英里就脱离一次。

我在另一篇文章(https://blog.piekniewski.info/2018/02/09/a-v-safety-2018-update/)中讨论了这方面的总体情况,并与人类驾驶员的安全性进行了比较(爆料一下情况不太好)。自 2016 年以来,特斯拉自动驾驶系统已发生了几起事故,几起还是致命的。特斯拉的自动驾驶系统不该与自动驾驶混为一谈,但至少它在核心层面依赖同一种技术。到今天为止,除了偶尔的严重错误外,它还是无法在十字路口停车,无法识别红绿灯,甚至无法绕环岛正确行驶。现在是 2018 年 5 月,离特斯拉承诺来一次西海岸到东海岸的自动驾驶(这一幕没有出现,不过传闻称特斯拉有过尝试,但无法成行)已有好几个月。几个月前(2018 年 2 月),被问及西海岸到东海岸的自动驾驶时,埃隆·马斯克在电话会议上重申了这点:
“我们本可以进行西海岸到东海岸的驾驶,但那需要太多专门的代码来进行有效地改动,但这适用于一条特定的路线,但不是通用的解决方案。于是我认为我们可以重复它,但如果它根本无法适用于其他路线上,那不是真正意义上的解决方案。”
“我为我们在神经网络方面取得的进展而感到激动。它是很小的进展,似乎不是多大的进展,但突然让人大为惊叹。”
嗯,看一看上图(来自 OpenAI),我似乎没有看到那个长足的进步。对于这个领域的几乎各大玩家来说,出现脱离之前的英里数也没有显著增加。实际上,上述声明可以理解为:“我们目前没有能够安全地将人们从西海岸载到东海岸的技术,不过如果我们真愿意的话,其实可以做手脚……我们热切地希望,神经网络功能方面很快会出现某种突飞猛进,好让我们从耻辱和大堆诉讼中脱身出来。”
但是给 AI 泡沫最猛力一戳的是优步(Uber)自动驾驶汽车在亚利桑那州撞死行人的事故。从美国国家运输安全委员会(NTSB)的初步报告来看,我们可以看到一些令人震惊的声明:

除了这份报告中明显提到的总体系统设计失败外,令人吃惊的是,系统花了好几秒的时间来确定看到的前方到底是什么(无论是行人、自行车、汽车还是其他什么),而不是这种情形下做出唯一的合理决定,从而旨在确保没有撞上。这有几个原因:***,人们常常会事后会用言语表达其决定。因此,一个人通常会说:“我看到了一个骑车的人,于是我转向左边以避开他。”大量的精神生理学文献会给出一番截然不同的解释:一个人看到了被其神经系统的快速感知回路迅速理解成障碍物的东西后,迅速采取行动来避开它,过了好多秒后才 意识到所发生的事情,并提供口头解释。”我们每天做不是用言语表达的众多决定,而驾驶包括许多这样的决定。用言语表达开销很大,又耗费时间,实际情形常常很紧迫,不允许这么做。这种机制已进化了 10 亿年来确保我们的安全,而驾驶环境(尽管现代)利用了许多这样的反射。由于这些反射没有专门针对驾驶而进化,可能会导致错误。一只黄蜂在汽车里嗡嗡作响,引起驾驶员条件反射,可能会导致多起车祸和死亡。但是我们对于三维空间和速度的基本理解、预测代理的行为和路上迎面而来的实际物体的行为这种能力却是很原始的技能,跟 1 亿年前一样,这些技能在今天一样有用,它们因进化而得到了显著的增强。
但是由于这些东西大多不容易用言语表达,它们很难来测量,因而我们根本无法针对这些方面来优化机器学习系统……现在这将认同英伟达的端到端方法――学习图像->动作映射,跳过任何言语表达,在某些方面这是正确的做法,但问题是,输入空间是高维的,而动作空间却是低维的。因此,与输入的信息量相比,“标签”(读出)的“数量”极小。在这种情况下,极容易学习虚假关系(spurious relation),深度学习中的对抗样本(adversarial example)就表明了这点。我们需要一种不同的范式,我假设预测整个感知输入以及动作是让系统能够提取现实世界语义的***步,而不是提取虚假关系是***步。欲知详情,请参阅我的***个提议的架构:预测视觉模型(Predictive Vision Model,https://blog.piekniewski.info/2016/11/04/predictive-vision-in-a-nutshell/)。
实际上,如果说我们从深度学习的大流行中学到什么东西,那就是(10k+ 维度)图像空间里面有足够多的虚假模式,它们实际上在许多图像上具有共性,并留下印象,比如我们的分类器实际上理解它们看到的东西。连在这个领域浸淫多年的***研究人员都承认,事实远非如此。
加里·马库斯对炒作说不
我应该提到一点,更多的知名人士认识到了这种傲慢自大,有勇气公开炮轰。这个领域最活跃的人士之一是加里·马库斯(Gary Marcus)。虽然我并不同意加里在 AI 方面提出的每个观点,但我们无疑一致认为:AI 还没有像深度学习炒作宣传机器描绘的那么强大。实际上,相距甚远。他写过出色的博文/论文:
《深度学习:批判性评估》(https://arxiv.org/abs/1801.00631)

《为深度学习的质疑声辩护》(https://medium.com/@GaryMarcus/in-defense-of-skepticism-about-deep-learning-6e8bfd5ae0f1)
他非常深入细致地解析了深度学习炒作。我很敬重加里,他的表现像是真正的科学家,大多数被称为“深度学习明星”的人其表现就像三流明星。
结束语
预测 AI 的冬天就像预测股市崩盘――不可能准确地预测何时发生,但几乎可以肯定的是,它会在某个时候点发生。就像股市崩盘之前,有迹象预示股市即将崩盘,但是对前景的描绘是如此的诱人,以至于很容易忽视这些迹象,哪怕这些迹象清晰可见。在我看来,已经有这类明显的迹象表明,深度学习将大幅降温(可能在 AI 行业,这个术语已被企业宣传机器没完没了地滥用),这类迹象已经清晰可见,不过大多数人被越来越诱人的描绘蒙蔽了双眼。那个冬天会有多“深”?我不知道。接下来会发生什么?我也不知道。但我很肯定 AI 冬天会到来,也许更早到来,而不是更晚到来。















