本系列:
- 《手把手教你写网络爬虫(1):网易云音乐歌单》
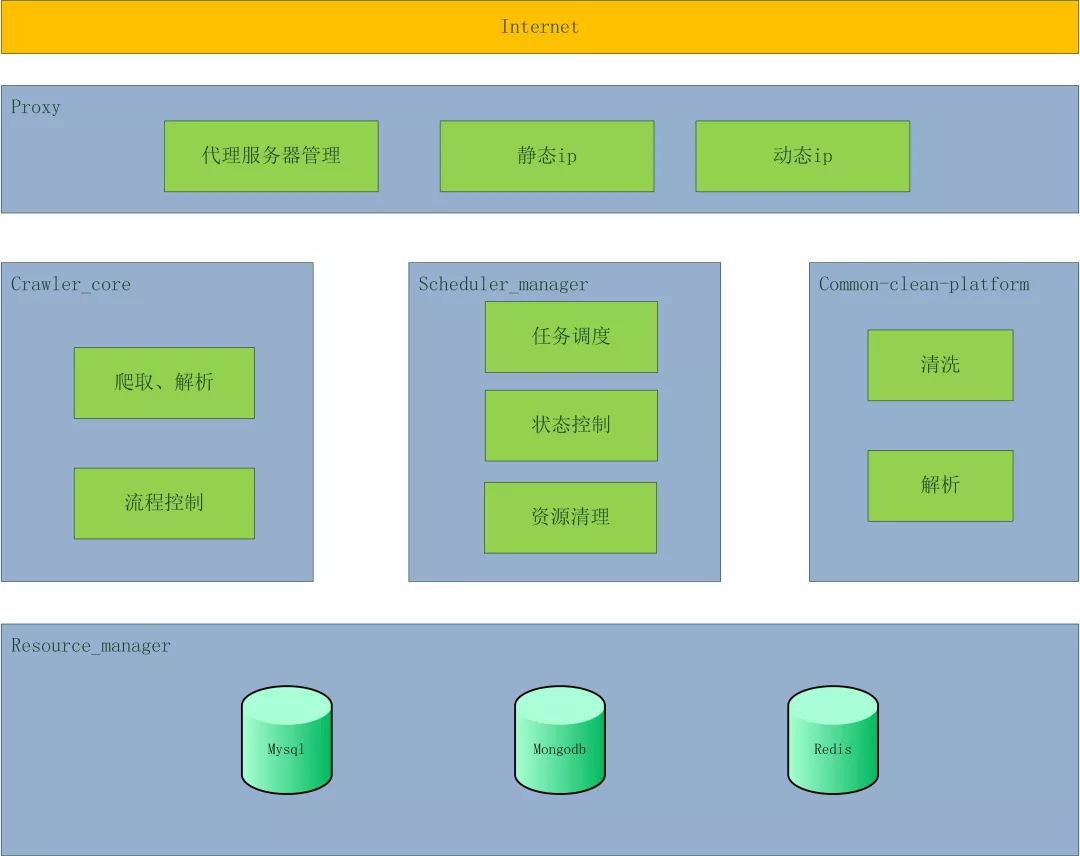
- 《手把手教你写网络爬虫(2):迷你爬虫架构》
- 《手把手教你写网络爬虫(3):开源爬虫框架对比》
- 《手把手教你写网络爬虫(4):Scrapy入门》
- 《手把手教你写网络爬虫(5):PhantomJS实战》


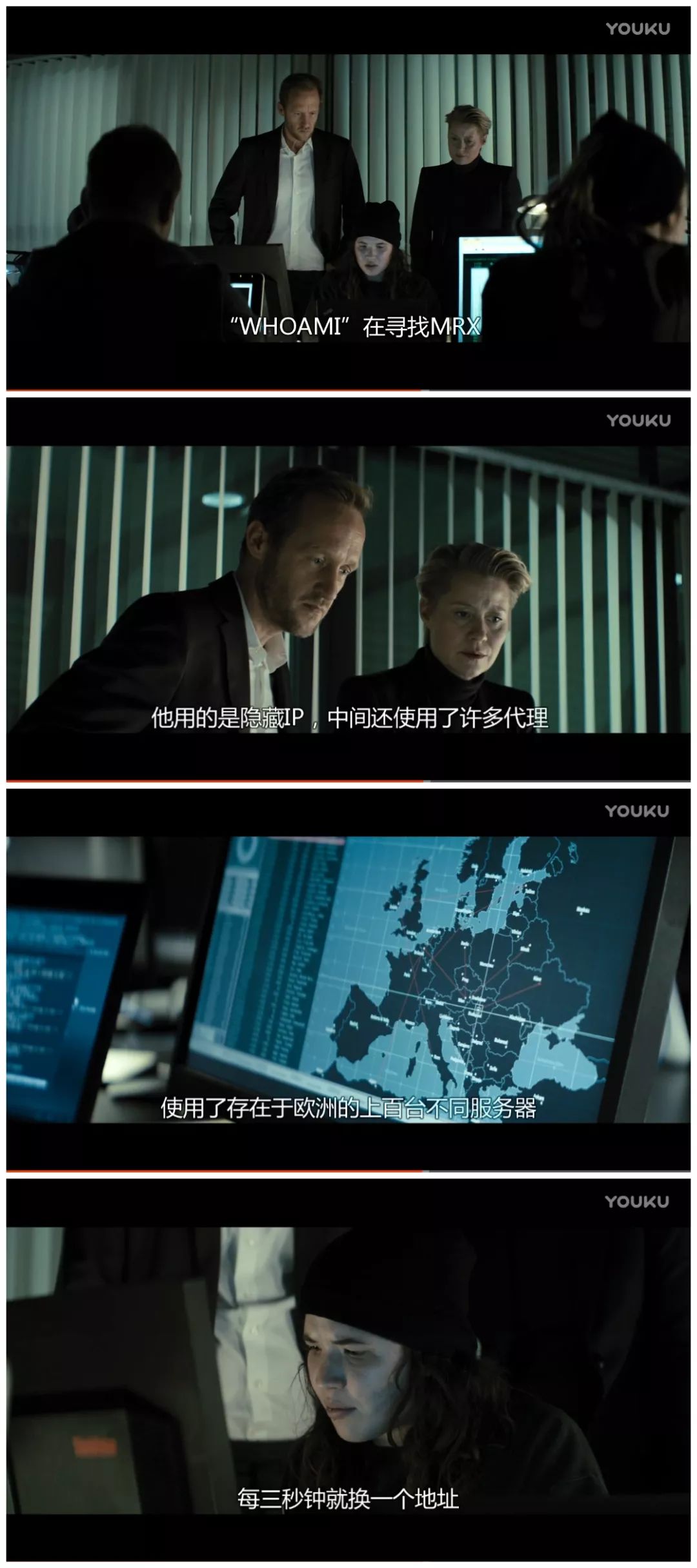
笔者以前看过一个电影叫《Who Am I – No System Is Safe》,剧中的黑客老大“Who Am I”就用代理来隐藏自己,躲避FBI和其他黑客组织的追踪。

