【51CTO.com原创稿件】深度学习是机器学习中一种基于对数据进行表征学习的方法,与传统靠手工设计特征的机器学习算法不同,深度学习能根据不同任务自动学习数据的特征。
目前深度学习在语音、图像、视频处理上已经取得了令人印象深刻的进步,但是它通常需要功能强大的电脑才可以运行,如果它出现在我们的手机上呢?
2017 年 12 月 1 日-2 日,由 51CTO 主办的 WOTD 全球软件开发技术峰会在深圳中州万豪酒店隆重举行。
本次峰会以软件开发为主题,黄文波先生在软件性能优化专场与来宾分享"深度学习在移动端的优化实践"的主题演讲,为大家详细阐述深度学习模型在移动端的设计和优化策略等问题。
讨论涉及到如下三个方面:
- 为什么做深度学习的优化
- 深度学习在移动端的优化实践
- 总结
为什么做深度学习的优化?
深度学习近年来虽然特别火,但是由于计算量巨大,其对应的模型动辄就有上百兆。
要想把深度学习放在只能分配出几十兆空间给单个 App 的手机上,我们就需要从算法层面上极致地缩小其模型。

这两年来,深度学习的发展趋势是将大部分应用都放置到云端,而使用的设备一般是 GPU。
但是如果真要实现 AI,单靠云端的算法是远远不够的,因为在一些应用的场景中,计算必须在本地进行。
例如:苹果的 Face ID,如果仅放在云端,那么一旦手机没有了信号,用户岂不是无法使用手机了?
同理,无人驾驶需要及时响应外部环境,包括识别车外的人、交通灯等,那么如果网络发生了延迟,岂不是会发生交通事故?因此,许多应用都必须将计算放置在本地。

蘑菇街为什么会做深度学习的优化?主要原因有如下几点:
- 服务器:我们通过减少训练、预测的时间,来缩小模型。节约 GPU 资源和省电,这对于深度学习来说是非常重要的因素。
例如 Alpha GO 下一盘棋,需要 1920 个 CPU 到 280 多个 GPU,其耗费的电费约为 3000 美元。同样,蘑菇街就算使用的是 GPU,其电费也有上万元。
- 移动端:实时响应需求。通过本地化运行处理,我们不需要将图片传到服务器上,也不会侵犯用户的隐私。
CNN(卷积神经网络)基础

深度学习对于图像处理的理念是:经过层层滤波与筛选,最终得到结果。
它的典型流程为:输入(INPUT)经过卷积层(CONV)和激活层(RELU)的特征提取,再经过池化层(Polling)的压缩与降维,最后由全连接层(FC)连接所有的特征,并输出图像归属类型的概率。
