经过前面的介绍,我们差不多都应该知道,针对不同的资源,虚拟化主要包含三个方面的内容:计算虚拟化、存储虚拟化和网络虚拟化,接下来咱们就来看看,什么是计算虚拟化中“内存”虚拟化。
1. 内存虚拟化简介
内存虚拟化的产生源于 VMM 与 Guest OS 在对物理内存的认识上存在冲突,造成物理内存真正拥有者——VMM 必须对系统访问的内存进行一定程度上的虚拟化。
咱们先来看看,在非虚拟化环境下的情况:
(1)首先:指令对内存的访问通过处理器来转发;
(2)然后:处理器将解码后的请求放到总线上;
(3)最后:芯片组负责转发。
为了唯一标识,处理器将采用统一编址的方式将物理内存映射成为一个地址空间(物理地址空间)。这包括两层含义,其一,操作系统会假定内存地址从 0 开始;其二,内存是连续的或者说在一些大的粒度(比如 256M)上连续。
在虚拟环境里,VMM 就要通过模拟手段,使得虚拟出来的内存仍符合 Guest OS 对内存的假定和认识。如此一来,内存虚拟化就需要解决如下的问题,
(1)其一,物理内存要被多个 Guest OS 同时使用,但物理内存只有 1 个,地址 0 也只有一个,无法满足同时从 0 开始的要求;
(2)其二,由于使用内存分区方式,物理内存分给多个系统使用,Guest OS 内存连续性可解决但不灵活。
为了解决以上的问题,咱们的攻城狮们引入了一层新的地址空间——客户机物理地址空间(GPA)来解决让 Guest OS 看到一个虚拟的物理地址,让 VMM 负责转化成物理地址给物理处理器执行。Guest Machine 以为自己运行在真实的物理地址空间中,实际上它是通过 VMM 访问真实的物理地址的。在 VMM 中保存 Guest Machine 地址空间和物理机地址空间之间的映射表。如下图所示:

因为 VMM 掌控所有系统资源,因此 VMM 握有整个内存资源,其负责页式内存管理,维护虚拟地址到机器地址的映射关系。因 Guest OS 本身亦有页式内存管理机制,所以 VMM的整个系统就比正常系统多了一层映射:
(1)虚拟地址(VA),指 Guest OS 提供给其应用程序使用的线性地址空间;
(2)客户机物理地址(GPA),经 VMM 抽象的、虚拟机看到的伪物理地址;
(3)机器地址(MA),真实的机器地址,即地址总线上出现的地址信号;
映射关系如下:Guest OS:GPA = f(VA)、VMM:MA = g(GPA)
VMM 维护一套页表,负责 GPA 到 MA 的映射。Guest OS 维护一套页表,负责 VA 到 GPA 的映射。实际运行时,用户程序访问 VA1,经 Guest OS 的页表转换得到 GPA1,再由 VMM 介入,使用 VMM 的页表将 GPA1 转换为 MA1。
2 内存虚拟化的基础:页表虚拟化技术:
2.1 页表虚拟化技术原理
普通 MMU(Memory Management Unit,即内存管理单元)只能完成一次虚拟地址到物理地址的映射,在虚拟机环境下,经过 MMU 转换所得到的“物理地址”并不是真正的机器地址。若需得到真正的机器地址,必须由 VMM 介入,再经过一次映射才能得到总线上使用的机器地址。如果虚拟机的每个内存访问都需要 VMM 介入,并由软件模拟地址转换的效率是很低下的,几乎不具有实际可用性,为实现虚拟地址到机器地址的高效转换,现普遍采用的思想是:由 VMM 根据映射 f 和 g 生成复合的映射 fg,并直接将这个映射关系写入 MMU。
2.2 内存虚拟化分类
当前采用的页表虚拟化方法主要是 MMU 半虚拟化(MMU Paravirtualization)和影子页表(全虚拟化),后者已被内存的芯片辅助虚拟化技术所替代。
(1)内存全虚拟化技术(即影子页表虚拟化)
