整体架构
BlockManager 是 spark 中至关重要的一个组件, 在 spark的的运行过程中到处都有 BlockManager 的身影, 只有搞清楚 BlockManager 的原理和机制,你才能更加深入的理解 spark。 今天我们来揭开 BlockaManager 的底层原理和设计思路,
BlockManager 是一个嵌入在 spark 中的 key-value型分布式存储系统,是为 spark 量身打造的,
BlockManager 在一个 spark 应用中作为一个本地缓存运行在所有的节点上, 包括所有 driver 和 executor上。 BlockManager 对本地和远程提供一致的 get 和set 数据块接口, BlockManager 本身使用不同的存储方式来存储这些数据, 包括 memory, disk, off-heap。

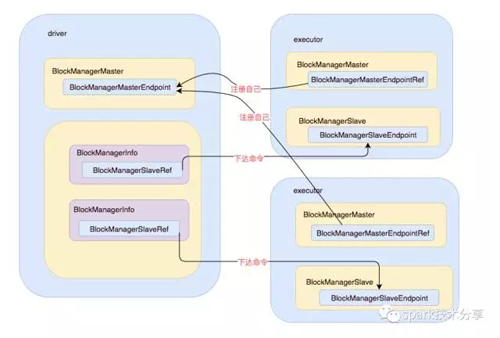
上面是一个整体的架构图, BlockManagerMaster拥有BlockManagerMasterEndpoint 的actor和所有BlockManagerSlaveEndpoint的ref, 可以通过这些引用对 slave 下达命令
executor 节点上的BlockManagerMaster 则拥有BlockManagerMasterEndpoint的ref和自身BlockManagerSlaveEndpoint的actor。可以通过 Master的引用注册自己。
在master 和 slave 可以正常的通信之后, 就可以根据设计的交互协议进行交互, 整个分布式缓存系统也就运转起来了,
初始化
我们知道, sparkEnv 启动的时候会启动各个组件, BlockManager 也不例外, 也是这个时候启动的,
启动的时候会根据自己是在 driver 还是 executor 上进行不同的启动过程,
- def registerOrLookupEndpoint(
- name: String, endpointCreator: => RpcEndpoint):
- RpcEndpointRef = {
- if (isDriver) {
- logInfo("Registering " + name)
- rpcEnv.setupEndpoint(name, endpointCreator)
- } else {
- RpcUtils.makeDriverRef(name, conf, rpcEnv)
- }
- }

上图是 sparkEnv 在 master上启动的时候, 构造了一个 BlockManagerMasterEndpoint, 然后把这个Endpoint 注册在 rpcEnv中, 同时也会启动自己的 BlockManager
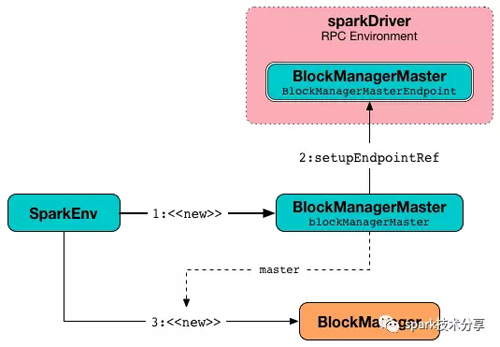
上图是 sparkEnv 在executor上启动的时候, 通过 setupEndpointRef 方法获取到了 BlockManagerMaster的引用 BlockManagerMasterRef, 同时也会启动自己的 BlockManager,
在 BlockManager 初始化自己的时候, 会向 BlockManagerMasterEndpoint 注册自己, BlockManagerMasterEndpoint 发送 registerBlockManager消息, BlockManagerMasterEndpoint 接受到消息, 把 BlockManagerSlaveEndpoint 的引用 保存在自己的 blockManagerInfo 数据结构中以待后用。
分布式协议
下面的一个表格是 master 和 slave 接受到各种类型的消息, 以及接受到消息后,做的处理。
- BlockManagerMasterEndpoint 接受的消息
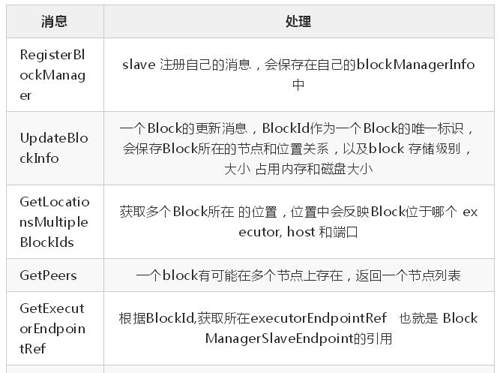
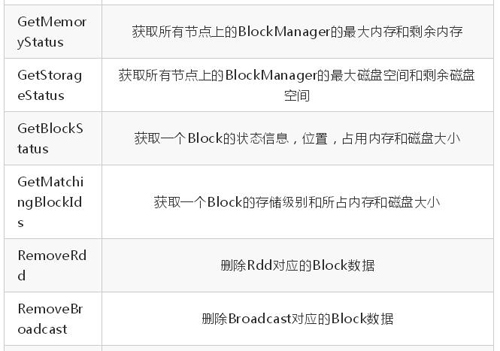
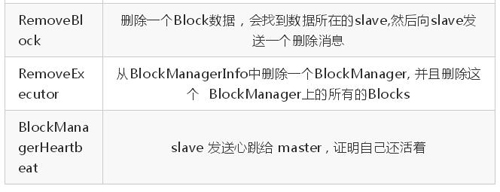
- BlockManagerSlaveEndpoint 接受的消息

