本文是一篇科普性质的文章,希望能通过一个通俗易懂的例子给大家讲清楚大数据分布式计算技术。
大数据技术虽然包含存储、计算和分析等一系列庞杂的技术,但分布式计算一直是其核心,想要了解大数据技术,不妨从 MapReduce 分布式计算模型开始。
该理论模型并不是什么新理念,早在 2004 年就被 Google 发布,经过十多年的发展,俨然已经成为了当前大数据生态的基石,可谓大数据技术之道,在于 MapReduce。
传统计算技术
在进入到分布式计算技术这个概念之前,我们先回顾一下传统计算技术。
为了使计算机领域的相关概念能够生动形象深入浅出,我将计算机类比为人:
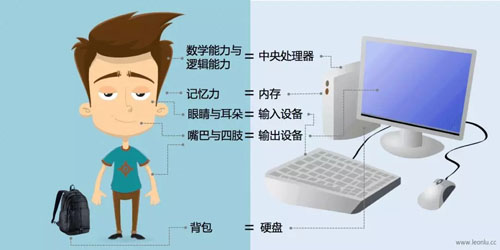
在这张图中我们建立了计算机基本元件的类比关系,并不严谨但足以说明问题。
有了这个类比关系,我们可以把计算机领域的问题转换为我们熟悉的人类领域的问题。
从现在开始,每个人,比如你自己就是一台计算机,我们代称为“人型计算机”,你拥有基本的计算机元件,上帝是个程序员,可以编写程序——一系列设定好的指令,让你完成一些计算任务。
下面我们要用一个简单的案例,分析“人型计算机”是如何利用传统计算技术解决实际问题的。
在开始之前,要增加一些限定,如同正常计算机的内存是有上限的,我们的“人型计算机”也存在记忆力的上限。
这里我们假设一个“人型计算机”最多可以同时在“内存”中记住 4 种信息,例如:苹果、梨等四种水果的个数:
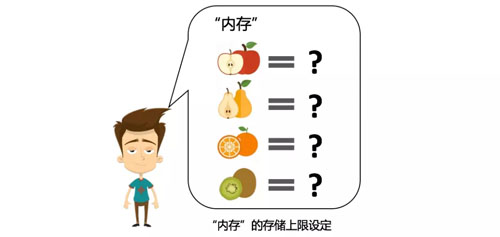
看起来这台“人型计算机”的性能比较差,不过好在我们需要处理的问题也不复杂。
有几十张不包含大王和小王的扑克牌,这些牌的花色和大小均不确定(并不一定能凑成一副牌),如何给一台“人型计算机”设计一个程序,统计各个花色的扑克牌数量?

你的答案可能脱口而出:对于“人型计算机”而言,直接在大脑中记住每个花色的个数,一张一张地取扑克牌计数,处理完所有的扑克牌之后报 4 个花色的个数就行。
答案完全正确,正常计算机最简单的计算模式就是这样的,内存中记录统计结果,随着输入设备不断读取数据,更新内存中的统计结果,***从输出设备展示结果:
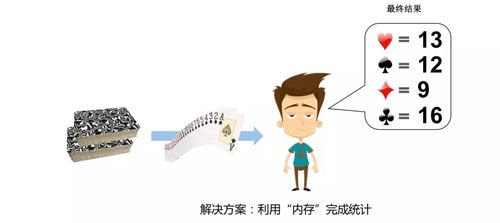
接下来问题的难度要升级了,统计这些扑克牌中 A~K 共 13 种牌面每种牌面的个数。我们的“程序”该如何升级?