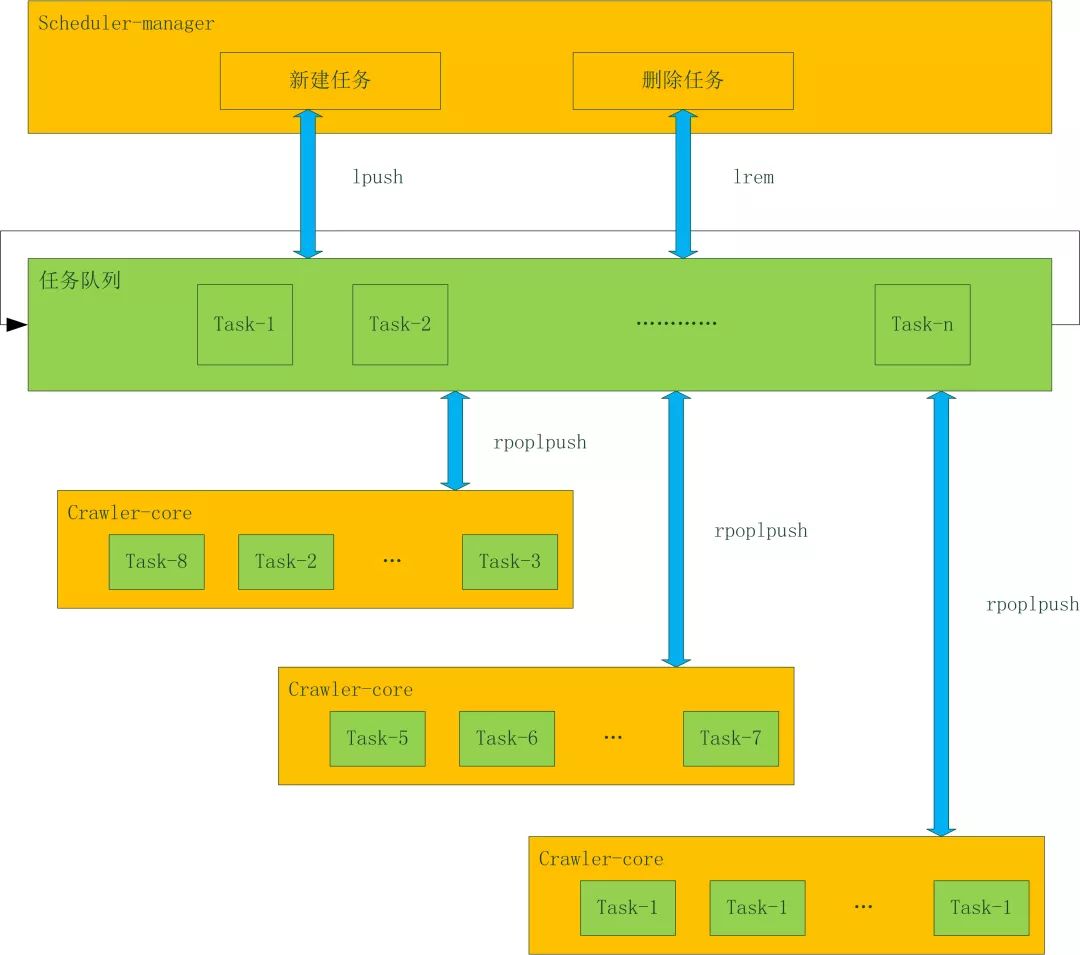

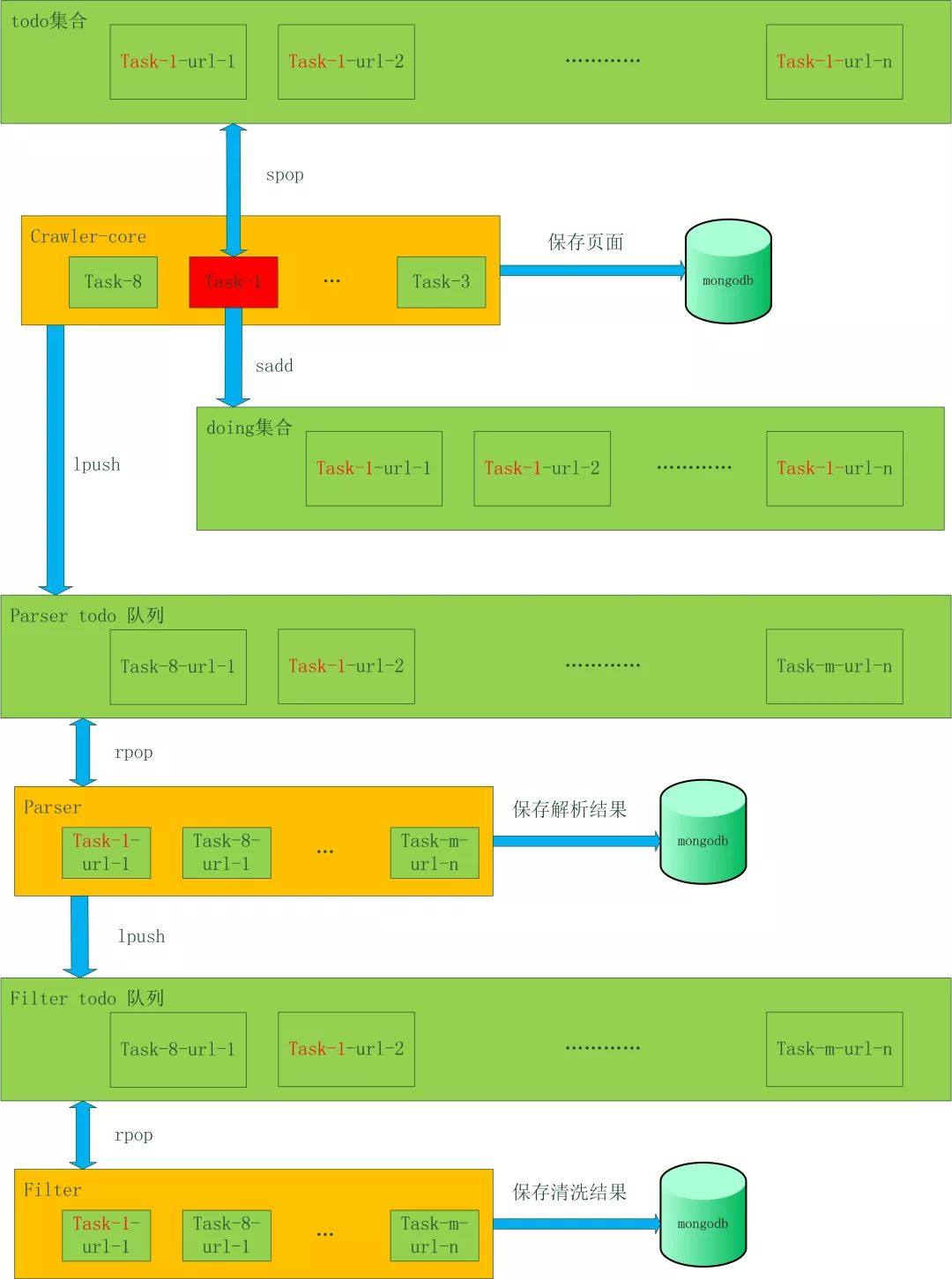

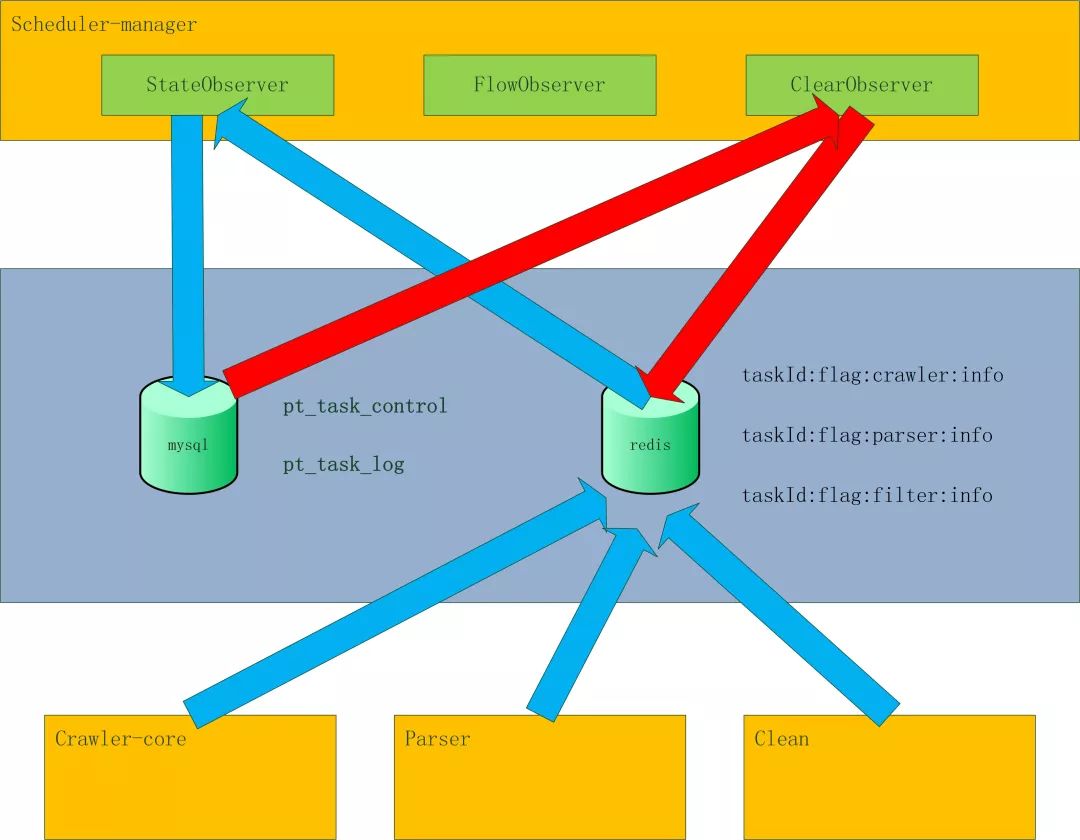

| taskId:flag:crawler:info | ||
| Filed | value | 说明 |
| totalCnt | 10000 | 抓取的url总数:抓取完成,不管成功失败,都加1 |
| failCnt | 0 | 抓取的url失败数:抓取失败,加1 |