根据以上的协议, 相信我们可以很清楚的猜测整个交互的流程, 一般过程应该是这样的, slave的 BlockManager 在自己接的上存储一个 Block, 然后把这个 BlockId 汇报到master的BlockManager , 经过 cache, shuffle 或者 Broadcast后,别的节点需要上一步的Block的时候, 会到 master 获取数据所在位置, 然后去相应节点上去 fetch。
存储层
在RDD层面上我们了解到RDD是由不同的partition组成的,我们所进行的transformation和action是在partition上面进行的;而在storage模块内部,RDD又被视为由不同的block组成,对于RDD的存取是以block为单位进行的,本质上partition和block是等价的,只是看待的角度不同。在Spark storage模块中中存取数据的最小单位是block,所有的操作都是以block为单位进行的。
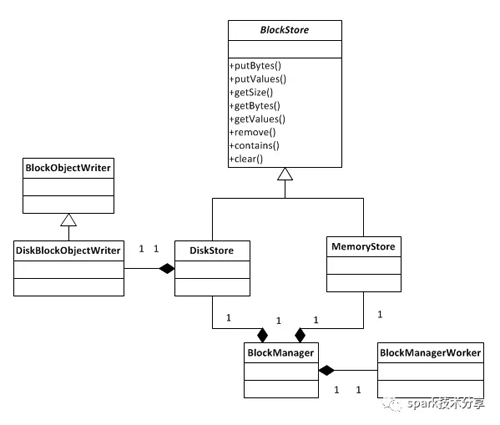
BlockManager对象被创建的时候会创建出MemoryStore和DiskStore对象用以存取block,如果内存中拥有足够的内存, 就 使用 MemoryStore存储, 如果 不够, 就 spill 到 磁盘中, 通过 DiskStore进行存储。
- DiskStore 有一个DiskBlockManager,DiskBlockManager 主要用来创建并持有逻辑 blocks 与磁盘上的 blocks之间的映射,一个逻辑 block 通过 BlockId 映射到一个磁盘上的文件。 在 DiskStore 中会调用 diskManager.getFile 方法, 如果子文件夹不存在,会进行创建, 文件夹的命名方式为(spark-local-yyyyMMddHHmmss-xxxx, xxxx是一个随机数), 所有的block都会存储在所创建的folder里面。
- MemoryStore 相对于DiskStore需要根据block id hash计算出文件路径并将block存放到对应的文件里面,MemoryStore管理block就显得非常简单:MemoryStore内部维护了一个hash map来管理所有的block,以block id为key将block存放到hash map中。而从MemoryStore中取得block则非常简单,只需从hash map中取出block id对应的value即可。
BlockManager 的 PUT 和GET接口
BlockManager 提供了 Put 接口和 Get 接口, 这两个 api 屏蔽了底层的细节, 我们来看下底层是如何实现的
- GET操作 如果 local 中存在就直接返回, 从本地获取一个Block, 会先判断如果是 useMemory, 直接从内存中取出, 如果是 useDisk, 会从磁盘中取出返回, 然后根据useMemory判断是否在内存中缓存一下,方便下次获取, 如果local 不存在, 从其他节点上获取, 当然元信息是存在 drive上的,要根据我们上文中提到的 GETlocation 协议获取 Block 所在节点位置, 然后到其他节点上获取。
- PUT操作 操作之前会加锁来避免多线程的问题, 存储的时候会根据 存储级别, 调用对应的是 memoryStore 还是 diskStore, 然后在具体存储器上面调用 存储接口。 如果有 replication 需求, 会把数据备份到其他的机器上面。
blockManager 和 blockTransferService 关系
spark 历史上使用过两套网络框架, 最开始的时候, rpc 调用使用的是 akka, 大文件传输使用的是 netty, 后面统一全部使用 netty, 这里的大文件传输其实走的是 netty, 在启动 blockManager的时候会启动一个 blockTransferService 服务, 这个服务就是用来传输大文件用的, 对应的具体类是 NettyBlockTransferService, 这个实例中也会有 BlocakManager的引用, 会启动一个 NettyBlockRpcServer的 netty Handler, 也拥有 BlocakManager 的引用, 用来提供服务, BlocakManager 根据 BlockId 获取一个 Block 然后包装为一个 ManagedBuffer 对象,