我们察觉到,如果仍然沿用之前的解决思路,“人型计算机”的“内存”已经不够用了,因为其存储上限为 4 种信息,无法存储 A~K 这 13 种牌面信息。
联系一下现实生活中的场景,当我们发现自己无法记住很多信息时,会用账本来辅助记忆。
对于计算机来说是一样的,内存不足就使用磁盘来存放信息,这时候,账本就可以类比于一个存放于“磁盘”的 Excel 文档:
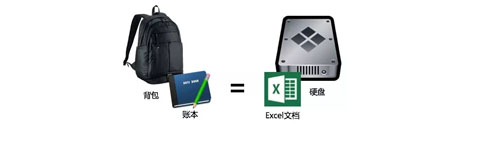
那么统计牌面这个问题的解决思路就有了:每取一张扑克牌,在账本中更新相应牌型的统计个数,数完所有的扑克牌之后直接报出结果。

单个计算机的传统计算模式就是这样,可以简单概括为按照一定统一规则对输入数据进行加减乘除等数学运算,然后输出结果的过程,这中间产生的数据会存储在内存或硬盘中。
在上面的案例中,扑克牌是“人型计算机”的“输入数据“,相当于计算机二进制世界中可以被识别的数字和文本。统计的扑克牌个数是“输出结果“,相当于你可以在电脑屏幕上看到的信息。
实际上,凭借内存、硬盘和 CPU 等基本组件,单个计算机(不只包括个人电脑,智能手机也算)已经可以完成我们上网听歌看电影等日常基本需求中所涉及到的计算。
只要计算不超出 CPU 的极限(譬如围棋人机对战之类的)是妥妥没问题的,而且我们还有优化内存、优化硬盘等多种手段来增强单个计算机的计算能力,从而满足人民群众日益增长的物质与文化生活的需要。
好了,背景知识已经足够了,让我们进入正题。
大数据分布式计算
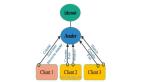
首先,什么是分布式计算?简单点理解就是将大量的数据分割成多个小块,由多台计算机分工计算,然后将结果汇总。
这些执行分布式计算的计算机叫做集群,我们仍然延续前文中人和计算机的类比,那么集群就是一个团队,单兵作战的时代已经过去,团队合作才是王道:

为什么需要分布式计算?因为“大数据”来了,单个计算机不够用了,即数据量远远超出单个计算机的处理能力范围。
有时候是单位时间内的数据量大,比如在 12306 网上买票,每秒可能有数以万计的访问;也有可能是数据总量大,比如百度搜索引擎,要在服务器上检索数亿的中文网页信息。
实现分布式计算的方案有很多,在大数据技术出现之前就已经有科研人员在研究,但一直没有被广泛应用。
直到 2004 年 Google 公布了 MapReduce 之后才大热了起来。大数据技术、分布式计算和 MapReduce 的关系可以用下图来描述,MapReduce 是分布式计算在大数据领域的应用:
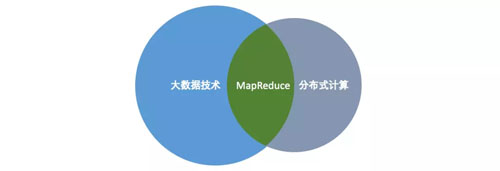
MapReduce 模型是经过商业实践的成熟的分布式计算框架,与 Google 的分布式文件系统 GFS、分布式数据存储系统 BigTable 一起,号称 Google 的大数据“三宝”,为大数据技术的发展提供了坚实的理论基础。
但遗憾的是,谷歌并没有向外界公布自己的商业产品,而真正让大数据技术大踏步前进的是按照 Google 理论实现的开源免费产品 Hadoop,目前已经形成了以 Hadoop 为核心的大数据技术生态圈。

让我们回到数扑克牌这个例子中,大数据时代的扑克牌问题是什么样子的?
- 输入数据的规模增加:扑克牌暴增到数万张。
- 中间运算数据的规模增加:问题又升级了,我们需要统计 52 种牌型每种牌型出现的次数。
- 处理时间有限制:我们希望能尽快得到统计结果。

怎么样,有没有感觉到大数据扑面而来?要知道我们“人型计算机”的“内存“和“硬盘”是有容量限制的,52 种牌型的信息已经超出了单台计算机的处理能力。
当然这里会有人提出质疑,认为扩充内存或者磁盘容量就可以解决这个问题,52 种牌型完全不需要分布式计算。那大家考虑一下假如这堆牌中有几百种、甚至几千种牌型呢?

