人工智能通过多域卷积神经网络定位JPEG双重压缩图像伪造区域人简介:当攻击者想要伪造图像时,在大多数情况下,他/她将执行JPEG再压缩。根据不同的理论假设开发了不同的技术,但尚未开发出非常有效的解决方案。最近,基于机器学习的方法已经开始出现在图像取证领域,以解决各种任务,如采集源识别和伪造检测。在最后一种情况下,未来的目标是获得一个训练有素的神经网络,在给定待检查图像的情况下,可以可靠地定位伪造区域。考虑到这一点,我们的论文通过分析如何使用卷积神经网络(CNN)揭示和定位单个或双个JPEG压缩,从而向这个方向迈出了一步。已经考虑了对CNN的不同类型的输入,并且已经进行了各种实验以试图证明将要进一步研究的潜在问题。

现在,图像和视频作为主要信息来源的普遍性已经导致图像预测界越来越多地质疑其可靠性和完整性。涉及图片的上下文是不同的。一本杂志,一个社交网络,一个保险实践,一个审判的证据。这些图像可以通过使用强大的编辑软件轻松改变,通常不会对任何修改留下任何视觉痕迹,因此可靠地回答它们的完整性将成为最基本的。图像取证技术通过开发技术手段来处理这些问题,这些技术手段只能根据图像确定该资产是否已被修改,并且有时需要了解本地化篡改发生的情况。关于伪造品个性化,三种是迄今为止研究的主要类别的检测器:基于特征描述符[1,6,7],基于不一致阴影[10]和最后基于双倍JPEG压缩。
通过多域卷积神经网络定位JPEG双重压缩图像伪造区域人工智能贡献:近年来,机器学习和神经网络(如卷积神经网络(CNN))显示出能够提取复杂的统计特征并有效地学习其表示,从而能够很好地在各种计算机视觉任务包括图像识别和分类等。这些网络在很多领域的广泛使用促使和引导多媒体取证社区理解这些技术解决方案是否可以用于利用源识别[20,3]或用于图像和视频操纵检测。特别是,王等人。 [23]使用离散余弦变换(DCT)系数的直方图作为CNN的输入来检测单个或双重JPEG压缩,以检测篡改图像。 背后的主要思想是开发一种预处理模块,用于在训练CNN之前抑制图像内容;而在[16]CNN体系结构在没有预处理的情况下被提供补丁,被篡改区域的钻石被篡改。虽然对图像取证领域的神经网络的兴趣正在增长,但对其可能完成的一个真正的理解仍处于早期阶段。
本文向这个方向迈出了一步。我们的目标是训练一个神经网络,在给定待检查图像的情况下,通过分析单个或双重JPEG压缩区域的存在,能够可靠地定位可能的伪造区域。具体而言,已经提出了不同种类的基于CNN的方法,并给出了网络的不同输入。首先,利用基于空间域的CNN从RGB彩色图像开始执行图像伪造检测;既不进行预处理,也不采用边界信息。 CNN经过训练能够区分未压缩的单张和双张JPEG压缩图像,以显示主要(隐藏)JPEG压缩,然后定位伪造区域。其次,引入另一个基于频域CNN作为输入到网络的DCT系数的直方图,类似[23]。所提出的第三种方法是基于多域的CNN能够加入前面关于RGB补丁和DCT直方图的两个输入信息。这项工作的主要贡献是探索空间域CNN及其与图像伪造检测任务的频域组合的使用。已经进行了不同的实验测试,试图证明有待进一步调查和改进的潜在问题。
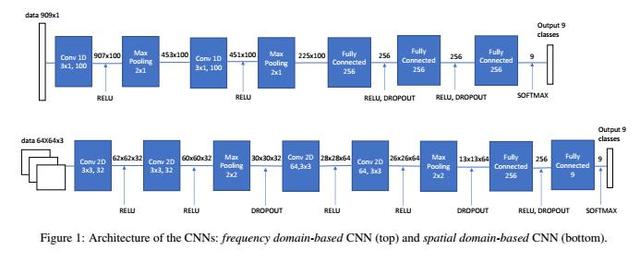
