介绍
现今,HBase 所支持的现代产品对Hbase读写性能的期望越来越高。理想情况下,HBase 也希望在保证其可靠的持久存储的前提下能同时享有内存数据库的速度。社区的贡献者在HBase 2.0中引入了一种名为Accordion的新算法,这促使Hbase又朝着其理想的目标迈出了重要的一步。
Hbase RegionServer 负责将数据划分到多个Region中。RegionServer 内部(垂直)的可伸缩性能对于最终用户体验以及整个系统的利用率至关重要。Accordion 算法通过更好地利用RAM来进一步提高RegionServer的可扩展性。Accordion 算法可以实现在内存中容纳更多的数据,并且降低写入磁盘的频率。这正好是多个场景下我们所需要的。首先,HBase的磁盘占用和写入放大因此减少;其次,更多数据的读取和写入将直接从RAM中获得,更少的读取和写入基于磁盘I/O,换句话说,HBase的性能得到提高。在2.0版本之前,这些不同的指标是不能同时满足的,并且相互制约。而通过Accordion 算法,它们都同时得到了改善。
Accordion 的灵感来自于HBase的LSM树形设计模式。一个 HBase Region 被存储为一系列可查找的键值对映射。最上面是一个可变内存存储,称为MemStore ,接收***Put进来的数据。其余的是不变的HDFS文件,称为HFile 。一旦MemStore写满,它将被刷新到磁盘,从而创建一个新的HFile。HBase采用多版本并发控制,也就是说,MemStore将所有修改后的数据存储为独立版本。因此,一条数据的多个版本同时驻留在MemStore和HFile层中。当一个读操作进来,Hbase会优先扫描BlockCache中的Hfile拿取***的版本数据。为了减少磁盘访问次数,HFile在后台异步进行压缩合并,这个过程将真正清除已删除的数据,合并小的HFile文件。
通过将随机 application-level I/O转换为顺序磁盘I/O,LSM树可提供出色的写入性能。但是,传统的设计并未尝试压缩内存数据。这源于历史原因:LSM树设计当时,RAM还是非常紧缺的资源,因此MemStore的容量很小。随着硬件环境的不断变化,由RegionServer管理的整个MemStore可能为数千兆字节,这就为Hbase优化留下了大量空间。
Accordion 算法重新将LSM原理应用于MemStore,以便当数据仍在RAM中时消除冗余和其他开销。这样做可以减少Flush到HDFS的频率,从而减少写入放大和整个磁盘占用空间。随着刷新次数的减少,MemStore写入磁盘的频率会降低,因此写入性能会提高。磁盘上的数据较少也意味着对块缓存的压力较小,***率较高,更佳的读响应。***,减少磁盘写入也意味着在后台发生较少的压缩,即读取和写入周期将缩短。总而言之,内存压缩算法的效果可以被看作是一个催化剂,使整个系统的运行速度更快。
目前Accordion提供了两个级别的内存压缩:basic 级别和 eager 级别。前者适用于所有数据更新模式的通用优化,后者对于高数据流的应用程序非常有用,如生产-消费队列,购物车,共享计数器等。所有这些使用案例都会对rowkey进行频繁更新,生成多个冗余版本的数据,这些情况下Accordion算法将发挥其价值。但另一方面,eager 级压缩优化可能会导致更大的计算开销(更多内存副本和垃圾收集),这可能会影响数据写入时的响应时间。如果MemStore开启了 MemStore-本地分配缓冲区(MSLAB)配置则开销会很高。所以建议不要将此配置与eager级压缩结合使用。
如何使用
内存压缩可以在全局和列族级别进行配置。支持三种级别配置:none (传统实现), basic, and eager。
默认情况下,所有表都是basic内存压缩。可以在hbase-site.xml中覆盖写这个全局配置,如下所示:
- <property>
- <name> hbase.hregion.compacting.memstore.type </name>
- <value> <none|basic|eager> </value>
- </property>
还可以在HBase shell中为每个列族进行单独配置,如下所示:
- create '<tablename>',
- {NAME =>'<cfname>',IN_MEMORY_COMPACTION =>' <NONE|BASIC|EAGER>' }
性能增益
我们通过广受欢迎的雅虎云服务基准测试YCSB对HBase进行了广泛的测试。我们的实验使用了100-200 GB数据集,并且执行了各种具有代表性的工作负载。结果表明Accordion算法所带来的性能增益得到的显著提升。