当我们需要从远端获取一个 Block的时候,就需要 blockTransferService 传输大的字节数组,
首先需要从 driver上获取到 Block的真正存储位置, 然后调用 blockTransferService 的 fetchBlocks方法, 去其他真正存储节点上去fetch数据, 会从 client 资源池中获取一个client, 如果是一对一的进行fetch, 使用的是 OneForOneBlockFetcher, 这个Fetcher 是以 Chunks 为单位分别单独fetch, 每个 Chunks 也就对应一个Block的数据, 根据配置,会进行重试直到***重试次数,发送 OpenBlocks消息, 里面会包装对应的是哪个 BlockId, 其他节点服务端会根据 BlockId 从 blockManager中拿到数据, 然后用来传输, 使用的是 netty 的流式传输方式, 同时也会有回调函数,
如果是备份的时候同步上传一个 Block, 其他节点服务端会根据,uploadBlock消息中包含的BlockId, 在本地的BlockManager 中冗余存储一份,
ChunkFetch也有一个类似Stream的概念,ChunkFetch的对象是“一个内存中的Iterator[ManagedBuffer]”,即一组Buffer,每一个Buffer对应一个chunkIndex,整个Iterator[ManagedBuffer]由一个StreamID标识。Client每次的ChunkFetch请求是由(streamId,chunkIndex)组成的唯一的StreamChunkId,Server端根据StreamChunkId获取为一个Buffer并返回给Client; 不管是Stream还是ChunkFetch,在Server的内存中都需要管理一组由StreamID与资源之间映射,即StreamManager类,它提供了getChunk和openStream两个接口来分别响应ChunkFetch与Stream两种操作,并且针对Server的ChunkFetch提供一个registerStream接口来注册一组Buffer,比如可以将BlockManager中一组BlockID对应的Iterator[ManagedBuffer]注册到StreamManager,从而支持远程Block Fetch操作。
对于ExternalShuffleService(一种单独shuffle服务进程,对其他计算节点提供本节点上面的所有shuffle map输出),它为远程Executor提供了一种OpenBlocks的RPC接口,即根据请求的appid,executorid,blockid(appid+executor对应本地一组目录,blockid拆封出)从本地磁盘中加载一组FileSegmentManagedBuffer到内存,并返回加载后的streamId返回给客户端,从而支持后续的ChunkFetch的操作。
Partition 与 Block 的关系
我们都知道, RDD 的运算是基于 partition, 每个 task 代表一个 分区上一个 stage 内的运算闭包, task 被分别调度到 多个 executor上去运行, 那么是在哪里变成了 Block 呢, 我们以 spark 2.11 源码为准, 看看这个转变过程,
一个 RDD 调度到 executor 上会运行调用 getOrCompute方法,
- SparkEnv.get.blockManager.getOrElseUpdate(blockId, storageLevel, elementClassTag, () => {
- readCachedBlock = false
- computeOrReadCheckpoint(partition, context)
- })
如果 Block 在 BlockManager 中存在, 就会从 BlockManager 中获取,如果不存在, 就进行计算这个Block, 然后在 BlockManager 中进行存储持久化, 方便下次使用,
当然获取的时候是先从本地的 BlockManager 中获取, 如果本地没有, 然后再 从 remote 获取, 先从 driver 上获取到元数据 Block的位置, 然后去到真正的节点上fetch
如果没有, 就进行计算, 然后根据存储级别,存储到计算节点本地的BlockManager 的内存或磁盘中,