如上图所示左边的图片经过了多层处理后,最后得出它属于 car 的概率最高,因此我们可以认为它是一辆车。
该示例只有 10 层左右,而在实际场景中,层数会更多,甚至能达到 100 多层。

对于上方简易示图的识别,实际上它经历了 CNN 的成百上千万次计算,才最终得到结果。
深度学习应用挑战
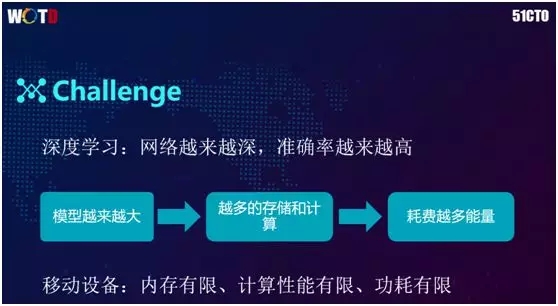
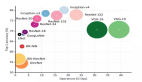
深度学习领域的发展趋势是:随着其网络日渐加深和大数据驱动所导致的数据激增,训练结果的准确率也会越来越高。
伴随着网络越来越深,会出现一个问题:深度学习模型越来越大,用于计算所需耗费的资源也就越来越多。
与此同时,由于手机不像服务器可以使用性能强大的 GPU,因此手机的计算性能受到了限制。
另外,由于手机上 CPU 和电池容量暂时无法被突破,其功耗也会相应地受到限制。
深度学习在移动端的优化实践
模型压缩的两类方式
将深度学习放置到手机上,可以从两个方面入手:
- 模型压缩,现有的模型一般具有 100M~200M,其准确率非常高。因此我们在拿到模型后,需要进行压缩。
- 设计网络,将网络设计得非常小,同时保证网络具有很强的表达能力。
模型压缩
在算法层面对模型的压缩主要采取了三种方式:
- 剪枝(Pruning)
- 量化(Quantization)
- 霍夫曼编码(Huffman Encoding)
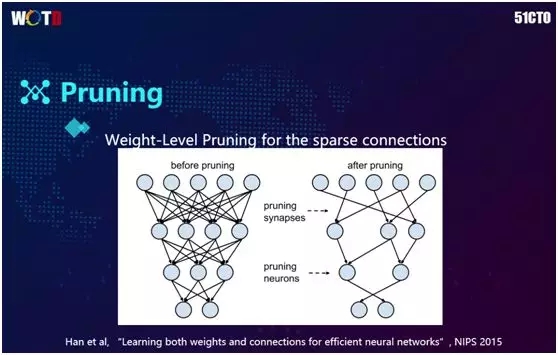
剪枝的方法较为直观,它的思想是:在训练神经网络时,每个神经元会有一个权重,而权重具有大小之分。其中权重小的表示对最终结果的影响力非常小。
因此在 2015 年刚开始研究时,有人提出在不会影响到最终结果的情况下,将这些小的权重砍掉(Remove)了。
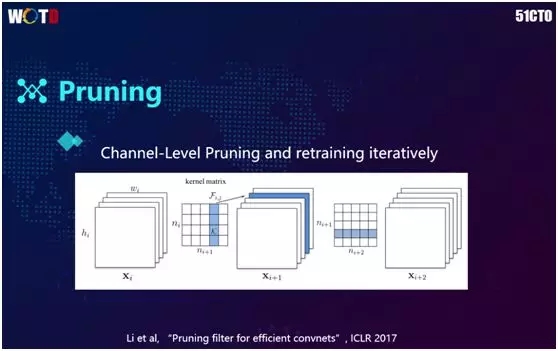
前面提到的“砍”权重的做法对于内存是很不友好的。例如卷积里有 3×3 的矩阵,如果仅部分被砍的话,实际计算还要去往被砍处,从而造成了内存的不连续。
因此有人提出将 Filter 一并砍掉,在将整个 3×3 全部砍掉之后再予以训练,以达到较好的效果。
