【51CTO.com原创稿件】新浪微博不仅仅是一个信息交流平台,同时也兼具着媒体属性,据统计2013年12月新浪微博MAU(Monthly Active Users,月活跃用户数量)达到1.29亿,DAU(Daily Active Users,日活跃用户数量)超过6100万,到2018年3月,MAU突破4.11亿,DAU达到1.84亿。据2017年数据统计,微博的主要用户集中在23-30岁,占38.6%,性别上男性多于女性,占56.3%,而用户兴趣主要集中在明星、美女帅哥、动漫等泛娱乐领域。
这么庞大的用户体量和广泛的兴趣标签,如何做才能将用户感兴趣的话题、博主、事件***时间进行精准推送,是新浪微博一直要解决的事情,个性化push的应用将精准推送这项业务变的短时高效。

图1 新浪微博齐彦杰
博文质量、算法模型与分发效率共同决定push效果
在实现个性化push之前要先构建一个推荐系统,所有的推荐系统基本上都是从内容源头中去找到用户喜欢的东西,微博的源头就是全量的原创博文。但是面对每天几千万量级的生产量和大量不适宜的原创文章,如何才能将精准推送这个诉求变现呢?人工筛选加机器筛选是个不错的组合。在push推送过程中加入人工审核程序,可以降低涉黄、不健康、不适宜内容的传播,同时还减少了对用户的骚扰。
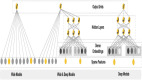
物料召回模型只是在源头处把握了原创博文的筛选,如何才能将优质文章推荐给感兴趣的用户呢?这就需要排序算法模型了。首先,将物料生成模型进行审核,筛选出全量优质的内容,放到物料池中,并且物料池要实时更新互动特征,比如,这个微博在当前的时间点的转发量和评论数等。更新以后,每分钟提取当前可用物料和用户,进行计算和排序,从中筛选出客户最感兴趣的博文,***发送给用户。其实,在我们的推荐系统中,和模型计算平行的还有一个协同推荐服务。有一些推荐系统中把协同推荐作为一种召回的方式,把协同推荐产生的内容放在物料召回的部分再做推荐。但是在我们的场景中,协同推荐效果好于排序模型,所以没有必要再走一遍程序,可以直接发送给用户。经过基础过滤下发,实时收集下发日志和点击日志,经过数据处理和加工,再去更新物料池,同时更新物料生成模型和运营审核部分。

图2 推荐系统
机器学习的特征维度建立
在排序策略、模型服务、特征工程、基础数据的整体架构下有博文信息、用户信息、行为信息等,利用这些信息在上层挖掘出特征,利用特征进行模型训练和评估,得出排序模型和物料模型。当有了模型之后,再把模型运用到线上做排序策略、CTR预估。***,将线上的数据再传导回来,进行基础数据计算,供下一次模型训练迭代。
兴趣维度
但是,对于一个博文来说,特征构建的时候需要通过一个三级标签体系来具像这个博文代表的意义,以及通过用户对博文的浏览程度来呈现用户的兴趣,这时就会建立一个三级标签体系,首先***级标签是比较宽泛的,比如说体育领域,一级标签下面会有二级标签,比如:足球,二级标签下面会有三级标签,比如:梅西、C罗。当一个用户消费了多个打上梅西标签的博文的时候,我们就知道这个用户对梅西感兴趣,所以,当有一个梅西的物料进来的时候,就会用到这部分特征,加入到模型中进行训练,再推送给兴趣用户,这个就是兴趣维度。

图3 兴趣维度
关系维度
兴趣维度是一个用户对兴趣领域的特征描述,但是如果想把博主与用户,也就是人与人之间的特征描述加入到模型当中,就需要关系维度了。当一个博主和一个用户在历史上的互动非常高的话,那么这个博主一定是契合这个用户的需求的,所以他们的关系也可以作为一个维度特征加入到模型当中。
实时维度
将兴趣维度、关系维度加入到模型的同时,还需要将先验数据传导回来,这时候就需要实时维度的帮助。因为Push场景用的物料相对少一些,同时曝光机会也特别少,而点击率就可以作为先验数据传导回来,导入到模型中。
除了以上三种维度,还包括环境的维度,推送的时间、设备的网络信息、设备本身的信息等等。
介绍完特征部分之后,再讲一下模型演进的过程。升级从LR(Logistic Regression,逻辑回归)模型开始,LR模型基本上比较难以捕捉用户的组合特征,所以进一步升级到FM模型。FM( Factorization Machine,隐因子分解机)模型是LR模型加上Dense(密集化)的两两特征组合。每一个两两组合特征,需要有一个权重Wij,如果直接求Wij,因为特征组合会造成样本过少,导致Wij不准确,所以是通过因子Vi,Vj相乘的形式来得到Wij。但是,FM模型只做了两两组合特征,所以又升级成了wide&deep模型,通过把wide模型和deep模型进行组合,既保留了wide模型里面的记忆能力,又有一些高级特征组合模型的能力,使这样一个模型能够有更强的表现能力。

图4 Wide&deep模型
Push在使用中的实用技巧
利用用户频次(频率+次数)拆分提高点击量和点击率
微博使用中用户的频次差异很大,因此要将用户的频次进行拆分,分别训练高频次、中频次和低频次的用户,所以需要在负样本的选择上做一些改变。
在服务器推送的时候,会遇到用户设置系统不提醒新消息的状况,也会遇到用户不看新消息的状况,所以,在选择推送用户的时候,尽量选取历史上有过正样本的用户,这样,用户在获得正样本复发的时候,在正样本上下几条曝光(其中包含两条负样本),就可以提高点击量和点击率。
逐层控制下发物料
如果一个物料在没有经过充分验证的情况下,就对所有的人进行计算,可能因为某一个特征特别高的时候,使下发产生过大,这样可能把一个低质物料展现给过多用户。所以首先要在一个特别小的范围内进行尝试,如果点击率达到预期,则会逐渐一层一层扩大,直到放到全量。这个方式,可以控制低质物料下发范围,同时把曝光机会让给经过充分验证的优质物料。
以上内容是51CTO记者根据新浪微博齐彦杰在WOT2018全球软件与运维技术峰会的演讲内容整理,更多关于WOT的内容请关注51cto.com。