前言
MySQL是一种关系数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型网站的开发都选择 MySQL 作为网站数据库。
由于其社区版的性能卓越,搭配 PHP 和 Apache 可组成良好的开发环境。
常用技巧
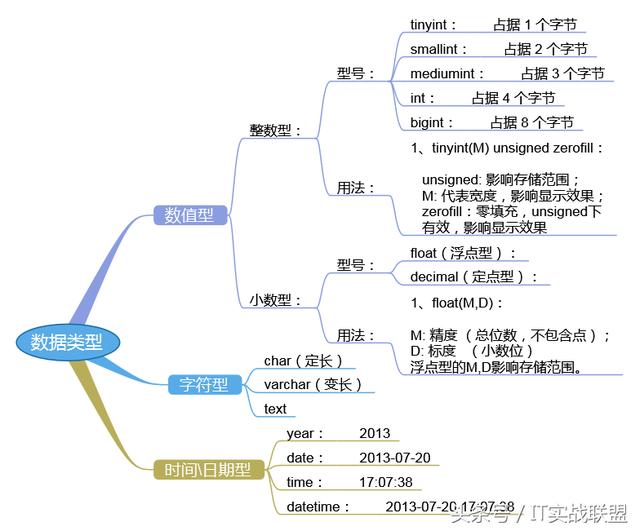
优化的数据类型
优先确认数据类型
在为列选择数据类型时,***步需要确定合适的大类型:数字,字符串,时间等。下一步是选择具体类型。很多MySQL的数据类型可以存储相同类型的数据,只是存储的长度和范围不一样,允许的精度不一样,或者需要的物理空间(磁盘和内存空间)不同。相同大类型的不同子类型数据有时也有一些特殊的行为和属性。
更小的通常更好
一般情况下,应该尽量使用可以正确存储数据的最小数据类型。更小的数据类型通常更快,因为它们占用更少的磁盘,内存和CPU缓存,并且处理时需要的CPU周期也更少。但是要确保没有低估需要存储的值得范围。
简单就好
简单数据类型的操作通常需要更少的CPU周期。例如,整型比字符操作代价更低,因为字符集和校对规则(排序规则)使字符比整型比较更复杂。
尽量避免使用NULL
很多表都包含可为NULL(空值)的列,即使应用程序并不需要保存NULL也是如此,这是因为可为NULL是列的默认属性。通常情况下***指定列为NOT NULL,除非真的需要存储NULL值。如果查询中包含可为NULL的列,对MySQL来说更难优化,因为可为NULL的列使得索引,索引统计和值比较都更复杂。可为NULL的列会使用更多的存储空间,在MySQL里也需要特殊处理,当可为NULL的列被索引时,每个索引记录需要一个额外的字节。如果计划在列上建索引,就应该避免设计成可为NULL的列。
备注:例如:DATETIME和TIMESTAMP列都可以存储相同类型的数据:时间和日期,精确到秒。然而TIMESTAMP只使用DATETIME一半的存储空间,并且会根据时区变化,具有特殊的自动更新能力。另一方面,TIMESTAMP允许的时间范围要小很多,有时候它的特殊能力会成为障碍。
遵循数据库设计的三大范式
***范式
确保每列的原子性(强调的是列的原子性,即列不能够再分成其他几列). 如果每列(或者每个属性)都是不可再分的最小数据单元(也称为最小的原子单元),则满足***范式. 例如:顾客表(姓名、编号、地址、……)其中"地址"列还可以细分为国家、省、市、区等。
第二范式
在***范式的基础上更进一层,目标是确保表中的每列都和主键相关(一是表必须有一个主键;二是没有包含在主键中的列必须完全依赖于主键,而不能只依赖于主键的部分) 如果一个关系满足***范式,并且除了主键以外的其它列,都依赖于该主键,则满足第二范式. 例如:订单表(订单编号、产品编号、定购日期、价格、……),"订单编号"为主键,"产品编号"和主键列没有直接的关系,即"产品编号"列不依赖于主键列,应删除该列。
第三范式
在第二范式的基础上更进一层,目标是确保每列都和主键列直接相关,而不是间接相关(另外非主键列必须直接依赖于主键,不能存在传递依赖). 如果一个关系满足第二范式,并且除了主键以外的其它列都不依赖于主键列,则满足第三范式. 为了理解第三范式,需要根据Armstrong公里之一定义传递依赖。假设A、B和C是关系R的三个属性,如果A-〉B且B-〉C,则从这些函数依赖中,可以得出A-〉C,如上所述,依赖A-〉C是传递依赖。 例如:订单表(订单编号,定购日期,用户编号,用户姓名,……),初看该表没有问题,满足第二范式,每列都和主键列"订单编号"相关,再细看你会发现"用户姓名"和"用户编号"相关,"用户编号"和"订单编号"又相关,***经过传递依赖,"用户姓名"也和"订单编号"相关。为了满足第三范式,应去掉"用户姓名"列,放入用户表中。
总结
范式优点:
(1) 范式化的更新操作通常比反范式化要快(2)当数据较好地范式化时,就只有很少或者没有重复数据,所以只需要修改更少的数据(3)范式化的表通常更小,占用更小的内存,所以处理速度更快(4)很少有多余的数据,意味着检索列表时更少需要distinct和group by语句时间
范式缺点:
符合范式的schema设计,查询时通常需要关联查询
schema设计简单原则
- 尽量避免过度设计,例如会导***其复杂查询的schema设计,或者有很多列的表设计;
- 使用小而简单的合适数据类型,除非真是数据模型中有确切的需要,否则应该尽可能地避免使用NULL值
尽量使用相同的数据类型存储相似或相关的值,尤其是要在关联条件中使用的列;
- 注意可变长字符串,其在临时表或者排序时可能悲观的按***长度分配内存
- 尽量使用整型标识列
- 避免使用mysql已经遗弃的特性,例如指定浮点数的精度(可用decimal代替),或者整数的显示宽度
小心使用ENUM和SET,尽量避免使用;避免使用BIT;
创建高性能索引
高性能的索引策略