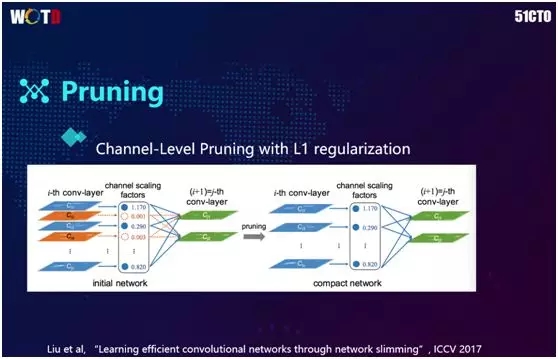
2017 年,有人提出通过对每个通道添加一个 scale 因子对网络进行训练,然后选择把 scale 值比较小的卷积全部砍掉(如上图中橙色处所示),以方便对内存进行高效地操作。
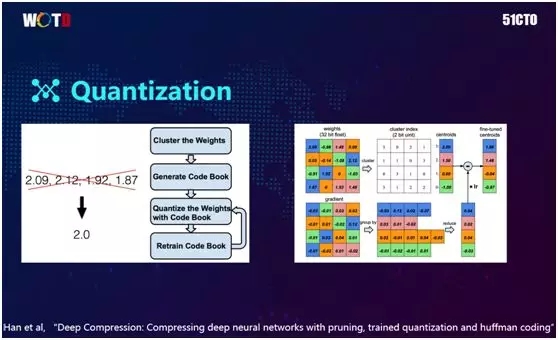
除了砍掉网络,我们还可以通过量化来将其做得更小。如上图所示的 3×3 权重,在实际存储时权重都是浮点数(Float),而存储每个浮点数都需要 32 比特位。
因此量化的思想是把这 9 个浮点值进行聚类,分别聚到四个类中,那么我们在存浮点时就只需要存这四个浮点数即可。
对于这些值的表达,我们可以通过 Index 来实现。由于此处已聚了四个类,我们在 Index 时,只需两个便可以表达了,即 2 的 2 次方正好是 4,正好表达出了四个数。
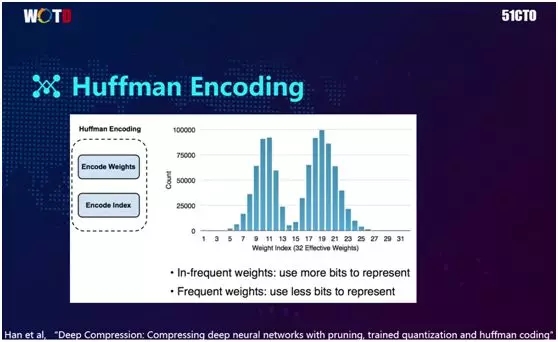
想必大家在学习数据结构时都了解过霍夫曼编码。它的思想是:由于部分权重的出现次数远高于其他权重,因此对于出现次数较多的权重,我们可以用更少的比特位来编码。
而对于出现次数较少的权重,则用较大的比特位来表达。那么该方法可以在总体 Index 为已知的角度,直接用固定的位数进行存储,从而节约了空间。
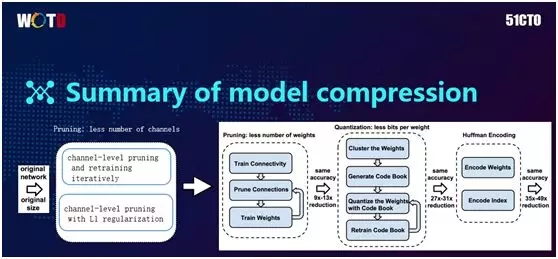
模型压缩的流程是:进行 channel 级别的权重剪枝→对权重进行量化→聚类到固定的几个类中→将量化后的 Index 通过霍夫曼编码进行进一步压缩。
设计网络
另一个压缩的思路是设计小网络,它主要有三种方式:
- SqueezeNet
- MobileNet
- ShuffleNet
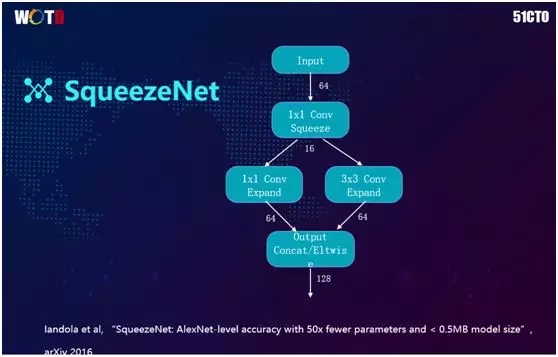
SqueezeNet 的核心思想是在做下一个 3×3 的卷积时,先进行一个 1×1 的卷积,将以前的 64 维降到 16 维,然后在此 16 维的基础上再进行 3×3 的卷积。
这样就相当于在做 3×3 的卷积之处比原来降低了 4 倍,也就是将模型降低到原来的四分之一。
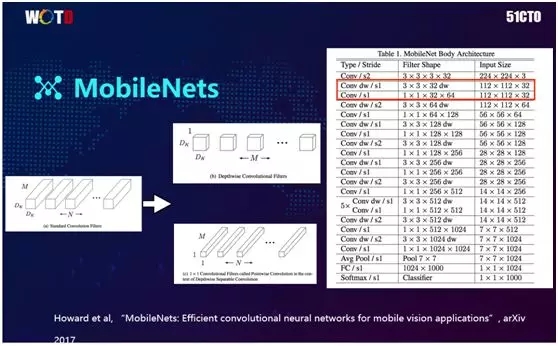