这样RDD的transformation、action就和block数据建立了联系,虽然抽象上我们的操作是在partition层面上进行的,但是partition最终还是被映射成为block,因此实际上我们的所有操作都是对block的处理和存取。
blockManager 在 spark 中扮演的角色
blockManager 是非常非常重要的一个 spark 组件, 我们随便举几个例子, 你就知道 BlockManager 多重要了 ,
- spark shuffle 的过程总用到了 BlockManager 作为数据的中转站
- spark broadcast 调度 task 到多个 executor 的时候, broadCast 底层使用的数据存储层
- spark streaming 一个 ReceiverInputDStream 接受到的数据也是先放在 BlockManager 中, 然后封装为一个 BlockRdd 进行下一步运算的
- 如果我们 对一个 rdd 进行了cache, cacheManager 也是把数据放在了 blockmanager 中, 截断了计算链依赖, 后续task 运行的时候可以直接从 cacheManager 中获取到 cacherdd ,不用再从头计算。
spark cache 与 spark broadcast task
我随便举两个例子, 看看具体 spark cache 和 spark broadcast 调度 task 的时候怎么用的 blockManager的
spark cache
rdd 计算的时候, 首先根据RDD id和partition index构造出block id (rdd_xx_xx), 接着从BlockManager中取出相应的block, 如果该block存在,表示此RDD在之前已经被计算过和存储在BlockManager中,因此取出即可,无需再重新计算。 如果 block 不存在我们可以 计算出来, 然后吧 block 通过 doPutIterator 函数存储在 节点上的 BlockManager上面, 汇报block信息到 driver, 下次如果使用同一个 rdd, 就可以直接从分布式存储中 直接取出相应的 block
下面看一下源码
- final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
- if (storageLevel != StorageLevel.NONE) {
- getOrCompute(split, context)
- } else {
- computeOrReadCheckpoint(split, context)
- }
- }
如果存储级别不是 NONE类型就会调用 getOrCompute 这个我们已经看过了, 里面实际调用 SparkEnv.get.blockManager.getOrElseUpdate 方法, 如果 Block 在 BlockManager 中存在, 就会从 BlockManager 中获取,如果不存在, 就进行计算这个Block, 然后在 BlockManager 中进行存储持久化, 方便下次使用,
在 BlockManager 进行存储后, 会调用下面的代码把 汇报block信息到 driver,
- private def tryToReportBlockStatus(
- blockId: BlockId,
- status: BlockStatus,
- droppedMemorySize: Long = 0L): Boolean = {
- val storageLevel = status.storageLevel
- val inMemSize = Math.max(status.memSize, droppedMemorySize)
- val onDiskSize = status.diskSize
- master.updateBlockInfo(blockManagerId, blockId, storageLevel, inMemSize, onDiskSize)
- }
实际上上想 masterEndpoint 的引用发送一条 UpdateBlockInfo消息, master 会把这个 blockId 对应的 location 放在 driver 上,
同样的如果一个 Block已经计算过了,会到 driver 上获取到 location 信息
