一、前言
Spark 作为大数据计算引擎,凭借其快速、稳定、简易等特点,快速的占领了大数据计算的领域。本文主要为作者在搭建使用计算平台的过程中,对于 Spark 的理解,希望能给读者一些学习的思路。文章内容为介绍 Spark 在 DataMagic 平台扮演的角色、如何快速掌握 Spark 以及 DataMagic 平台是如何使用好 Spark 的。
二、Spark 在 DataMagic 平台中的角色
整套架构的主要功能为日志接入、查询 (实时和离线)、计算。离线计算平台主要负责计算这一部分,系统的存储用的是 COS(公司内部存储),而非 HDFS。
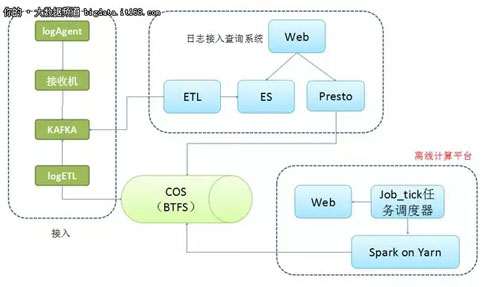
图 2-1
下面将主要介绍 Spark on Yarn 这一架构,抽取出来即图 2-2 所示,可以看到 Spark on yarn 的运行流程。
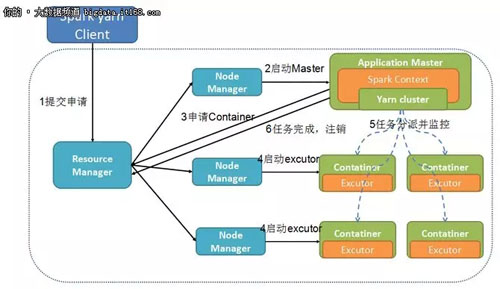
图 2-2
三、如何快速掌握 Spark
对于理解 Spark,我觉得掌握下面 4 个步骤就可以了。
1. 理解 Spark 术语
对于入门,学习 Spark 可以通过其架构图,快速了解其关键术语,掌握了关键术语,对 Spark 基本上就有认识了,分别是结构术语 Shuffle、Patitions、MapReduce、Driver、Application Master、Container、Resource Manager、Node Manager 等。API 编程术语关键 RDD、DataFrame,结构术语用于了解其运行原理,API 术语用于使用过程中编写代码,掌握了这些术语以及背后的知识,你就也知道 Spark 的运行原理和如何编程了。
2. 掌握关键配置
Spark 在运行的时候,很多运行信息是通过配置文件读取的,一般在 spark-defaults.conf,要把 Spark 使用好,需要掌握一些关键配置,例如跟运行内存相关的,spark.yarn.executor.memoryOverhead、spark.executor.memory,跟超时相关的 spark.network.timeout 等等,Spark 很多信息都可以通过配置进行更改,因此对于配置需要有一定的掌握。但是使用配置时,也要根据不同的场景,这个举个例子,例如 spark.speculation 配置,这个配置主要目的是推测执行,当 worker1 执行慢的情况下,Spark 会启动一个 worker2,跟 worker1 执行相同的任务,谁先执行完就用谁的结果,从而加快计算速度,这个特性在一般计算任务来说是非常好的,但是如果是执行一个出库到 Mysql 的任务时,同时有两个一样的 worker,则会导致 Mysql 的数据重复。因此我们在使用配置时,一定要理解清楚,直接 google spark conf 就会列出很多配置了。
3. 使用好 Spark 的并行
我们之所以使用 Spark 进行计算,原因就是因为它计算快,但是它快的原因很大在于它的并行度,掌握 Spark 是如何提供并行服务的,从而是我们更好的提高并行度。
对于提高并行度,对于 RDD,需要从几个方面入手,1、配置 num-executor。2、配置 executor-cores。3、配置 spark.default.parallelism。三者之间的关系一般为 spark.default.parallelism=num-executors*executor-cores 的 2~3 倍较为合适。对于 Spark-sql,则设置 spark.sql.shuffle.partitions、num-executor 和 executor-cores。
4. 学会如何修改 Spark 代码
新手而言,特别是需要对 Spark 进行优化或者修改时,感到很迷茫,其实我们可以首先聚焦于局部,而 Spark 确实也是模块化的,不需要觉得 Spark 复杂并且难以理解,我将从修改 Spark 代码的某一角度来进行分析。
首先,Spark 的目录结构如图 3-1 所示,可以通过文件夹,快速知道 sql、graphx 等代码所在位置,而 Spark 的运行环境主要由 jar 包支撑,如图 3-2 所示,这里截取部分 jar 包,实际上远比这多,所有的 jar 包都可以通过 Spark 的源代码进行编译,当需要修改某个功能时,仅需要找到相应 jar 包的代码,修改之后,编译该 jar 包,然后进行替换就行了。

图 3-1
图 3-2
而对于编译源代码这块,其实也非常简单,安装好 maven、scala 等相关依赖,下载源代码进行编译即可,掌握修改源码技巧对于使用好开源项目十分重要。
四、DataMagic 平台中的 Spark
Spark 在 DataMagic 中使用,也是在边使用边探索的过程,在这过程中,列举了其比较重要的特点。
1. 快速部署
在计算中,计算任务的数量以及数据的量级每天都会发生变化,因此对于 Spark 平台,需要有快速部署的特性,在实体机上,有一键部署脚本,只要运行一个脚本,则可以马上上线一个拥有 128G 内存、48cores 的实体机,但是实体机通常需要申请报备才能获得,因此还会有 docker 来支持计算资源。