谷歌于 2017 年 3 月提出了一个较小的模型 MobileNets。它主要采取了 Group 的策略,核心思想是:不再与前面的所有层进行操作,只跟对应的上一层通道做卷积。
例如:以前的权重是 3×3×32,再乘以前面的 32 个通道,就是有两个 32 相乘。
通过使用 Group,我们只需一个 32,因为后面乘的是 1(跟每一个通道相乘),此处比原来减少了 32 倍。
如果后面的通道数越多,如 512,则会比原来相应地减少 512 个,所以这是非常可观的。
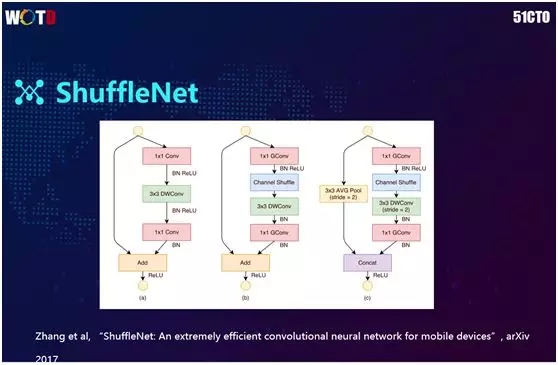
2017 年 7 月,Face++ 团队提出了更进一步的做法 ShuffleNet。考虑到在通道大的时候,1×1 的卷积到 1024 或者 2048 的计算量也会很大,因此它将 1×1 的卷积也进行了 Group 操作。
在分组之后,我们单独地进行 1×1 的卷积,并且随即将顺序打乱。这样便可以把通道与通道之间的关系表达进去。
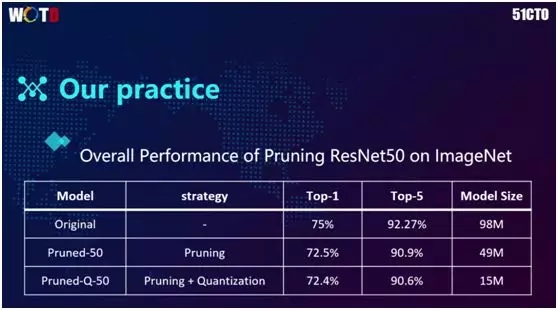
这个是我们在公开数据集 ImageNet 上的数据集实验。我们将原大小为 98M 的模型,通过模型压缩后降到了 49M,而在权重的量化之后,继续减到了 15M。
在整个过程中,Top-1 从 75% 变成 72.4%,该降幅比较少,而业界一般准确率是在 75%~76%。可见这个实验是比较可观和可用的。
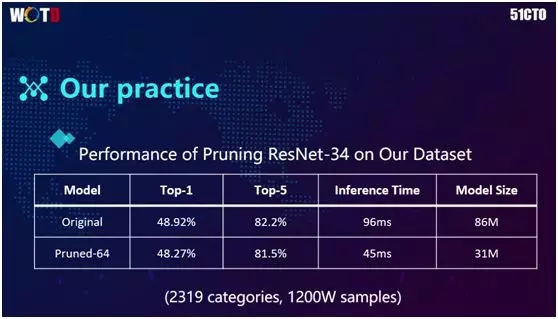
上图的结果源自蘑菇街自己的实际数据。当前我们的数据样本大致是 1200 万,通过“剪枝”之后,Top-1 基本保持在 48%。
而 Top-5 降低了 1 个点,从 82.2% 降至 81.5%,但是模型的大小则从 86M 降到了 31M;同时 Inference Time 为 45 毫秒。这就意味着效率提升了一倍。
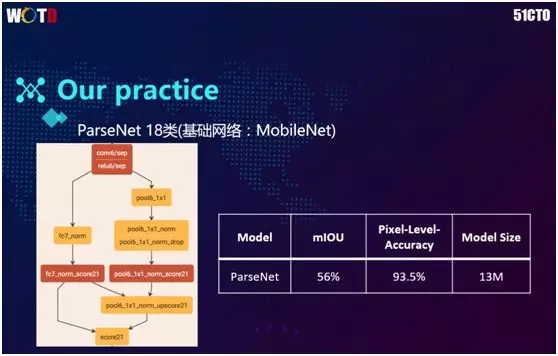
另一个尝试是语意分割网络。蘑菇街基于服装的特点对人体的各个部位进行了“分割”,包括手、脚、鞋子、衣服、裤子等。该语义分割模型的基础网络为 MobileNet,最终模型只有 13M。
移动端优化实践
在将模型做得足够小之后,我们又是如何让它跑在手机之上的呢?
