














大数据文摘作品
编译:张南星、卫青、钱天培
究竟什么样的AI人才能被微软这样的巨头聘用呢?
是不是要码力超群,上来就能徒手写个AlphaGo呢?还是要眼光毒辣,当场就能构想出未来20年AI发展前景呢?
当然不是!
今天,文摘君就淘来了几道微软AI 面试题,同时给出了最基本的解答。(注意是最基本解答哦,欢迎在文末留言给出你认为更好的答案。)
神秘的微软AI面试题,其实非常平易近人。一起来答答看!
合并k个数列(比如k=2)数列并进行排序
数列并进行排序")
代码如上。最简单的方法当然就是冒泡排序法啦。虽然不是最有效的,但却容易描述和实现。
L1/L2正则度量有什么区别?

L1范数损失函数也叫做最小一乘法(LAD)以及最小绝对误差(LAE)。它主要在于最小化目标值(y_i)同预测值(f(x_i))之间的绝对差值之和。
公式一
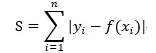
L2范数损失函数也叫做最小平方误差(LSE)。它主要在于最小化目标值(Yi)以及预测值[f(xi)]之间差值平方之和。
公式二

对于较大的误差误差,L2比L1给出的惩罚更大。此外,加入L2正则后,模型系数会向0聚拢,但不会出现完全为0的情况,而L1损失函数则能使部分系数完全为0。
如何寻找百分位数?

就拿上面这道题目为例吧:过去12小时内共有1000人来过这个购物中心,请估测,截止至何时,购物中心刚好达到30%的总客流量?

我们可以通过多项式线性回归(polynomial regression)或者平滑样条(spline smoothing)等技巧作出下图。

即为30%的客流量对应3000人
从Y值为3000的点画一条水平线,当与曲线相交时,画一条垂直线在横轴上找到对应的时间值就可以啦。
怎么区分好的可视化与坏的可视化?
针对这个问题,我们会有很多不同的答案。比如,一个不能很好地处理异常值(outliers)的可视化,就不是一个好的可视化。

比如说我们有一个数组,在一系列小数字中有一个很大的数据([1,2,3,4,7777,5,6,9,2,3]),当我们可视化这个数组的时候,会产生如下的图:

右图→原始图片;中间图→规范化值;左图→标准化值
怎样才能更好地可视化这组数据呢?正如上图所示,即使我们对分析值进行了标准化或者规范化,产生的折线图依然不能很好地表示这组数组。究竟要怎么做呢?欢迎留言发表看法。
怎样更快地计算出逆矩阵?
比如,可以考虑Gauss-Jordan法。
如果是一个2x2的矩阵就很简单了。
逆矩阵是:
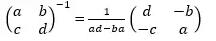
ad-bc≠0
只需要交换a和b,取b和c的负值,然后除以方阵ad-bc。

定义方差
方差是每个数据点与整个数据集平均值之间差值的平方和。换而言之,就是数据的变化性。下面这张图就很好地解释了什么是方差。

首先我们计算出每只狗和平均身高的差值;为了计算方差,将每个差值平方后加总,再求平均值。
最后,献上本文出现的所有代码:
https://colab.research.google.com/drive/1DYimC5CEKeXdT15tbptifYL2v5MPkyHj
相关报道:
https://towardsdatascience.com/my-take-on-microsoft-ai-interview-questions-with-interactive-code-part-1-c271388af633
【本文是51CTO专栏机构大数据文摘的原创译文,微信公众号“大数据文摘( id: BigDataDigest)”】





















