当一个系统业务数据量达到百亿条的时候,通常会引出一些问题:
1.数据怎么存储,存储到哪里
2.怎么保证数据安全,安全存储策略是什么
3.数据怎么检索,怎么做到快速响应
4.怎么对数据进行实时的统计分析
作为一款开源的定位于全文搜索引擎服务的Elasticsearch,可能是这些问题下比较高效的一种解决方案。那么,Elasticsearch的适用场景,能在什么地方发挥作用?Elasticsearch的特点优势又是什么?总的来说,涉及搜索的业务场景可能都会有Es的用武之地,下面将介绍Es的几种常见业务场景。
- 日志分析
问题引入:在复杂的计算机系统里面,一个系统可能由成千上百台服务器构成,很多系统不在一个地区机房,甚至有跨国家的;即使是在一个地区的系统,也有不同的来源,比如:操作系统、应用服务、业务逻辑等等。它们无时不刻都在产生新的各式各样的日志数据。
面对如此海量的分布在各个服务器上的日志数据,一旦我们需要去排查一些重要的信息,使用传统的方式登陆到一台台机器上查看显然有点力不从心。因此,建立一套集中式的日志管理系统,把不同来源的日志数据集中整合到一个地方再进行分析就显得尤为重要。
一套完整的集中式日志管理系统,主要包含以下几个功能:
- 采集-能够采集不同地区多种来源的日志数据
- 传输-能够稳定地把日志数据传输到中央系统
- 存储-能够安全的存储日志数据
- 分析-能够提供高效的日志数据分析,并可以支持UI展现
- 告警-能够提供监控机制,异常信息告警
解决方案:ELK
ELK是一套集中式日志管理方案,由ElasticSearch + Logstash + Kibana三个开源软件组成。UES基于ElasticSearch和Kibana开发,使用UES服务的ELK协议栈如下图所示:
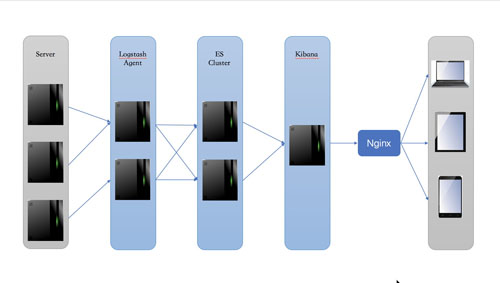
Logstash Agent收集不同来源的Server产生的日志,并存放到Elasticsearch集群中,而Kibana则从ES集群中查询数据生成图表,加上配置 Nginx 实现简单的用户认证,再返回给浏览器端。
Elasticsearch 是一个实时的分布式搜索和分析引擎,它可以用于全文搜索、结构化搜索以及分析。它是一个建立在全文搜索引擎 Apache Lucene 基础上的搜索引擎,使用 Java 语言编写。
Elasticsearch的主要特点:
- 分布式的实时文档存储系统
- 分布式的实时分析搜索引擎
- 多数据源,文档导向,所有的对象全部是文档
- 高可用性,易扩展,支持集群(Cluster)、分片和复制(Shards 和 Replicas)
- 支持插件机制
- restful风格接口,支持Json
Logstash 是一个具有实时渠道能力的数据收集引擎。它是一个完全开源的工具,可以对你的日志进行收集、过滤,并将其存储供以后使用。
Logstash主要特点:
- 几乎可以访问任何数据
- 可以和多种外部应用结合
- 支持弹性扩展
Logstash由三个主要部分组成:
- Shipper-发送日志数据
- Broker-收集数据,缺省内置 Redis
- Indexer-数据写入
Kibana 是一款基于 Apache 开源协议,使用 JavaScript 语言编写,为 Elasticsearch 提供分析和可视化的 Web 平台。它可以在 Elasticsearch 的索引中查找、交互数据,并生成各种维度的表图。