重尾 (Zipf) 分布:***个实验会执行一个工作负载,其中rowkey遵循大多数现实生活场景中出现的Zipf分布。在这种情况下,当100%的操作是写入操作时,Accordion实现写入放大率降低30%,写入吞吐量提高20%,GC降低22%。当50%的操作是读取时,尾部读取延迟减少12%。
均匀分布:第二个实验的工作量是所有rowkey都均衡分布。在此情况下,在100%写入的情况下,Accordion的写入放大率降低25%,写入吞吐量提高50%,GC降低36%。尾部读取延迟不受影响(由于没有本地化,这是预期的)。
Accordion如何工作
高级设计
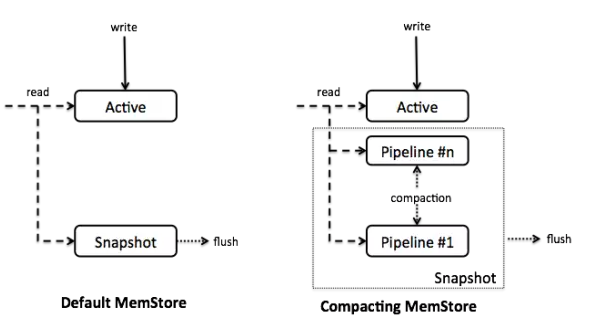
Accordion推出了CompactingMemStore,一个内部使用压缩策略的MemStore实现。与默认的MemStore相比,它将所有数据保存在一个单片数据结构中,Accordion将其作为一连串的segment来管理。***的segment,称为active segment(段),是可变的,用来接收Put操作。一旦达到溢出条件(默认情况下,32MB-25%的MemStore大小),active segment 被移动到管道( in-memory pipeline)中,并置为不可变segment,我们称之为内存刷新(in-memory flush)。Get 操作通过扫描这些 segment 和 HFiles 拿取数据(后者通过块缓存进行访问,与往常访问HBase一样)。
CompactingMemStore 可能会不时在后台合并多个不可变段,从而创建更大更精简的段。因此,管道是“会呼吸的”(扩张和收缩),类似于手风琴波纹管,所以我们也将Accordion 译为手风琴。
当RegionServer决定刷新一个或多个MemStore到磁盘以释放内存时,它会考虑刷新CompactingMemStore中已经移入管道中的segment到磁盘。基本原理是延长MemStore有效管理内存的生命周期,以减少整体I / O。当刷新发生时,管道中所有的segment 段将被移出合成一个快照, 合并并流式传输形成新的HFile。
图1显示了CompactingMemStore与传统设计的结构。
分段结构:
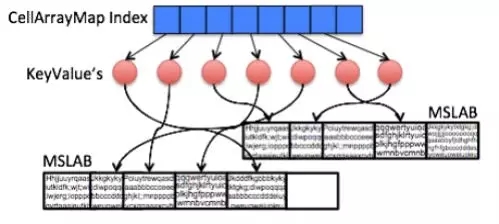
与默认的MemStore类似,CompactingMemStore在单元存储之上维护一个索引,以允许通过键快速搜索。不同的是,MemStore索引被实现为一个Java skiplist(ConcurrentSkipListMap ), 一种动态但奢侈的数据结构,用于管理大量小对象。CompactingMemStore 则在不可变的 segment 索引之上上实现了高效且节省空间的扁平化布局。这种通用优化可以帮助所有压缩策略减少RAM开销,使数据几乎不存在冗余。一旦将一个段添加到管道中,CompactingMemStore 就将其索引序列化为一个名为CellArrayMap 的有序数组,该数组可以快速进行二进制搜索。
CellArrayMap既支持从Java堆内直接分配单元,也支持MSLAB的自定义分配(堆内或堆外),实现差异通过被索引引用的KeyValue对象抽象出来(图2)。CellArrayMap本身始终分配在堆内。
压缩算法
内存中压缩算法在管道中的Segment上维护了一个单一的扁平化索引。这样的设计节省了存储空间,尤其是当数据项很小时,可以及时将数据flush至磁盘。单个索引可使搜索操作在单一空间进行,因此缩短了尾部读取延迟。
当一个active segment被刷新到内存时,它将排队到压缩管道,并立即触发一个异步合并调度任务。该调度任务将同时扫描管道中的所有段(类似于磁盘上的压缩)并将它们的索引合并为一个。basic和eager 压缩策略之间的差异体现在它们处理单元数据的方式上。basic压缩不会消除冗余数据版本以避免物理复制; 它只是重新排列KeyValue对象的引用。eager压缩则相反,会过滤出冗余数据。但这是以额外的计算和数据迁移为代价的。例如,在MSLAB存储器中,幸存的单元被复制到新创建的MSLAB中。当数据高度冗余时,压缩开销的代价就变得有意义了。
未来的压缩可能会在basic压缩策略和eager压缩策略之间实现自动选择。例如,该算法可能会在一段时间内尝试eager压缩,并根据所传递的值(如:数据被删除的比例)安排下一次压缩。这种方法可以减轻系统管理员的先验决定,并适应不断变化的访问模式。
结束语
本文,我们介绍了Accordion的基本原理,配置,性能增益以及内存压缩算法的一些细节。如有纰漏之处,还望多多指教。