独立的列 我们通常会看到一些查询不当地使用索引,或者使得MySQL无法使用已有的索引。如果查询中的列不是独立的,则MySQL就不会使用索引。“独立的列”是指索引列不能是表达式的一部分,也不能是函数的参数。
前缀索引和索引的选择性 有时候需要索引很长的字符列,这会让索引变得大且慢。一个策略是前面提到过的模拟哈希索引。通常可以索引开始的部分字符,这样可以大大节约索引空间,从而提高索引效率,但是也会降低索引的选择性。(索引选择性是指不重复的索引值和数据表的记录总数的比值)索引的选择性越高则查询效率越高。
多列索引 一个常见的错误是:为每个列创建独立的索引,或者按照错误的顺序创建索引。但实际上,在多个列上建立独立的单列索引大部分情况下并不能提高MySQL的查询性能。5.0和之后的版本引入“索引合并”的策略,一定程度上缓解了这个问题。(但没有彻底解决)
索引合并策略有时候是一种优化的结果,但实际上更多时候则说明了表上的索引很糟糕
当出现服务器对多个索引做相交操作的时候,意味着需要一个包含所有相关列的多列索引而不是多个独立的单列索引
当服务器需要对多个索引做联合操作时,通常需要耗费大量的CPU和内存资源在算法上的缓存、排序和合并。优化其不会把这些计算到“查询成本”中,优化器只关心随机页面的读取。这会使得查询的成本被“低估”,导致该执行计划还不如直接走全表扫描。选择合适的索引列顺序。 正确的顺序依赖于使用该索引的查询,并且同时需要考虑如何更好地满足排序和分组的需要。 在一个多列B-TREE中,索引列的顺序意味着索引首先要按照最左列进行排序,其次是第二列,以此类推。
对于如何建立索引列的顺序有一个经验法则:将选择性***的列放到索引最前面。
索引的优点
a. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。b. 可以大大加快数据的检索速度,这也是创建索引的最主要的原因。c. 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。d. 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。e. 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
索引的缺点
a. 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。b. 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚集索引那么需要的空间就会更大。c. 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
备注:因为索引非常占内存,所以索引也需要谨慎添加,那些字段需要索引。
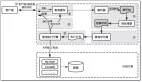
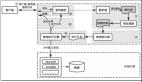
mysql查询生命周期
- 客户端发送一条查询给服务器 ;
- 服务器先查询缓存,如果***了缓存,直接返回结果;否则,进入下一步;
- 服务器进行sql解析、预处理,再由优化器生成对应的执行计划;
mysql根据优化器生成的执行计划,再调用存储引擎API来执行查询;
将查询结果返回给客户端;
SHOW FULL PROCESSLIST可查看当前状态;sleep:线程正在等待客户端发送新的请求;Query:线程正在执行查询或者正在将结果发送给客户端;Locked:该线程正在等待表锁;Analyzing and statistics:线程正在收集存储引擎的统计信息,并生产查询的执行计划;Coping to tmp table:线程正在执行查询,并将其结果复制到临时表中;Sorting result:线程正在对结果集进行排序;Sending data:线程可能在多种状态之间传送数据,或者正在生成结果集,或者正在向客户端发送数据;
查询性能优化
1、慢查询基础:优化数据访问
低效查询分析方法:
a. 确认应用程序是否在检索大量超过需要的数据。通常意味着访问了太多的行,也有可能访问太多的列。b. 确认mysql服务器层是否在分析大量超过需要的数据行。
低效查询典型案列:
a. 查询不需要的记录b. 多表关联时返回全部列c. 总是取出全部列d. 重复查询相同的数据
衡量查询开销的三个指标:
a. 响应时间 响应时间包括服务时间和排队时间;服务时间:是指数据库处理这个查询真正花了多长时间,排队时间:服务器因为等待某些资源而没有真正执行查询的时间(可能是IO,行锁等等);
b. 扫描的行数;
c. 返回的行数 较短的行的访问速度更快,内存中的行比磁盘中的行访问速度更快;较短的行数,是在内存中查询,当行数较多时则在磁盘中查询;
将查询方式进行重构
a. 一个复杂查询还是多个简单查询;
b. 切分查询(大查询分为小查询,例如:大扫描行数查询切分成多个小扫描行数的查询);
c. 分解关联查询,优点:让缓存效率更高;让单个查询减少锁竞争;在应用层做关联,容易对数据库进行拆分,提高系统性能;减少冗余记录的查询;