通过使用影子页表(Shadow Page Table)实现虚拟化。VMM 为每个 Guest Machine 都维护一个影子页表,影子页表维护虚拟地址(VA)到机器地址(MA)的映射关系。而 Guest Machine 页表则维护 VA 到客户机物理地址(GPA)的映射关系。下图示意:
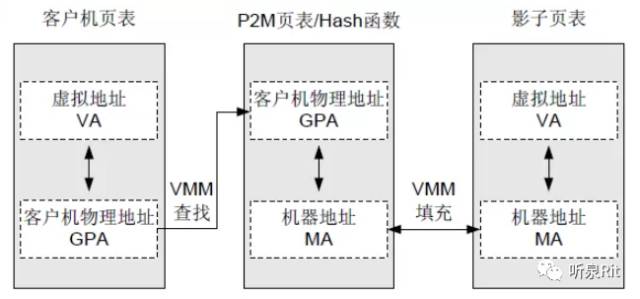
当 VMM 捕获到 Guest Machine 页表的修改后,VMM 会查找负责 GPA 到 MA 映射的 P2M 页表或者哈希函数,找到与该 GPA 对应的 MA,再将 MA 填充到真正在硬件上起作用的影子页表中,从而形成 VA 到 MA 的映射关系。而客户机页表则无需变动。
注意:影子页表一般特指有多个页表缓存的方案。
其优点主要来自于性能上的提升。由于时间局部性,系统中经常会是几个进程之间回来切换,所以哪怕是 4 组页表缓存,其重用率也可达到 80~90%。
其缺点是由于要维护多份页表缓存,还是存在一定的额外开销,并且由于要存放这些缓存,内存上也会有些消耗。这些缺点可以通过 MMU 半虚拟化来解决。
(2)内存半虚拟化技术(MMU 半虚拟化)
其基本原理是:当 Guest OS 创建一个新的页表时,会从它所维护的空闲内存中分配一个页面,并向 VMM 注册该页面,VMM 会剥夺 Guest OS 对该页表的写权限,之后 Guest OS 对该页表的写操作都会陷入到 VMM 加以验证和转换。VMM 会检查页表中的每一项,确保他们只映射了属于该虚拟机的机器页面,而且不得包含对页表页面的可写映射。后 VMM 会根据自己所维护的映射关系,将页表项中的物理地址替换为相应的机器地址,最后再把修改过的页表载入 MMU。如此,MMU就可以根据修改过页表直接完成虚拟地址到机器地址的转换。
简单来说,如果通过使用页表写入法实现虚拟化。即 Guest OS 在创建一个新的页表时,会向 VMM 注册该页表。之后在 Guest Machine 运行的时候,VMM 将不断的管理和维护这个表,使 Guest Machine上面的程序能直接访问到合适的地址。
Xen 是 MMU 半虚拟化的主要使用者。
(3)内存硬件辅助虚拟化技术-内存全虚拟化(影子页表)的替代者
内存的芯片辅助虚拟化技术是用于替代虚拟化技术中软件实现的“影子页表”的一种芯片辅助虚拟化技术,其基本原理是:
GVA(客户操作系统的虚拟地址)-> GPA(客户操作系统的物理地址)-> HPA(宿主操作系统的物理地址)
其中两次地址转换都由 CPU 硬件自动完成(软件实现内存开销大、性能差)。
在这种方案中,Guest OS 完成 VA 到 GPA 这第一层转化,硬件帮忙完成 GPA 到 MA 这第二层转化。第二层转化对于 Guest OS 来说是透明的。Guest OS 访存时做的事和在裸机上跑时一样,所以可以实现全虚拟化。这种特性 Intel 和 AMD 都有支持。Intel 称之为Extended Page Tables (EPT),AMD 称之为 Nested Page Tables (NPT)。其优点是hypervisor 省了很多活,缺点是需要硬件支持。
以 VT-x 技术的页表扩充技术 Extended Page Table(EPT)为例,首先 VMM 预先把客户机物理地址转换到机器地址的 EPT 页表设置到 CPU 中;其次客户机修改客户机页表无需 VMM 干预;最后,地址转换时,CPU 自动查找两张页表完成客户机虚拟地址到机器地址的转换。下图示意:
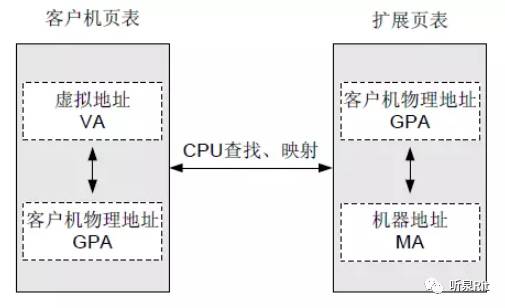
使用内存的芯片辅助虚拟化技术,客户机运行过程中无需 VMM 干预,去除了大量软件开销,内存访问性能接近物理机。
KVM 主要使用内存硬件辅助虚拟化。
图片授权基于:CC0协议