2. 巧用配置优化计算
Spark 大多数属性都是通过配置来实现的,因此可以通过配置动态修改 Spark 的运行行为,这里举个例子,例如通过配置自动调整 exector 的数量。
2.1 在 nodeManager 的 yarn-site.xml 添加配置
yarn.nodemanager.aux-services
mapreduce_shuffle,spark_shuffle
yarn.nodemanager.aux-services.spark_shuffle.class
org.apache.spark.network.yarn.YarnShuffleService
2.2 将 spark-2.2.0-yarn-shuffle.jar 文件拷贝到 hadoop-yarn/lib 目录下 (即 yarn 的库目录)
2.3 在 Spark 的 spark-default.xml 添加配置
spark.dynamicAllocation.minExecutors 1 #最小 Executor 数
spark.dynamicAllocation.maxExecutors 100 #*** Executor 数
通过这种配置,可以达到自动调整 exector 的目的。
3. 合理分配资源
作为一个平台,其计算任务肯定不是固定的,有的数据量多,有的数据量少,因此需要合理分配资源,例如有些千万、亿级别的数据,分配 20 核计算资源就足够了。但是有些数据量级达到百亿的,就需要分配更多的计算资源了。参考第三章节的第 3 点。
4. 贴合业务需求
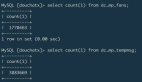
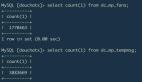
计算的目的其实就是为了服务业务,业务的需求也理应是平台的追求,当业务产生合理需求时,平台方也应该尽量去满足。如为了支持业务高并发、高实时性查询的需求下,Spark 在数据出库方式上,支持了 Cmongo 的出库方式。
sc = SparkContext(conf=conf) sqlContext = SQLContext(sc) database = d = dict((l.split('=') for l in dbparameter.split())) parquetFile = sqlContext.read.parquet(file_name) parquetFile.registerTempTable(tempTable) result = sqlContext.sql(sparksql) url = "mongodb://"+database['user']+":"+database['password']+"@"+database['host']+":"+database['port'] result.write.format("com.mongodb.spark.sql").mode('overwrite').options(uri=url,database=database['dbname'],collection=pg_table_name).save()
5. 适用场景
Spark 作为通用的计算平台,在普通的应用的场景下,一般而言是不需要额外修改的,但是 DataMagic 平台上,我们需要 “在前行中改变”。这里举个简单的场景,在日志分析中,日志的量级达到千亿 / 日的级别,当底层日志的某些字段出现 utf-8 编码都解析不了的时候,在 Spark 任务中进行计算会发生异常,然后失败,然而如果在数据落地之前对乱码数据进行过滤,则有可能会影响数据采集的效率,因此最终决定在 Spark 计算过程中解决中这个问题,因此在 Spark 计算时,对数据进行转换的代码处加上异常判断来解决该问题。
6.Job 问题定位
Spark 在计算任务失败时候,需要去定位失败原因,当 Job 失败是,可以通过 yarn logs -applicationId application 来合并任务 log,打开 log,定位到 Traceback,一般可以找到失败原因。一般而言,失败可以分成几类。
a. 代码问题,写的 Sql 有语法问题,或者 Spark 代码有问题。
b. Spark 问题,旧 Spark 版本处理 NULL 值等。
c. 任务长时间 Running 状态,则可能是数据倾斜问题。
d. 任务内存越界问题。
7. 集群管理
Spark 集群在日常使用中,也是需要运营维护的,从而运营维护,发现其存在的问题,不断的对集群进行优化,这里从以下几个方面进行介绍,通过运营手段来保障集群的健壮性和稳定性,保证任务顺利执行。
a. 定时查看是否有 lost node 和 unhealthy node,可以通过脚本来定时设置告警,若存在,则需要进行定位处理。
b. 定时扫描 hdfs 的运行 log 是否满了,需要定时删除过期 log。
c. 定时扫描集群资源是否满足计算任务使用,能够提前部署资源。
五、总结
本文主要是通过作者在搭建使用计算平台的过程中,写出对于 Spark 的理解,并且介绍了 Spark 在当前的 DataMagic 是如何使用的,当前平台已经用于架平离线分析,每天计算分析的数据量已经达到千亿~ 万亿级别。