运维团队天天忙着应付各种异常,长久处于高压状态下。本文作者将分享这两年他对一些运维问题的分析和团队管理的方法。
大家好,我是来自平安科技数据库技术部运维团队的刘书安,从 2014 年开始,配合平安集团的互联网金融转型。
我们运维的数据库从单纯的 Oracle 数据库转向多种数据库的运维,当前管理的各类数据库的实例已经超过了一万个。在这种情况下,我们连续两年保持了数据库零故障的状态。
事实上在之前,运维团队也是天天忙着应付各种异常,长久处于高压状态下。之后经过我们团队一系列的优化和改造,目前系统已稳定很多。这期间也确实发生了很多事情。
接下来就跟大家简单介绍一下我们这两年对一些运维问题的分析和团队管理的方法,抛砖引玉一下。
问题解决
首先我们从这张图说起:
这个是扁鹊向魏王介绍他们三兄弟的医术:
- 扁鹊自己是在病人病入膏肓时用虎狼之药将对方救活。
- 扁鹊的二哥是在别人生小病时将人治愈。
- 扁鹊的大哥则是在病情未发时铲除病因让人避免生病。
在扁鹊看来,三个人的医术排序应该是:大哥>二哥>扁鹊;但在世人眼里却是:扁鹊>二哥>大哥。
我比较认同扁鹊的观点,因为我一直都觉得 DB 的运维人员不应该只是背锅侠,而是应该把自己当成医生来对待问题,不只是关注问题的解决,更需要多关注如何避免问题的发生。
我们在数据库异常时去解决问题,别人可能会认为我们是高手,能把问题解决好、事情处理掉。
但实际上这时的运维已经是一个被动式的处理,即便我们用了最快的手段去解决,故障已经发生了,可能还造成了比较严重的影响。
如果我们能提前发现这些问题并解决掉,就能避免很多故障和影响的发生。因此在我看来,运维相对高明的手段应该是:在做架构或设计时就把能想到的问题预先解决掉,确保系统的可拓展性和高可用性。
运维也应该多从架构的角度去考虑问题,并将这些问题提前解决好,而非被动地等待问题发生后才去解决。
接下来和大家介绍我们团队解决的三个案例,以及之后我们通过什么方式避免问题的发生:
案例一
这是我们在 2016 年解决的案例,当时 Oracle 数据库的版本是 11.2.0.4,这种数据库使用 SPM 固化 TOP SQL 的执行计划,确保系统的稳定。

当时异常的问题是,几乎每次发完大的版本后,已有的功能都会多少受到影响,有一些语句的执行计划会发生异常。
我们发现,绝大多数语句都和这个语句是类似的,中间有一个 SKIP SCAN(跳跃式扫描),很明显可以看出它是一个输入时间(对着用户的),有一个范围查询。
所以我们当时就基本判断问题出在这里了,使用的解决方案是通过重新固化执行计划来选择好的执行计划。
接着就开始分析问题产生的原因。
对于索引跳跃式扫描而言,在一般情况下,如果运维索引的***个列没有用到,当它开始使用到第二个列时,就只能用跳跃式的方法去进行一个索引扫描。
而在分析问题原因时,因为类似的语句比较多,我们当时在固化了几十条后,发现还有源源不断的类似语句出现,就考虑到问题可能并没有那么简单。
所以我们又进行了进一步分析,***发现可能是索引的统计信息有问题。于是我们就重新收集了索引的统计信息,至此,类似的语句问题才算是解决了。
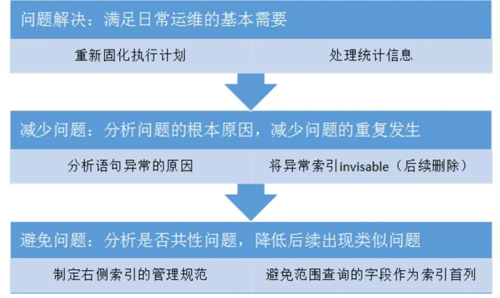
但其实这个问题并没有彻底结束:
我们在处理完后又重新分析了这个索引的问题,发现索引***列是一个空值,但不知道是谁在空列和输入时间上建了一个符合索引,导致这个索引有可能会被使用。
发现问题后,我们就查询了这个索引的访问方式,看看是否全都是 INDEX SKIP SCAN。
后来发现,基本上访问这个索引的语句都用的是这种索引跳跃式扫描,所以我们当时就把这个索引设置为不可用,后面把它删除了。
类似的索引,我们当时处理了有三个,之后这个系统就没有再出现这样类似的问题。
SPM 也是一种固化执行计划的方式,但为什么在这个库里,SPM 会失效呢?