- private def getLocations(blockId: BlockId): Seq[BlockManagerId] = {
- val locs = Random.shuffle(master.getLocations(blockId))
- val (preferredLocs, otherLocs) = locs.partition { loc => blockManagerId.host == loc.host }
- preferredLocs ++ otherLocs
- }
spark broadcast task
这个调度 task 到多个 task 上面过程代码太多,我就不贴了, 直接说一下流程,
- DAGScheduler 在 submitMissingTasks 方法提交 task的时候, 会把 task 包装为一个 Broadcast 类型, 里面使用 TorrentBroadcastFactory 创建一个 TorrentBroadcast 的类型, 使用的是p2p的协议, 会减轻 master 的压力, 这个里面会 调用 writeBlocks 里面把taskBinary 通过 blockManager.putSingle 放在 BlockManager 缓存中
- ShuffleMapTask 或者 ResultTask,然后调用 runTask 方法, 里面实际上会调用 Broadcast 的value 方法, 里面最终调用了 BlockManager 的 getLocalBytes 或者 getRemoteBytes 方法
blockManager 在 spark streaming 中的应用
- ReceiverTracker 在启动的时候,会运行一个 job, 这个job 就是到 各个executor上去启动 ReceiverSupervisorImpl, 然后启动各个具体的数据接收器, 如果是SocketInputDStream, 就会启动一个 SocketReceiver,
- Receiver 接收到数据后, 先在 BlockGenerator 中缓存, 等到达一定的大小后, 调用 BlockManagerBasedBlockHandler 的 storeBlock方法持久化到 BlockManager 中, 然后把数据信息汇报到 ReceiverTracker上, 最终 汇总到 ReceivedBlockTracker 中的 timeToAllocatedBlocks中,
- ReceiverInputDStream compute的时候, receivedBlockTracker 会根据时间获取到 BlockManager 中的元信息,里面最终对应的还是 BlockManager 的存储位置, 最终获取到数据进行计算,
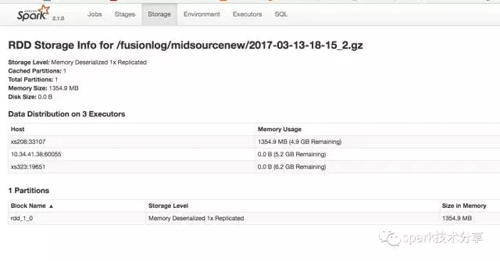
测试 blockManager
我们做一个简单的测试,两端代码的区别就是 一个 进行了cache ,一个没有进行cache。
- val file = sc.textFile("/fusionlog/midsourcenew/2017-03-13-18-15_2.gz")
- file.count()
- file.count()
我们从日志可以观察出来, ***段代码, 两个 job 中都从 hdfs 中读取文件, 读取了两次,
- val file = sc.textFile("/fusionlog/midsourcenew/2017-03-13-18-15_2.gz").cache()
- file.count()
- file.count()
有以下日志
- MemoryStore: Block rdd_1_0 stored as values in memory (estimated size 1354.9 MB, free 4.9 GB)
- BlockManager: Found block rdd_1_0 locally
我们发现在***次读取文件后, 把文件 cache 在了 blockManager 中, 下一个 job 运行的时候, 在本地 BlockManager 直接发现获取到了 block , 没有读取 hdfs 文件 ,
在 spark ui 中也发现了 cache的 Block, 全部是在内存中缓存的,