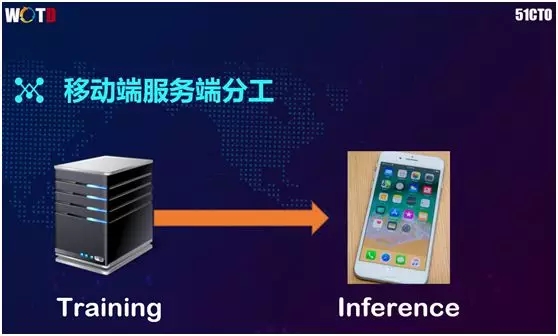
在手机上做深度学习时,由于计算量非常大,我们不应该将训练放在手机上,而是仍然交给 GPU 来实现。而在训练完成之后,我们再将模型部署到手机端。

如今业界常用且好用的深度学习框架包括:
- Facebook 推出的 Caffe2,亚马逊选用的 MXNet。不过我们试用下来发现,它们在手机上的实际性能表现却不尽人意,对于一张图的识别可能需要 8~9 秒。
- NCNN 是腾讯开源的框架,而 MDL 则是百度开源的移动端深度学习框架。
- CoreML 是苹果在 2017 年 WWDC 上发布的在手机上的深度学习框架。
- Tensorflow Lite 是谷歌在 2017 年 I/O 大会上发布的开源产品。
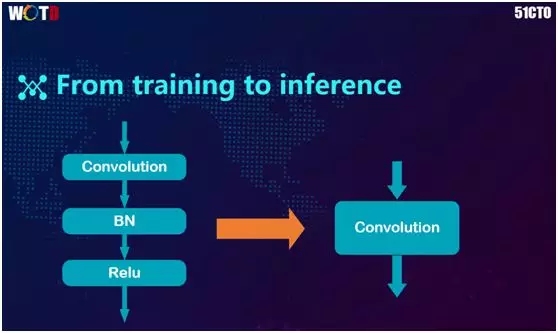
那么对于一个网络,我们是否非要将 Inference 与训练网络做得一样呢?如今业界大部分框架的做法的确如此,例如 NCNN 和 MDL,它们都是直接把训练好的网络转到手机上运行。
但是我们发现在训练的时候,需要做一些梯度计算和反向传播,而在 Inference 时,我们实际上并没有必要做反向传播。
上图中是一个典型 CNN 网络里的单个 Block(块),从 Convolution 到 BN(BachNormalization)再到 Relu。
这三层在存储时对于内存的需求非常大,实际上我们完全可以将它们合为一层,从而减少内存的使用,并加快速度。
在具体实现过程中,我们将 BN 放到 Convolution 里的转变是不需要改动框架代码的。但是如果要把 Relu 放入 Convolution,则需要修改此框架的源代码。
优化卷积计算
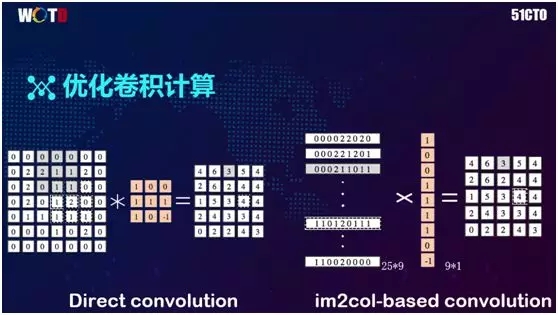
由于深度学习在处理图像时,大部分的计算都涉及到卷积,因此比较直观的做法就是直接进行 3×3 Filter。
因为数据和图像在内存里的存储是连续的,从而导致了读取时经常需要到各处跳转,这造成了指针跨度巨大,极大降低了 cache 命中率。
所以大部分的卷积算法优化都采取将 Filter 乘法转化成传统的矩阵乘法。如上图右侧所示,原来 7x7 矩阵和 3x3 矩阵分别被转化成了 25×9 的矩阵和 9×1 矩阵。
我们通过直接对大型矩阵进行乘法操作,便可得到结果,且该结果跟原来是一模一样的。这也是目前许多针对矩阵运算的加速库所普遍采用的优化方式。
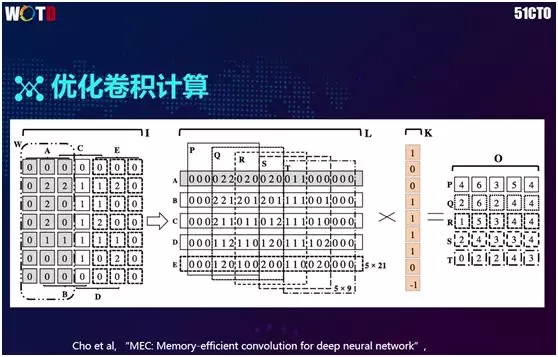
2017 年 MEC 算法被推出,由于原来 7×7 矩阵的转化率 25×9 中存在着冗余和复制,该算法把它变换成为 5×21。就数量级而言,该 5×21 比 25×9 降低约一倍的内存,其性能更为直观。
浮点运算定点化
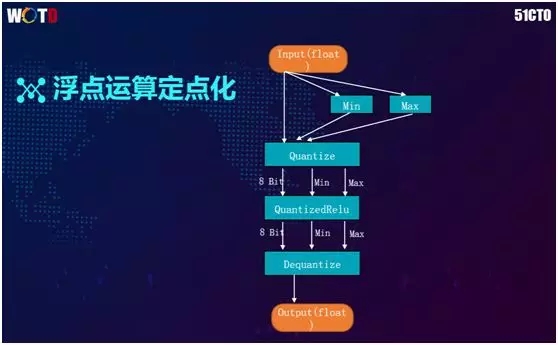
由于深度学习模型的权重和特征图的值是浮点数,而计算机对于浮点的运算能力远不及定点的运算,例如:计算 3+2 和 3.0+2.0 的速度肯定是不一样的,因此我们需要将传过来的浮点数先给转化成定点数。
例如:如果权重的大部分都是 0.1 或 0.2 的话,那么我们通过求最小、最大值的方式将其映射到了 0 到 2 上,而 0 到 2 正好是一个字节,因此一个 8 位就能够予以表达了。
如此,我们在计算 Convolution 矩阵相乘时,完全可以直接使用典型的矩阵来进行计算,其速度会比使用浮点数计算快很多。
当然,在计算完成之后,我们还需将结果转换成浮点数予以输出。

除了上述提到的优化卷积的核心方法,我们还能怎么进化呢?
- 再牛的核心算法,都不如硬件实现来得直接。此处主要是针对苹果产品,苹果在做图像识别时使用的就是自己开发的带有卷积乘法的 GPU 硬件。
我们在二次开发时可以直接调用它提供的基础卷积操作,而不必使用任何前面提到的算法。
- 另外,前面提到的许多框架都是通用的优化算法。但是在实际深度学习中,我们根本不需要那么多具有通用性的卷积。
例如:刚才列出的很多网络,要么是 1×1 的卷积,要么是 3×3 的卷积,基本上不会出现 2×2 的卷积。
因此我们只需要使用 3×3 的卷积优化便可。正如腾讯 NCNN 所采用的特定卷积策略,仅优化 3×3 和 1×1 的卷积。我们同样可以不必考虑其他的矩阵相乘方式,如此便可提高实现速度。

通过深入分析,我们发现:腾讯与百度在安卓上的效果差不多。如前所述,由于腾讯针对 3×3 和 1×1 优化采取的是特定卷积,而百度采取的是通用做法,所以后者更耗内存。
当然两者性能都在 200 毫秒左右,而对于开源的 Tensorflow Lite,由于它将浮点型转为整型进行运算,其性能会比上述两者更快,只需 85 毫秒,基本可以满足实时性的要求。
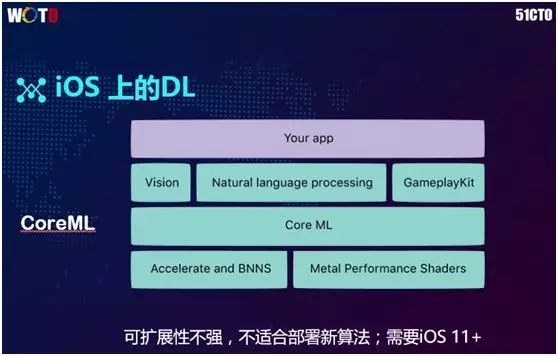
针对深度学习,苹果于 2017 年发布了 CoreML。它在网上被炒得特别火,其框架如上图所示,最下面被分化出了负责加速的一层 BNNS,它是用 C 语言写的机器学习库。
旁边的 Metal Performance Shaders 属于苹果自己的硬件,它封装好了与机器学习相关的底层 API。
