当存储Cache由于丢失时,我们应该如何处理,让数据库重新能够open起来呢?让我们听听,专家分享的这篇案例。
发现问题
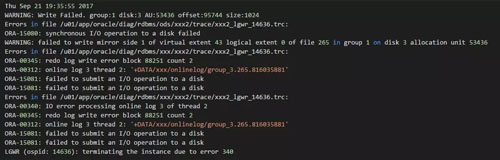
最近某客户的一套核心数据库由于存储问题导致清掉Cache之后无法启动。首先我们来看看数据库在启动的时候报什么错误:
错误并不复杂。可以看到Oracle这里已经无法正常写Redo logfile了。
解决思路
由于这套数据库是非归档,只有逻辑备份,因此即使恢复成功也面临数据丢失的可能性。
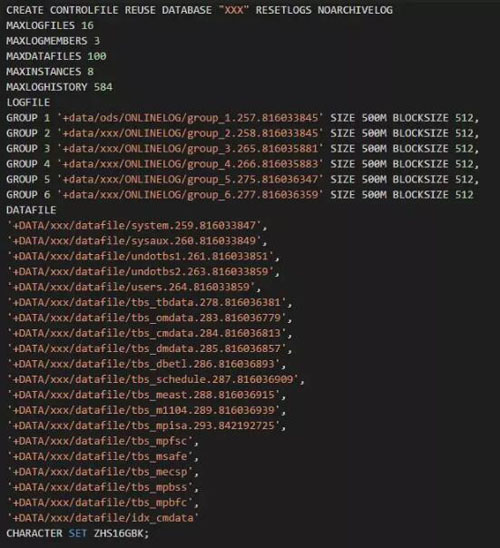
首先我在尝试进行恢复时,发现居然无法mount数据库,在mount过程中实例被直接终止了,感觉非常奇怪。也没有报非常明显的错误。mount过程出错,那么无疑是controlfile存在异常;由于没有controlfile备份,因此这里先手工重建控制文件,如下是脚本:
重建完毕后。其实这里我首先尝试了进行noresetlogs创建,但是发现报错:

很明显,Redo logfile有问题。
看来还是只能Resetlogs方式创建。创建完毕之后,尝试进行了recover database using backup controlfile until cancel恢复操作;然后通过隐含参数强制open发现还是有如下错误:
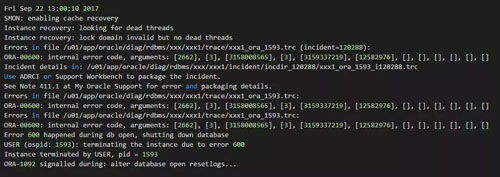
这是非常经典的错误了,由于这是scn的问题,而且数据库版本为11.2.0.3.0,未安装任何psu。因此这里是可以直接推进scn的。
直接通过10015 event 来推进数据库的scn;另外由于是异常关机,那么这里Undo 必然也无法进行正常恢复;因此同时设置 undo_management 参数为manual,并同时设置10015 event:
- alter session set events ‘10015 trace name adjust_scn level 2’;
顺利打开了数据库。打开数据库之后立刻重建数据库Undo和temp,如下:

再次重启数据库之后,发现alert log仍然有一些错误。如下所示:
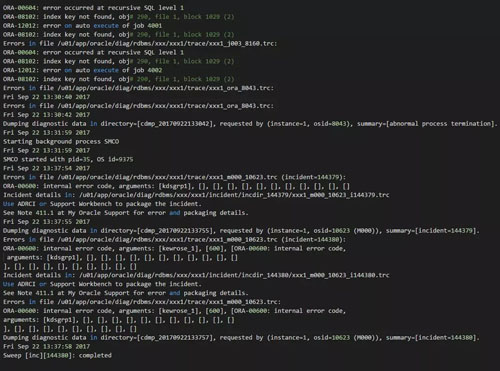
实际上当时在进行恢复时,我手工处理掉了obj# 290。但是进一步检查发现obj$,col_usage$ ,i_obj4# 都存在问题。而且不一致的记录还比较多:
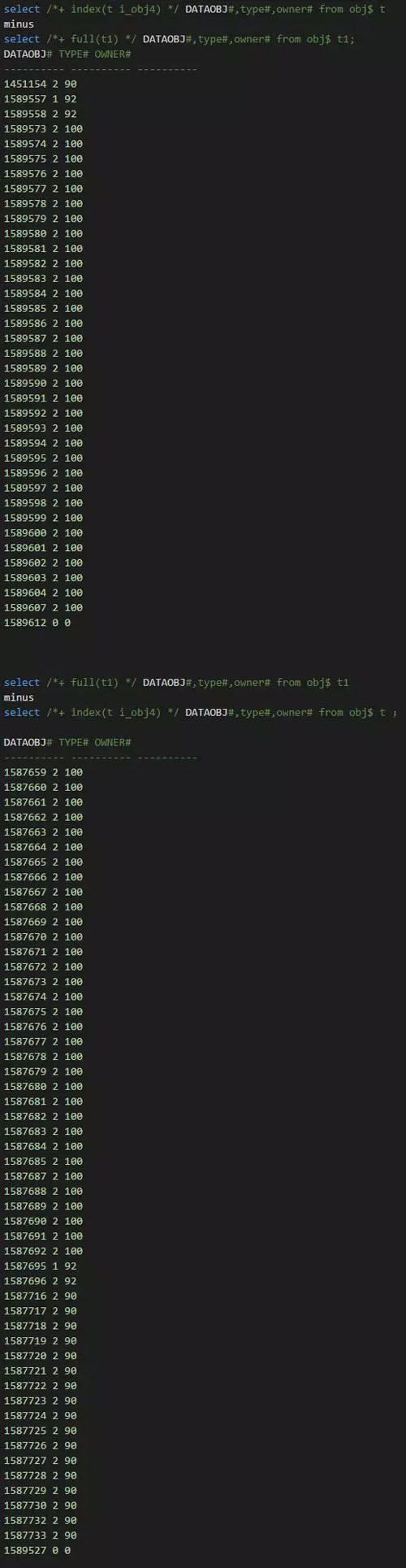
最开始我还尝试通过bbed修复了2个Block;***发现依然难以处理这个ora-08102错误;后续通过上述sql比较发现居然有如此多的记录不一致。修改起来太过麻烦了。
这里其实本来想尝试通过重建obj$,i_obj4$,col_usage$ 来解决的。但是担心有较大的风险,因此这里建议可以进行了数据库重建。由于obj$这里有问题,expdp操作都报错,无法执行任何ddl操作。因此***通过exp拆分脚本来进行重建处理。整个数据库恢复+重建过程将近20小时左右(2tb左右的库).
由于客户存储环境io较差,因此导致整个重建过程比较复杂,比较耗时。我们在开玩笑讲到:如果可能的数据库运行在我们的Zdata环境上,那么数据库重建过程在2小时内即可完成,而且也不会出现类似故障。因此Zdata的io操作上直接落盘或者写到Pcie上,不存在数据丢失的风险。
补充说明
1) 由于数据库很多事务无法正常恢复,导致SMON在不断尝试进行事务恢复时报错,达到一定次数之后会crash实例,进而影响数据库的重建工作。可通过设置_smon_internal_errlimit 参数来避免该问题。
2) 为了加快exp和imp速度,这里我们利用了管道技术,脚本如下: