












自从三月份生产、非生产全面上线 Kubernetes 后,本以为部署的问题可以舒一口气了,但是断断续续在生产、非生产环境发现一个诡异的问题,这礼拜又调试了三天,在快要放弃的时候居然找到原因了,此缺陷影响目前(2018-5-23)为止所有 Kubernetes 版本(见后面更新,夸大了),包括 GitHub 当前 master 分支,后果是某种情况触发下,Kubernetes service 不能提供服务,影响非常恶劣。
问题的现象是,在某种情况下,一个或者多个 Kubernetes service 对应的 Kubernetes endpoints 消失几分钟至几十分钟,然后重新出现,然后又消失,用 "kubectl get ep --all-namespaces" 不断查询,可以观察到一些 AGE 在分钟级别的 endpoints 要么忽然消失,要么 AGE 突然变小从一分钟左右起步。Endpoints 的不稳定,必然导致对应的 Kubernetes service 无法稳定提供服务。有人在 Github 上报告了 issue,但是一直没得到开发人员注意和解决。
首先解释下 Kubernetes 大体上的实现机制,有助于理解下面的破案过程。
Kubernetes 的实现原理跟配置管理工具 CFengine、Ansible、Salt 等非常类似:configuration convergence——不断的比较期望的配置和实际的配置,修订实际配置以收敛到期望配置。
Kubernetes 的关键系统服务有 api-server、scheduler、controller-manager 三个。api-server 一方面作为 Kubernetes 系统的访问入口点,一方面作为背后 etcd 存储的代理服务器,Kubernetes 里的所有资源对象,包括 Service、Deployment、ReplicaSet、DaemonSet、Pod、Endpoint、ConfigMap、Secret 等等,都是通过 api-server 检查格式后,以 protobuf 格式序列化并存入 etcd。这就是一个写入“期望配置”的过程。
Controller-manager 服务里包含了很多 controller 实例,对应各种资源类型:

v1.12.0-alpha.0/cmd/kube-controller-manager/app/controllermanager.go#L317
这些 controller 做的事情就是收敛:它通过 api-server 的 watch API 去间接的 watch etcd,以收取 etcd 里数据的 changelog,对改变(包括ADD、DELETE、UPDATE)的资源(也就是期望的“配置“),逐个与通过 kubelet + Docker 收集到的信息(实际“配置”)做对比并修正差异。
比如 etcd 里增加了一个 Pod 资源,那么 controller 就要请求 scheduler 调度,然后请求 kubelet 创建 Pod,如果etcd里删除了一个 Service 资源,那么就要删除其对应的 endpoint 资源,而这个 endpoint 删除操作会被 kube-proxy 监听到而触发实际的 iptables 命令。
注意上面 controller 通过 watch 获取 changelog 只是一个实现上的优化,它没有周期性的拿出所有的资源对象然后逐个判断,在集群规模很大时,这样的全量收敛是很慢的,后果就是集群的调度、自我修复进行的非常慢。
有了大框架的理解后,endpoints 被误删的地方是很容易找到的:
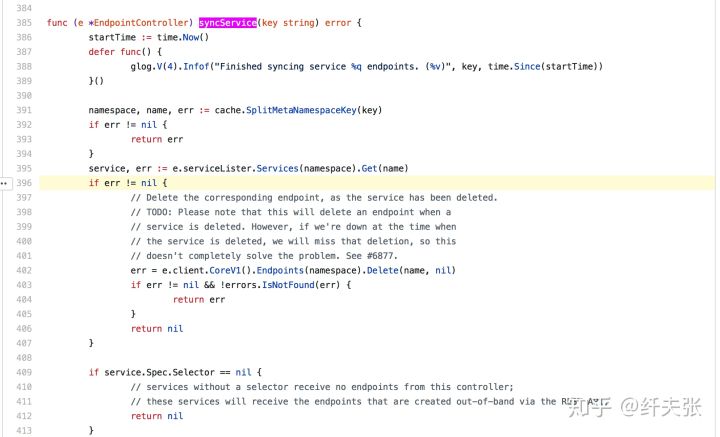
v1.12.0-alpha.0/pkg/controller/endpoint/endpoints_controller.go#L396
然后问题来了,什么情况下那个 Services(namespace).Get(name) 会返回错误呢?通过注释,可以看到在 service 删除时会走到 397 行里去,把无用的 endpoints 删掉,因为 endpoint 是给 service 服务的,service 不存在时,endpoint 没有存在的意义。
然后问题来了,通过 "kubectl get svc" 可以看到出问题期间,服务资源一直都在,并没有重建,也没有刚刚部署,甚至很多服务资源都是创建了几个月,为啥它对应的 endpoints 会被误删然后重建呢?这个问题困扰了我两个月,花了很长时间和很多脑细胞,今天在快放弃时突然有了重大发现。
由于我司搭建的 Kubernetes 集群开启了 X509 认证以及 RBAC 权限控制,为了便于审查,我开启了 kube-apiserver 的审计日志,在出问题时,审计日志中有个特别的模式:
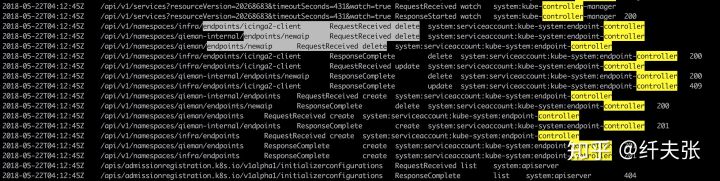
用 jq 命令摘取的审计日志片段
审计日志中,在每个 endpoint delete & create 发生前,都有一个 "/api/v1/services...watch=true" 的 watch 调用,上面讲到,controller-manager 要不断的去爬 etcd 里面资源的 changelog,这里很奇怪的问题是,这个调用的 "resourceVersion=xxx" 的版本值始终不变,难道不应该不断从 changelog 末尾继续爬取因为 resourceVersion 不断递增么?
通过一番艰苦卓绝的连猜带蒙,终于找到“爬取changelog”对应的代码:
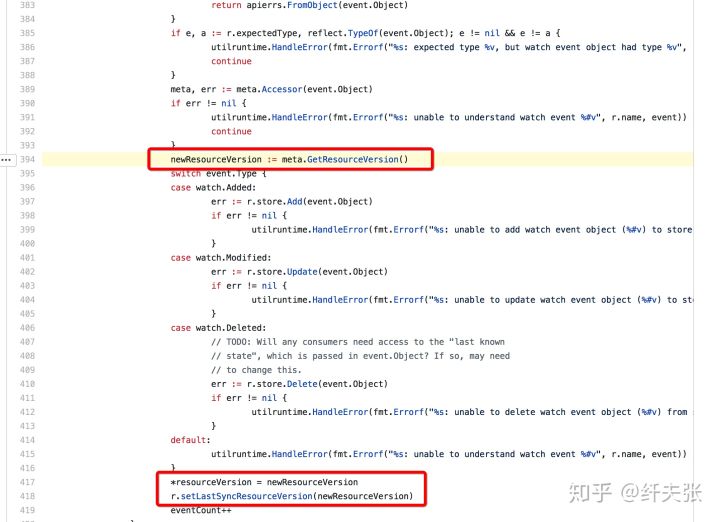
v1.12.0-alpha.0/staging/src/k8s.io/client-go/tools/cache/reflector.go#L394
上面的代码对 resourceVersion 的处理逻辑是: 遍历 event 列表,取当前 event 的 "resourceVersion" 字段作为新的要爬取的“起始resourceVersion",所以很显然遍历结束后,"起始resourceVersion" 也就是***一条 event 的 "resourceVersion"。
好了,我们来看看 event 列表涨啥样,把上面 api-server 的请求照搬就可以看到了:
- kubectl proxy
- curl -s localhost:8001/api/v1/services?resourceVersion=xxxx&timeoutSeconds=yyy&watch=t

