












本系列:
大家好!从今天开始,我要与大家一起打造一个属于我们自己的分布式爬虫平台,同时也会对涉及到的技术进行详细介绍。大家如果有什么好的想法请多留言,多提意见,一起来完善我们的爬虫平台。在正式介绍平台之前,先用一些篇幅对基础篇做一点补充。模拟滚动
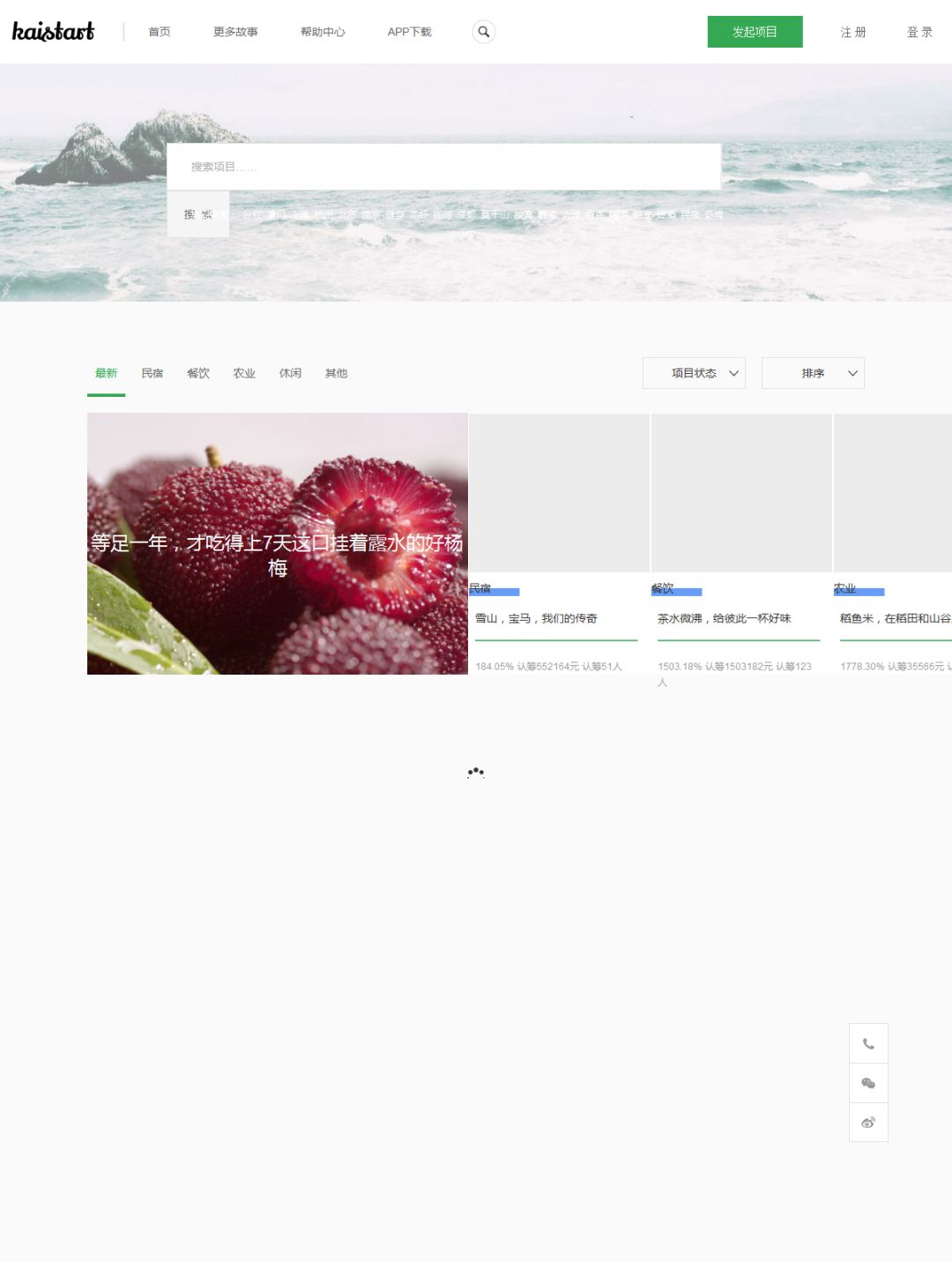
这次的目标是爬一个众筹网站的所有项目,项目列表页如下:https://www.kaistart.com/project/more.html。打开后进行分析,页面显示出10个项目:
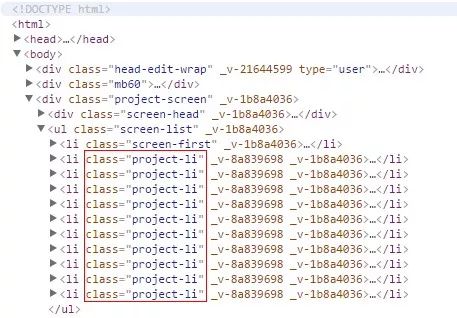
如果想看到更多项目,并不能像网易云音乐那样点“下一页”翻页,而是需要向下拉滚动条或者向下滚动鼠标滚轮来触发异步请求。爬虫该如何应对这种情况呢?我们可以使用selenium的api执行js代码将屏幕内容滚动到指定位置。

下面这段代码会一直向下滚动项目页,一直到滚不动为止:
- # 一直滚动到***部
- js1 = 'return document.body.scrollHeight'
- js2 = 'window.scrollTo(0, document.body.scrollHeight)'
- old_scroll_height = 0
- while browser.execute_script(js1) >= old_scroll_height:
- old_scroll_height = browser.execute_script(js1)
- browser.execute_script(js2)
- time.sleep(1)
scrollTo() 方法可把内容滚动到指定的坐标:
| 参数 | 描述 |
| xpos | 必需。要在窗口文档显示区左上角显示的文档的 x 坐标。 |
| ypos | 必需。要在窗口文档显示区左上角显示的文档的 y 坐标。 |
这里用到了scrollHeight,它和ClientHeight还有OffsetHeight有什么区别呢?

- browser = webdriver.PhantomJs()
- url = 'https://www.kaistart.com/project/more.html'
- try:
- browser.get(url)
- wait = ui.WebDriverWait(browser, 20)
- wait.until(lambda dr: dr.find_element_by_class_name('project-detail').is_displayed())
- # 一直滚动到***部
- js1 = 'return document.body.scrollHeight'
- js2 = 'window.scrollTo(0, document.body.scrollHeight)'
- old_scroll_height = 0
- while browser.execute_script(js1) >= old_scroll_height:
- old_scroll_height = browser.execute_script(js1)
- browser.execute_script(js2)
- time.sleep(1)
- sel = Selector(text=browser.page_source)
- proj_list = sel.xpath('//li[@class="project-li"]')

- browser.save_screenshot(debug.png')
这样就会把图片保存在项目目录,打开看看:
- browser = webdriver.Chrome()
再次运行程序,不出所料,Chrome浏览器弹出来,不仅能够正确显示页面,还一直在滚动:
项目全都刷出来了,想爬什么就爬吧!什么?你问我在Linux服务器上怎么爬?纯命令行的那种吗?

- from selenium import webdriver
- from pyvirtualdisplay import Display
- display = Display(visible=0, size=(800, 600))
- display.start()
- driver = webdriver.Chrome()
- driver.get("http://www.baidu.com")
- print (driver.page_source.encode('utf-8'))
- driver.quit()
- display.stop()



