之后我们分析了它的原因:是因为每次发版本时,有可能会多查一些字段,导致语句发生变化。
SPM 这类的固化执行计划的方式都和语句有强关联,只要语句上有一个小小的改动,都会导致固化的方式失效。这也是每次更新版本语句都会发生异常的原因之一。
之后我们继续分析,为什么这个时间索引有这种类似问题?
这是我们之前整理的一个案例分析的原因:我们在做索引的范围查询时,它的选择率公式如下 :
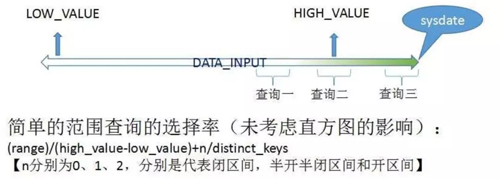
但是在不同情况下,比如这种右侧索引,比如创建时间、更新时间、输入时间,我们写入数据都是用 sysdate 写入的,那么它永远都在索引列的右侧,类似这种方式是往里面插入数据的。
然而我们统计信息的收集又不是一个实时收集的,主要是对一些大表,比如一个一千万的表可能要到 10%,也就是 100 万的 DMR 量;更大的表的DMR量会更大。
这就会导致我们的统计信息和当前的值永远是过时的,就会产生下面的问题。
对于这三个查询来说:***个查询发生在有效范围内,所以它可以反映出一个比较真实的数据;第二个查询也可以反映一部分。
但第三个查询就相当于完成一个超范围的查询,计算出一个很低的值,这样就会导致我们的语句偏异常。
更坑的是在 OLPP 系统里,新数据查询的几率永远比老数据的大,越新的数据被访问的几率越高,这也导致我们的语句每次都会出现异常的情况。
发现这些问题后,我们立即展开了一个行动,就是把数据库里所有与时间索引相关的字段都提取一下。
然后定期修改索引字段上面的 HIGH VALUE,统计信息里面的 HIGH VALUE,就能避免出现这种问题。
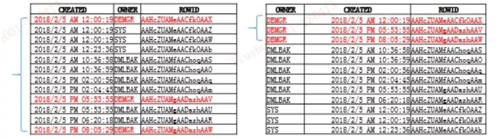
如上图所示,是一个范围查询的情况,即在一个索引前导列的区别,类似于我们在创建时间和 OWNER 之间建索引。
如果把创建时间放在前面,把 OWNER 放在后面就是***种情况;如果把 OWNER 放在前面,把 CREATED 放在后面就是第二种情况。
现在来分析这两个不同索引的区别:
当我们把创建时间放在前面时,有一个很大的问题,我们通过时间字段去查询时很难做到等值查询,即不可能去发现每分每秒插入的值。
对于这种查询,我们一般都使用范围查询,比如查一个月或一天、一周的数据。
所以大家可以看到,如果我在这个语句内查这一分钟、这一天 DBMGR 创建的情况,在***个索引里它整个范围都会涉及到,随后取相关联的三个值。
但是在第二个索引里,三个值是连在一起的,因为 DBMGR 是有序的,时间也是有序的,它们就可以完成只涉及到自己相关值的值。
这里面还有一些细小的区别:如果我先进行范围查询,后做等值查询,对于这样的索引,Filter 时就会多做一个 Filter 步骤。
但如果把这个顺序调整一下,就不会有这种情况。所以我们在做这种符合索引创建的时候,就一定要尽量把等值查询的放在前面。
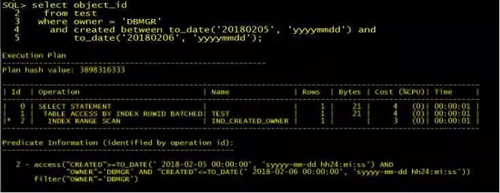
之前有一个说法:在选择符合索引的前导列时,要把选择率比较低的值放在前导列。
但我们觉得这个说法是不完善的:比如对于一个时间字段而言,一天有 86400 秒,100 天就可能有 800 多万的不同值,一年会有更多不同值。
可如果把这个作为前导列,有时候是不适合的,因为对它来说,有可能我们是需要查询一天或一个月的数据,而一年有 365 天,或者说十二个月。因此更准确的说法应该是把查询条件中选择率低的列做为复合索引的前导列。
所以通过这个案例,我们就把运维问题的解决分成了三个步骤:
- 快速解决问题,确保应用恢复。对于运维人员来说,恢复应用是***位的。
- 看问题是不是重复性发生的。比如前面说的案例一,如果我们当时的处理方案仅是固化执行计划,或是收集统计信息,你没有办法保证它以后不会再出现类似的情况。
如果我们使用的是收集统计信息的方式,可能再过一个月或两个月,这种情况又会再次发生,所以根本的解决方案是找到这个问题发生的原因,确保这次问题解决后不会再复发。
- 避免问题,看这个问题是否属于共性问题、其他库里有没有类似问题。如果有类似问题,就要形成一种规范,去避免这种问题的发生。
尤其是对于一些新的应用来说,只有当你制定规范、让开发遵守后,后续才会减少类似问题的发生,不然就会演变成我们一边解决问题,新问题又源源不断发生的情况,***我们只能不断地去解决这种重复发生的问题。
我记得之前有一个案例就是共性问题:当时是在一个实际的库里,我们分析发现它存在内存泄漏的问题,但并没有马上开始处理,结果第二天另一个库也发生内存泄漏,于是我们不得不紧急重启。
当时我们分析出问题是由某一个 Bug 导致后,就搜索那个 Bug 相关的信息,发现早在两三年前(2014 年)已经有同事解决了这个问题。
只不过在另一个库里还打了相应的 PATCH 来解决问题,但就是因为没有把这个问题推广到所有系统里,排查是否其他库也存在这个问题而引起的。
从那之后我们就特别注意这种共性问题,如果每个系统、每个问题都要发生一次,代价实在是太大了。
所以我们尽可能在发现共性问题后就解决掉,尽量排除其他库也发生类似问题的情况。
案例二
第二个案例是一个版本为 12.1.0.2 的 Oracle 数据库,每到晚上总会不定时地主机 CPU 持续到 100%,应用同时会创建大量的数据到数据库中。
当时我们的应急方案是把这种相关的等待时间全部批量 Kill 掉,因为这些系统是在比较核心的库里,基本上每个系统被 Kill 掉的进程有几千个,代价还是比较大的。
后来这个问题发生两次后,我们开始着手重点分析问题,通过 ASH 分析发现,出现这个异常等待是因为一个很简单的语句—— SELECT USER FROM SYS.DUAL。
之后我们就通过这个语句来一步步关联, 看到底是哪个地方调用的,结果发现是在一个应用用户的登录 TRIGGER 中的用户判断步骤。
这个 USER 是 Oracle 的内部函数,但就是这么简单的一个语句,就让整个库都 Hang 住了。

然后我们开始分析原因,我们通过 ASH 发现该语句在我们恢复应用前有重新加载的过程。
当时我们怀疑是硬件导致的,就通过这种方式去分析,结果发现是在晚上 10 点时被 Oracle 的自动任务做了一个统计信息的自动收集。
收集完后,又因为它是一个登录的 Trigger,用户在不断登录,在做登录解析时这个语句就没办法解析,所以才导致用户源源不断地卡在那里。
而应用是需要新建连接的,新建的连接又无法进到库里面,就会导致连接数越来越多,全都卡在那里。***我们通过锁定 dual 表统计信息的收集来从根本上解决这个问题。
案例三
第三个案例有两个问题,但后来我们发现这两个问题是由相同的原因引起的。
我们有一个数据库是从 10.2.0.5.X 升级到 10.2.0.5.18 版本,升级后会不定时出现 cursor:pin 相关的一些等待。
其实出现 cursor:pin 是很正常的,因为这个数据库的负载比较高,变化也较高,但问题是它是在升级之后出现的。运营认为这是升级之后出现的异常,我们就开始着手分析问题的原因。
第二个问题是我们在应急时发现的,有时异常出现时,某个库里有些语句的执行次数会特别高,甚至 15min 能达到上亿次,这对于一个正常的业务系统来说,出现这么高的执行频率是不正常的。
之后我们就去分析这些问题,发现这两个问题有相同的一些点:比如语句中间出现了个函数调用;比如说这个情况下,A 表如果访问的数据量较大时,这些函数就有可能被调用很多次。
我们发现,有一个语句,它执行一次可能会出现十几万次的函数调用。如果在调用的过程中,关联的那张表的执行计划发生了变化,比如说A表走了一个全程扫描,那可能会出现几千万次的函数调用。
当时我们也总结了一些关于通过什么样的方法去快速定位、是否是函数调用导致的看法。
在 Oracle 10g 之前确实没有什么好的办法,因为它里面没有一个显示的关联,就可能通过代码去扫描,去找对应的语句。
在 Oracle 11g 后会比较简单一些,通过 AS 值相关的 TOP LEVEL SQL ID 就可以直接关联到是哪个语句调的函数导致的问题。
这里还有一个问题是函数调用。因为它调用的函数可能都是特别快的,但次数又会比较高,性能波动可能带来比较大的影响。
之前我们有一个案例就发生在月底高峰,我们当时发现某个数据库中会出现很多 CBC 的等待,后来又发现有一个小表被频繁访问,那个小表就 100 多行数据,但可能它相关的语句每隔 15min 就调用了上千万次。
其实这么高的并发下,出现这种 CBC 的等待是很正常的。不过因为它只有 100 多行数据,且都集中在一个数据块里,所以才导致这个数据块特别热,就会一直出现这种 CBC 的等待。
于是我们就找办法解决这个热块的问题,但又因为不能在月底冲业绩时停运来做修改。
所以我们就想了一个方案:建一个 PCT FREE 99 的索引,把表所有列的数据都包含进去,确保每个索引块里面只保留了一行数据,变相地把这 100 多行数据分到 100 多个块里。
做了这个操作后,CBC 相关的问题被解决了,也顺利地撑过了业务高峰期,但是第二天月初的报表发现又掉坑里了。
因为我们在每个月月初需要上报给监管的一个报表,这种报表是属于一个长事务。
但是它在那个报表里面也是调了之前优化的那个索引,优化后的语句虽然降低高峰期 CBC 的等待,但因为它是要访问 100 多个数据块,单次访问从 0.25 毫秒变成了 1 毫秒,相当于效率降低了 4 倍。
由于报表是一种长事务的处理,相当于那个进程比原来多花了一倍多的时间也没跑完。
所以之后我们发现这个问题后,又不得不把那个索引给干掉了,让它恢复原来那种状态。
尤其是现在对 IT 的要求越来越高,时限的要求也越来越高,很多系统基本都是用这种敏捷的开发方式尽快地上线。
新系统上线有一个很大的问题就是刚上线时压力都不会很大、负载也不高,但其实很多问题在开始阶段被隐藏了。
等到真正发生问题时,负载高了或者压力大了再去解决问题,难度就会比较大一点。
尤其对于数据库来说,数据库量小的时候,比如说 300、500M 的数据,这个表格怎么整改都很简单,但等到这个表涨到 300、500G 甚至 1、2T 时再想去做这个表数据类的整改,难度就会大很多。
比如说,我们之前做分期表整改时会用这种在线重定义的方式,但对于一些比较大的表,几百 G 甚至上 T 的表,再用这种在线重定义的方式,就会遇到各种各样的 Bug。
后来坑踩多了,我们现在对于大表的分表改造就是先同步历史数据级改造,后做一个数据增量,方法会复杂很多。
但其实如果在开始阶段,我们对于这种大表就已经设计好它的分区,尤其在时间索引上,基于时间去做一个分区,可以避免很多问题。
为什么我们的历史库里有那么多时间索引?