/api/v1/services 的输出,仅示意,注意跟上面的审计日志不是同一个时间段的
可以很明显看到,坑爹,resourceVersion 不是递增的!
这个非递增的问题其实很容易想明白,resourceVersion 并不是 event 的序列号,它是 Kubernetes 资源自身的版本号,如果把 etcd 看作 Subversion,两者都有一个全局递增的版本号,把 Kubernetes 资源看作 Subversion 里保存的文件。 在 svn revision=100 时存入一个文件 A,那么A的版本是 100,然后不断提交其它文件的修改到 svn,然后在某个版本删掉 A,此时用 svn log 看到的相关文件的“自身***一次修改版本”并不是递增的,***一条的“自身***一次修改版本”是 100。
所以真相大白了,reflector.go 那段遍历 etcd "changelog" 的代码,误以为 event 序列的 resourceVersion 是递增的了,虽然绝大部分时候是这样的。由于这段代码是通用的,所有资源都受这个影响,所以是非常严重的 bug,之前看到很多人报告(我自己也遇到)controller-manager 报错 "reflector.go:341] k8s.io/kubernetes/pkg/controller/bootstrap/bootstrapsigner.go:152: watch of *v1.ConfigMap ended with: too old resource version: " 很可能也是这个导致的,因为它失误从很老的 resourceVersion 开始爬取 etcd "changelog",但 etcd 已经把太老的 changelog 给 “compact” 掉了。
***总结下怎么触发以及绕过这个 bug:
触发
陆续创建、删除、创建 Kubernetes service 对象,然后"kubectl delete svc xxx"删掉创建时间靠前的 service,也就是往 service event list 末尾插入了一条 resourceVersion 比较小的记录,这将使得 controller-manager 去从已经爬过的 service event list 位置重新爬取重放,然后就重放了 service 的 ADDED、DELETED event,于是 controller-manager 内存里缓存的 service 对象被删除,导致 EndpointController 删除了“不存在的”service 对应的 endpoints。
绕过
用 docker restart 重启 kube-controller-manager 容器,强迫其从 event list ***位置开始爬取
创建一个 service,其 resourceVersion 会是 etcd 的***全局版本号,这个 ADDED event 会出现在 event list 末尾,从而 controller-manager 从这个***的 resourceVersion 开始爬取
"kubectl edit" 修改某个 service,加点无意义的 label 之类的,保存,这样其 resourceVersion 也会更新,之后跟上一个 workaround 原理一样了。
错误的绕过方式
- "kubectl delete pod/xxx":不影响 service event list
- "kubectl delete deploy/xxxx":不影响 service event list
Kubernetes 里凡是创建后基本不变的资源,比如 service、configmap、secrets 都会受这个影响,它们的版本号都很久,删一个后都会触发这个 bug,比如 configmap,可能就会被重复的更新,映射到容器里的 config file 也就不断更新,对于不支持 config hot reload 的服务没有影响,对于支持 config hot reload 的服务,会频繁的重新加载配置文件重新初始化,可能导致意想不到的问题。
Bug 的修复很简单,在遍历 event list 选择 resourceVersion 时,总是取 max(event.resourceVersion, currentResourceVersion) 即可,我提了个 pull request 给 Kubernetes 官方看看,希望我这个粗暴的修正不会带来新的问题。