| switch | 1 | 任务状态:0:停止,1:启动,2:暂停,3:暂停启动 |
| priority | 1 | 任务优先级 |
| retryCnt | 0 | 重试次数 |
| status | 0 | 任务执行状态:1:进行中,2:完成 |
| Ref | 0 | url引用数:每消费一个url,减1;生成一个url,加1。等于0则任务完成 |
| maxThreadCnt | 100 | 任务的***线程数 |
| remainThreadCnt | 10 | 剩余可用线程数 |
| lastFetchTime | 1496404451532 | 上一次抓取时间 |
|
taskId:flag:parser:info |
||
| Filed | value | 说明 |
| totalCnt | 10000 | 解析总数:解析完成,不管成功失败,都加1 |
| failCnt | 0 | 解析失败数:解析失败,加1 |
| crawlerStatus | 0 | 爬取状态:0:进行中,2:完成 |
| ref | 10 | url引用数:crawler每保存一个网页,加1;parser每解析完成一个网页,减1。等于0不说明任务完成。若crawlerStatus等于2,ref等于0,则任务完成。 |
|
taskId:flag:filter:info |
||
| Filed | value | 说明 |
| totalCnt | 10000 | 清洗总数:清洗完成,不管成功失败,都加1 |
| failCnt | 0 | 清洗失败数:清洗失败,加1 |
| crawlerStatus | 0 | 解析状态:0:进行中,2:完成 |
| ref | 10 | url引用数:parser每保存一条数据,加1;filter每清洗完成一条数据,减1。等于0不说明任务完成。若parserStatus等于2,ref等于0,则任务完成。 |
流程控制 – failover
如果一个Crawler_core的机器挂掉了,就会开始数据恢复程序,把这台机器所有未完成的任务恢复到公共缓存中。