所以 52 种牌是为了符合现实中的情况,让大家领会到单个计算机已经无法同时处理这么多数据了,我们需要多台计算机一起协作,是时候放出 MapReduce 这个大招了。
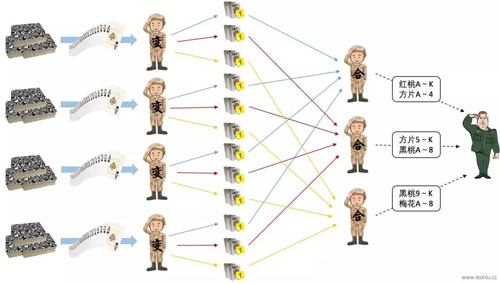
我个人在查阅一些资料、进行一些实践以后,认为 MapReduce 的技术可以简单地用四字诀来总结:分、变、洗、合,它们分别代表“切分”、“变换”、“洗牌”、“合并”四个步骤。
下面来看如何用四字诀解决大数据扑克牌问题。
切分
把输入数据切分成多份
既然单个“人型计算机”无法完全处理完所有的扑克,那么我们就把扑克牌随机分成多份,每份扑克牌由一个“人型计算机”来处理,个数不超过单个计算机的处理上限,而且尽量让每份的数量比较平均。

这里我们要讲一下角色分工的问题,多台计算机合作,肯定要有角色分工,我们可以把负责数据切分的“人型计算机”理解为“指挥官”,“指挥官”一般只有一个(在实际中可能有多个),统筹调度之类的工作都归他管。
负责执行具体运算任务的“人型计算机”则是“计算兵”,“计算兵”按照承担的任务不同分为“变计算兵”和“合计算兵”,前者负责第二步“变换”,后者负责***一步“合并”。
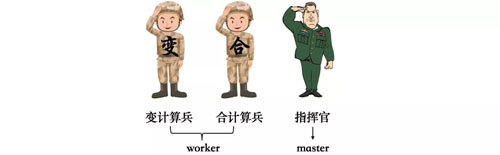
“计算兵”的总数当然是多多益善,但“变计算兵”和“合计算兵”各自所占的比例并不固定,可以根据数据的多少和运算的效率进行调整。
当兵力不够的时候,一个计算兵有可能承担两种角色,“指挥官”同时也有可能担任“计算兵”,因为在实际情况中一台计算机可以有多个进程承担多个任务,即理论上讲一个计算机可以分饰多角。
“指挥官”在切分扑克牌之前,会先分配好“变计算兵”和“合计算兵”的数量,然后根据“变计算兵”的数量把扑克拆分成相应的份数,将每份扑克分给一个“变计算兵”,然后进入下一步。
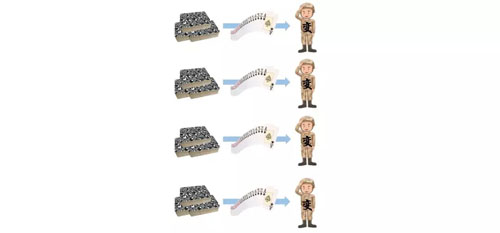
变换
把每条输入数据做映射变换(也就是 MapReduce 中的 Map)
每一个“变计算兵”都要对自己分得的每一张扑克牌按照相同的规则做变换,使得后续的步骤中可以对变换后的结果做处理。这种变换可以是加减乘除等数学运算,也可以是对输入数据的结构的转换。
例如对于我们这个扑克牌问题来讲,目的是为了计数,所以可以将扑克牌转换为一种计算机更容易处理的数值结构:将每张扑克牌上贴一张小便签,这条小便签上写明了其个数为 1。