通过多域卷积神经网络定位JPEG双重压缩图像伪造区域人工智能基于CNN的提议方法在这项工作中,我们的目标是调查识别未压缩的单个或双重压缩图像的可能性,意图检测拼接攻击中涉及的图像区域。除此之外,我们的第二个目标是在应用二次压缩之前揭示应用于图像或贴片的主要品质因数。为了完成这项任务,基于给予网络和网络本身的输入数据设计了三种不同的基于CNN的方法。卷积神经网络由几个级联的卷积层和池层组成,后面是一个或多个完全连接的层。在所提出的方法中,每个被考虑的CNN在网络的组成部分如何组合在一起以及来自所使用的层数方面与其他方面不同,正如下面详细描述的那样。为了直接从数据中学习判别特征,训练阶段需要一套一致的标记图像。出于这个原因,对于所有考虑的方法,不同大小的图像被分成不同大小的片段(不重叠),然后将它们中的每一个都送入网络。与输入不同的是,这些方法不同,网络的输出是相同的。特别是,三种不同的CNN能够识别9类:未压迫的,单压缩的和双压缩的贴片(7个质量因子从60到95,逐步考虑5)。
通过多域卷积神经网络定位JPEG双重压缩图像伪造区域人工智能空间域CNN:在第一种基于CNN的方法中,命名为基于空间域的CNN,网络的输入是三个颜色通道(RGB)上的N×N尺寸补丁,预处理根本不被考虑,并且仅仅是数据的规范化在0和1之间)被执行。首先设计卷积网络[12],并在图1(上)中进行了总结。这个特定的网络由两个卷积块和两个完全连接的层组成。每个卷积块由两个卷积层组成,其中ReLU激活后面跟着一个汇聚层。所有卷积层使用3x3的内核大小,而共享层内核大小为2×2。为了防止过度拟合,我们使用Dropout,在完全连接的层次上随机丢弃训练时的单位。特别是,这种类型的CNN针对每个考虑的二次质量因子QF2 = 60:5:95进行训练。因此,我们获得了与QF2的每个值相对应的八个不同的分类器。每个分类器都需要为输入补丁输出两级分类。首先是未压缩的单压缩和双压缩补丁之间的类间分类。其次是QF1的内部类别(在60:5:95的范围内,不包括QF1 = QF2)在双重压缩补丁的情况下。因此,我们选择为每个QF1输出9个普通类,未压缩类,单个压缩类和一个类。结果,CNN的最后一个完全连接的层被发送到九路软最大连接,这产生了每个样本应被分类到每个类中的概率。作为损失函数,我们使用分类交叉熵函数[22]。我们注意到,错误分类双重压缩补丁的内部类型是错误的,而错误地将补丁的类别分类。因此,我们调整损失以将类内错误加权为类间错误的1/9。在我们的初步实验中,这改善了课堂内分类的准确性。所提出的CNN模型是基于来自由未压缩的单压缩贴片或双压缩贴片构成的训练集(即QF2 = 90和QF1从60变化到95)组成的标签贴片样本进行训练的。在测试阶段,八个训练的CNN中的一个(根据保存在JPEG格式的EXIF头中的质量因子进行选择)用于通过将补丁大小的滑动窗口应用于扫描来提取测试图像的基于补丁的特征整个图像,为每个补丁分配一个类,从而在图像级执行定位。