使用UES作为日志分析管理的案例分析如图所示:
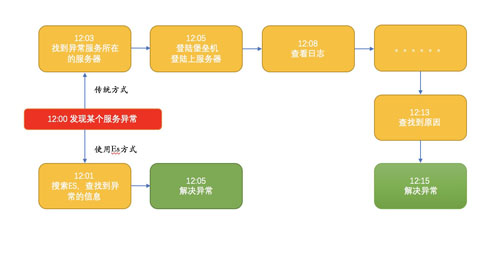
从案例中可以看出使用ELK技术来做日志管理和传统方式的对比。结果显而易见,使用ELK技术能在最短时间内解决问题,在日志管理方面更加便捷高效。
- 全文检索
如今,无论是互联网信息还是企业内部每天产生的信息,都在以指数级增长。对于企业内部,在每天产生的大量数据尤其是非结构化数据中,如何快速查找到对企业内部有用的信息,几乎成为每个公司开始关注的重点。
Elasticsearch在实现全文检索的过程中,首先要确定分词器,Es默认有很多分词器。一般中文分词器使用第三方的ik分词器、mmsegf分词器和paoding分词器,最初构建于lucene,后来移植于Es。目前在***版的Es中,使用的是ik分词器。UES已经内置安装了ik分词器,并且支持自定义分词词库。
当用户产生大量的文本数据时,Es均会将其进行分词并将这些词语保存在索引中,只需输入关键词进行查询,索引就能起到作用,查找对应的相同查询词,从而实现全文检索。全文检索的架构设计如下图:
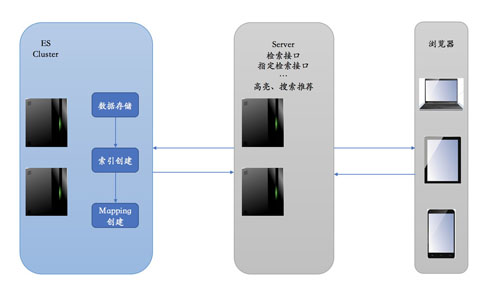
其中,Elasticsearch服务端进行数据索引存储,Server提供检索接口,浏览器端负责数据渲染和界面呈现。
- 传统数据库替代
随着Elasticsearch技术的发展,使得Es已经超越了其最初的纯搜索引擎角色,新增了数据聚合分析和可视化的特性。如果遇到***数量的文档需要通过关键词进行检索时,Es肯定是***选择。当然,如果文档格式是Json的,也可以把Es当作一种NoSQL数据库,对数据进行多维度的分析。
Elasticsearch是可以支持持久存储、统计等多项功能的现代搜索引擎,这种特性也决定了某些场景下Es可以作为主要的后端服务存储。Es替代传统DB的前提是业务不对操作的事务性有特殊要求,由于 Es的权限管理并不是特别完善,所以只把Es作为内部存储是可以替代传统数据库的。
还有一种场景:在一个已经运行了很长时间的复杂系统中添加检索服务。一种非常冒险的方法是重构系统以支持使用Es,而相对安全的方法是将Es作为新的组件添加到现有系统中。
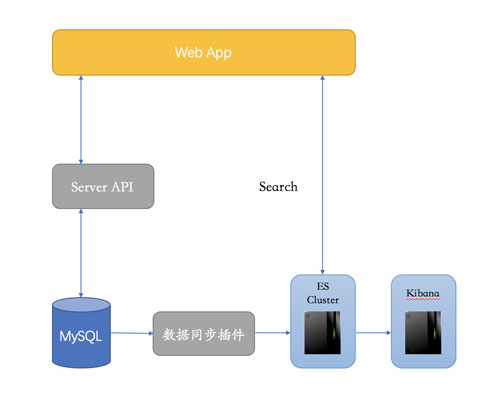
如图所示的MySQL数据库和Es集群存储,需要找到一种方式使得两存储之间实时同步,例如 logstash-input-jdbc 插件。
其实Elasticsearch的应用场景远不止这些,只有不断尝试,接触新的应用场景,我们才有机会获得更好解决方案的经验。UES作为一款平台产品推出,旨在应用到客户广泛的业务场景中,例如:
数据分析场景:分析网址、移动设备、服务器等非结构化和半结构化日志,分析传统数据库中数据,用于错误排查、应用程序监控、欺诈检测、游戏、广告等;
全文搜索场景:电商、O2O、企业等行业的搜索与导航服务;
实时统计分析场景:应用程序、用户点击等实时统计分析;
分布式文档处理场景:对Json支持友好,支持地理位置查询。
UES可以实现集群化的快速部署,极大降低人力运维成本。多种节点类型的提供、灵活的计费方式、支持业务动态扩容,此外集群丰富的预装插件和监控指标为用户集群使用功能和数据安全保驾护航。