我们把这种贴了标签的扑克牌叫做变种扑克牌。当在后续的步骤中统计牌型个数时,只需要把每个标签上的数字加起来就可以。
有的朋友肯定会好奇为什么不让每个“计算兵”直接统计各自的所有牌型的扑克的个数,这是因为这种“映射变换”运算的本质在于将每张扑克牌都进行同一种相同规则的变换,统计个数的工作要留在***一步完成。
严格的流水化操作,会让整体的效率更高,而且变换的规则要根据具体问题来制定,更容易适配不同种类的计算。
洗牌
把变换后的数据按照一定规则分组
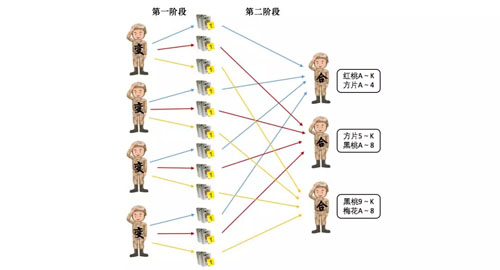
变换的运算完成之后,每个“变计算兵”要将各自的变种扑克牌按照牌型分成多个小份,每个小份要最终被一个指定的“合计算兵”进行结果合并统计。
这个过程就是“洗牌”,是“变计算兵”将变换后的扑克牌按照规则分组并分配给指定的“合计算兵”的过程。
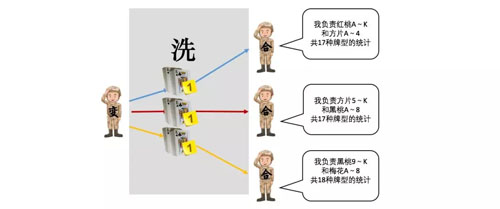
洗牌分两个阶段,***阶段是每个“变计算兵”将变种扑克牌按照一定的规则分类,分类的规则取决于每个“合计算兵”的统计范围,分类的个数取决于“合计算兵”的个数。
如上图所示,假设有 3 个“合计算兵”分别负责不同范围的牌型的统计,那么“变计算兵”需要根据每个“合计算兵”负责的牌型将自己的变种扑克牌分成 3 个小份,每份交给对应的“合计算兵”。
洗牌的第二阶段,“合计算兵”在指挥官的指挥下,去各个“变计算兵”的手中获取属于他自己的那一份变种扑克牌,从而使得牌型相同的扑克牌只会在一个“合计算兵”的手上。
洗牌的意义在于使相同牌型的变种扑克牌汇聚在了一起,以便于统计。
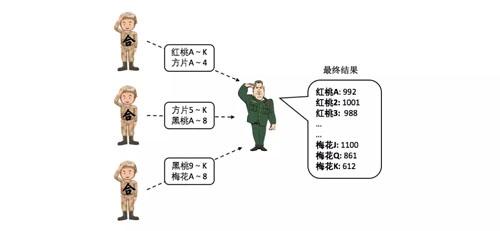
合并
将洗牌后的数据进行统计合并(也就是 MapReduce 中的 Reduce)
“合计算兵”将手中的变种扑克牌按照相同的计算规则依次进行合并,计算规则也需要根据具体问题来制定,在这里是对扑克牌上标签的数值直接累加,统计出最终的结果。
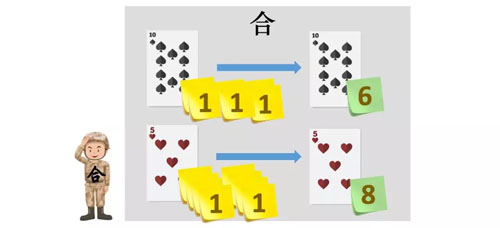
然后所有的“合计算兵”把自己的计算结果上交给“指挥官”,“指挥官”汇总后公布最终统计的结果。
总结
以上,“分变洗合”四字诀介绍完毕,完整过程如下:
分布式处理技术在逻辑上并不复杂,但在具体的实现过程中会有很多复杂的过程,譬如“指挥官”如何协调调度所有的“运算兵”,“运算兵”之间如何通信等等。
但对于使用 MapReduce 来完成计算任务的程序员来讲,这些复杂的过程是透明的。
分布式计算框架会自己去处理这些问题,程序员只需要定义两种计算规则:
- 第二步中变换的规则。
- 第四步中合并的规则。
正所谓大道至简,万变不离其宗,理解了 MapReduce 就理解了大数据分布式处理技术,而理解大数据分布式处理技术,也就理解了大数据技术的核心。
作者:卢亮
简介:资深软件研发工程师,擅长业务系统建模与架构分析,在分布式架构和大数据技术方面有深入的理论研究和实践经验。个人博客:www.leonlu.cc