通过多域卷积神经网络定位JPEG双重压缩图像伪造区域人工智能频域CNN:在第二种提出的方法中,基于频域的CNN,根据[23]扩展评估系数数目的想法,对给定的补丁执行预处理,以计算DCT系数的直方图。详细地说,给定一个N×N片,提取DCT系数,并且对于每个8×8块,选择以之字形扫描顺序(DC被跳过)的前9个空间频率。对于每个空间频率i,j,建立表示量化的DCT值的绝对值的出现的直方图hi,j。具体而言,hi,j(m)是m =(50..0,+50)的i,j DCT系数的直方图中的值m的数量。因此,该网络共有909个元素(101个直方图箱×9个DCT频率)的矢量作为输入。再次,如前所述,训练8个CNN的阵列,它们中的每一个对应于第二压缩品质因子QF2的不同值。然后使用特征向量来训练每个CNN,以便区分之前定义的9个类别(未压缩,单一压缩和双重压缩,QF2固定和主要质量因子在QF1 = 60:5:95中变化)。所提出的CNN模型的架构如图1所示(下图)。它包含两个卷积层,然后是两个池连接和三个完整连接。输入数据的大小是909x1,输出是九个类的分布。每个完全连接的层有256个神经元,最后一个层的输出发送到九路softmax,这产生了每个样本应该被分类到每个类中的概率。在我们的网络中,每层都使用整流线性单元(ReLU)f(x)= max(0,x)作为激励函数。在两个完全连接的层中,使用Dropout技术。
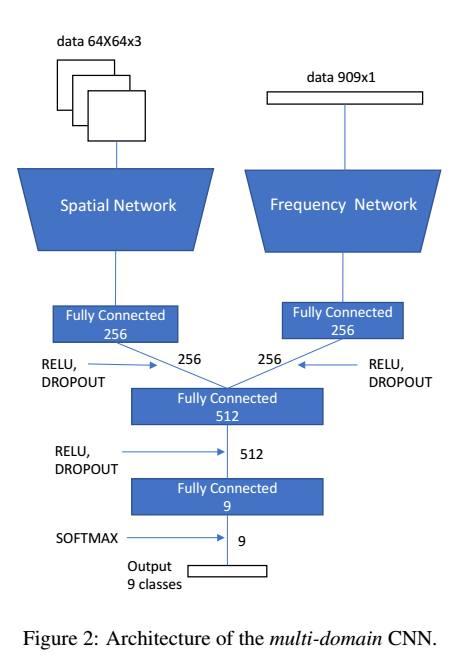
通过多域卷积神经网络定位JPEG双重压缩图像伪造区域人工智能多域CNN:第三个考虑的方法是一个多域CNN,其中三个通道色块和在该色块上计算的DCT系数的直方图用作网络的输入以便结合前两种方法。在图2中,提出的网络被描绘出来,它由一个基于空间域的CNN和一个基于频域的CNN组成,直到它们的第一个完全连接的层。基于多域的CNN学习来自R,G,B域和来自DCT的直方图的特征之间的模式间关系,将两个网络的完全连接层(每个256维)的输出连接在一起。通过这种方式,最后一个完全连接的层有512个神经元,并且输出被发送到九路softmax连接,这产生了每个样本也使用一个丢失层分类到每个类中的概率。因此,与之前一样,根据QF2的每个值设计八个不同的9类分类器。训练和测试阶段与以前一样进行。
通过多域卷积神经网络定位JPEG双重压缩图像伪造区域人工智能多域结论:在本文中,我们提出了采用卷积神经网络来检测拼接伪造的一个步骤。我们开始探索美国有线电视新闻网的能力,对未经压缩的单张和双张压缩图像进行分类和本地化。在最新的案例中,我们的方法也能够恢复原始压缩质量因素。我们提出了基于空间域的CNN及其与基于频率的CNN的组合,并将其应用于基于多域的方法。实验结果表明,空间域可以直接使用,并且当与频域相结合时,可以在DCT方法通常较弱(例如QF2 <QF1)的情况下导致优越的性能。一些尚未解决的问题仍有待探讨。首先,CNN体系结构的选择可能导致与在对象分类任务[11,18]中看到的非常不同的性能[11,18],其中使用更深的体系结构。其次,应该通过收集一个更大的数据集来探索需要多少数据来训练一个好的CNN模型。我们的结果表明,空间信息可以帮助DCT方法需要至少64x64的补丁来构建有用的统计信息。第三,应该提供CNN检测不同类型压缩(如JPEG 2000或有损PNG)的能力。我们有希望的结果表明,该工具可以检测以前压缩的细微特征,并学习预测再压缩时使用的第一个质量因子。