二次开发人员可以在 CoreML 的底层基础上,进行适当的应用添加。不过我们并没有采用该 CoreML,原因如下:
- 由于苹果比较封闭,它只能提供现成的框架和既定的模型。而计算机视觉的算法开发领域发展速度非常快,我们经常需要开发出一些新的层(layer)。因此 CoreML 无法满足我们的算法要求。
- CoreML 的库需要调用最新的 iOS 包,而许多苹果手机的 iOS 版本并未升级到 iOS11 以上。

所以在 iOS 上,我们是在 MPSCNN 层实现计算卷积的,好处在于:
- Metal 的机制充分利用了 GPU 资源,而在 iOS 上不会抢占 CPU 资源。
- 运用苹果自己的 Metal 语言去开发新的一层会非常的方便。
同时需要注意如下两点:
- Metal 实现的是 16 位 Float 数的计算,并非 32 位,因此属于半精度。
- 其权重的格式是 NHWC。
有人可能会质疑半精度的计算准确率,然而,由于深度学习有着非常强的泛化能力,就算减少计算精度,受到的影响基本上也并不大,同样可以完成任务。

上图展示的是苹果 MPSCNN 的设计思想。不同于其他常见框架的组织结构:它对权重以 4 的整数倍通道数去进行存储。
例如:有 9 个通道需要用 3 个 Slices 时,那么到了最后一次 Slice,就只需存储一个通道并空闲另外三个通道,以预留空间。因此,理解了这个核心点将有助于我们加快开发的进程。

如上图所示,如果你想用 Metal 来开发新的一层,而且已经有了一定的算法基础,那么上述几行代码就够了。
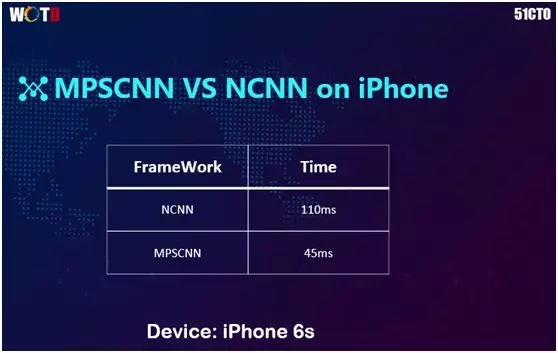
根据上图的 NCNN 与苹果 MPSCNN 对比可知,运用开源框架的 CPU 耗时为 110 毫秒,而苹果要少于一半,只要 45 毫秒。可见苹果的效果确实不错。

就自行搭建深度学习框架而言,我们需要注意如下的策略方面:
- 优化 Inference 网络结构。请牢记 Inference 网络与 Training 的不同之处。如前所述,通过将传统的三层合并为一层,我们能够大幅降低开销。
- GPU 加速。由于苹果使用 Metal 进行封闭存储,因此对于 GPU 的加速在 iOS 上做得比较好。而其他非 iOS 的安卓生态,目前尚无较好的 GPU 加速硬件。
- 指令加速。如今 99% 以上的安卓手机里都是使用的 ARM 芯片,该芯片能够提供一些统一的指令集,以供我们实现底层的加速。
- 鉴于 CPU 普遍为多核的特点,我们也可以采取多线程的方式进行加速。
- 采取内存布局优化,将传统的 NCHW(N:number、C:channel、H:height、W:width)多维方式中的 channel 维度放到最后,变成 NHWC 以提高速度。
- 将浮点运算转到定点化,以提升计算速度。
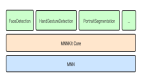
基于 NCNN 的工具包框架
Mogu Deep Learning Toolkit 是蘑菇街于 2016 开发的仅供公司内部使用的深度学习工具包。
由于各层都被做得十分专业极致,其高内聚低耦合的特点在网络设计上显得非常灵活,对于专业人士来说也比较好用。
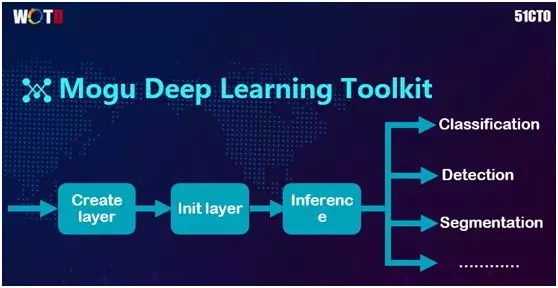
该工具包的设计思想为:在优化掉 Training 网络的基础上,我们在手机上为从网络进来的图片创建一个网络模型→对它进行初始化→通过前端传播进行Inference→针对具体的 Task,对传播的结果进行诸如 Classification、Detection、Segmentation 等操作→获取结果或与其他业务相结合。

上图是利用该工具包开发的一个简单案例,是用 C++ 实现的。这是 MobileNet 的一个 Class,我们将全部各层都放入了 Private 中,它只有一个对外的接口,通过初始化便可拿到其结果。
这里输入的是一张图片,最后 Output 的是该图片的识别结果。
深度学习优化在业务中的尝试
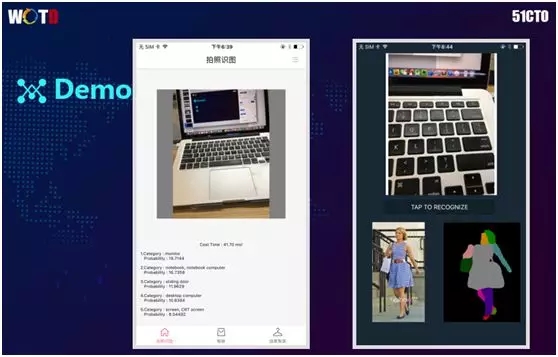
上图是我们做的一些实战:
- 左图是用 ImageNet 识别图片,它给出了排名第一的可能性是显示屏,而排名第二的是笔记本。
- 右图通过语义分割,我们使用 MobileNet 作为特征网络,训练出一个可以分割的网络。
通过对图中人物的分割,我们区分出了头发、衣服、包、鞋子、腿、手等不同部分,以供进一步进行分析。
其消耗时间也相当可观,大概在 40 毫秒左右。
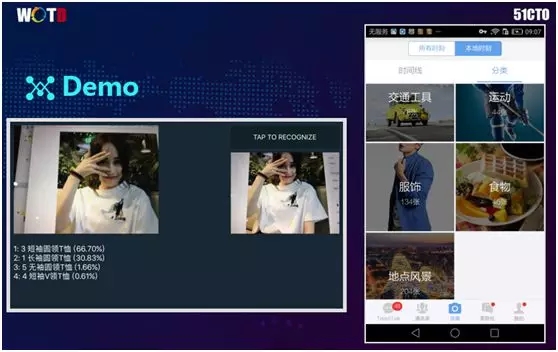
上图左侧展示了我们的另一个训练模型--识别领形。通过图像识别的方法,我们分辨出该T恤是圆领还是 v 领、是长袖还是无袖。根据其下方的判断,它是圆领的概率为 66.7%。
上图右侧展示的是我们公司内部的通讯工具。它被安装在手机上,并在本地运行,能够根据深度学习的结果,执行图片分类。
总结

要想把深度学习做到移动端上,一定要将算法与工程相结合。
黄文波,蘑菇街图像算法工程师,主要从事深度学习相关工作,包括模型加速压缩、GAN、艺术风格转换以及人脸相关应用,尤其对深度学习在移动端的优化有较深入的研究。

【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】