很大的一个原因是有很多报表是基于时间去查询的,比如说要查这一个月或者这一天新增的一些数据的情况,都需要通过时间的字段去访问。
我之前就见过很多关于时间的索引,但***却因为时间索引的特性,导致系统源源不断地出现各种各样的问题。
如果在设计阶段把这些大表提前就设计成分区表,完全可以避免这些不必要的问题。
运维管理
因为各个公司具体情况不同,我接下来就简单介绍一下我司关于运维管理的一些做法,给大家做个参考。
变更管理
相对来说,我们公司的变更管理比较严格,后续可能会更加严格。
变更管控
对于变更管控,比如在白天严禁做任何变更,工作时间内任何变更都不能做,即便是一些紧急或故障的修复,也是需要通过部门负责人确认、领导同意后才可以做的,确保风险可控。
变更流程
可能每个公司都有变更流程,但我们公司有一个比较特殊的地方。因为一些兼容数据库的要求可能会高一些,流程管控的每个部分都要确保到位。
变更方案
我们的变更方案是每个人要提前去做评审和验证,包括制定方案的同事和实施操作的同事,就需要变更实施人员提前在一个环境下做完整的验证,确保每个步骤都是验证通过的。
规范管理
架构规范
我自己之前在做架构师时,制定各种各样的规范是一项重点的工作。可能是养成习惯了,现在也和大家一起制定各式各样的运维规范。
但我自己感受最深的是:规范一定要有统一的标准,如果做不到统一就有可能会在后续产生问题。
比如我们之前有些开发测试环境不是那么规范,现在想改造做自动化时,发现根本就做不起来,因为每个库的情况不一样,自动化的脚本不可能适应所有情况来做这种标准化的改造。
把它弄成不标准是很简单的,但要想把不标准的改成标准的,难度就大了,尤其是在我们已经形成习惯之后。
运维规范
在 2014 年前,我们做的是纯 Oracle 数据库的运维,因为之前建立的是一个传统的金融企业,运维的都是 Oracle 数据库,但 2014 年后我们逐步转向了互联网金融。
因此我们陆续研究了 MySQL、PG、Redis、MongDB、SQL Server、HBase 等 7、8 种数据库,在运维过程中遇的坑就会比较多。
最初有很多标准,但没有一个是***的实践,很多也是根据业界、自己的经验制定出来的;还有各种不同的数据库里,不同的团队制定了不同标准,***就有各种各样的标准了。
所以我们在运维中会发现各种各样的问题,***要强制去做这方面的规范整改。
而且,之前的标准大部分都没有经过大规模使用和大规模负载的验证,很多标准并不那么统一、规范和有效。
因此,我们在运维过程中对于这种规范,还是在不断地去优化和改进,毕竟很多情况在没有遇到时,你真的是没有办法去解决这个问题。
规范优化
举个例子,最初我们并没有规定 Redis 一定要和应用放在同一个网络区域,但随着 Redis 的负载增加,我们发现防火墙已经承受不了。
当时平安的 WiFi 刚上线不久,但关于 Redis 的访问,几个实例每秒都有高达上万次调用,整个防火墙都撑不住了,还差点导致一个比较严重的故障。
在解决这个问题后,我们就制定了一条强制的规范:Redis 这种高并发访问的数据库,一定要和应用放在一起,不能有出现跨墙访问的情况。
所以这个规范也是不断去优化的,包括我们运维的一些标准。因为在最初创建标准时,我们可能会因为使用时间不长而考虑不到一些问题。
我印象比较深刻的是 MySQL 刚引入时的一个问题,对于软件的版本没有明确到小版本。
后来甚至出现有 MySQL 停库时是 5.6.22 的版本,在维护完成后就被启动成 5.6.16 的版本。
***是通过不断地优化来确保我们的规范和实际是相结合的,避免这种问题的发生。
人员发展
团队意识
关于团队这块,需要提升每个人在团队中的作用,需要确保团队里的每个人都是有备份的。如果发展成离开谁都不行,那对团队的整体发展来说是不正常的。
所以我们在安排工作时,对于比较重要的工作,我会尽量不让熟悉的同事重复去做,而是尽量让一些不熟悉的同事参与去做。
之前每走一个资深成员,都会明显感觉到团队的整体技能或知识少了一块。为了避免类似问题的发生,从 2017 年开始我们就制定了一些策略,让大家做知识技能的分享,每周抽取两个下午,每个下午抽取一到两个小时做分享。
另一个策略是技能的积累,即把我们在工作中遇到和解决的一些问题都录入问题管理系统。
这样做有两个好处:
- 可以把重复的问题记录下来,因为我们想要去分析哪些问题是重复发生的、哪些是有共性的,就需要有一个这样的系统去拉对应的问题清单,***去解决问题。
- 即便人员流失了,他们之前解决的一些问题和技能也能让团队其他人发现,不至于每走一个人就留下一个坑。
所以我们是通过这种手段来尽量避免人员流失或变动给团队带来的一些问题。
但说到底,这种事这是没办法完全避免的,因为数据库运维有一定的复杂度,需要依靠不断地发生故障、解决故障,包括一些人为失误来提升。
权责分明
我们的轮班人员是 7×24 小时,即上三班的方式来轮班的。之前团队有一个比较严重的问题,当一件事情发生了,轮班人员有可能将问题交接给下一班次;或是升级给其他人后,就觉得与自己没有关系了。
还有就是风险意识不强,有一些操作没有评估过影响就开始在生产库里操作。
当时我们也发生了不少问题,后来在内部重点提升两点意识:责任人意识和风险意识。
首先你需要在生产做措施前,确保要做的操作会有什么影响、导致什么后果,不能在做完后才去想这个问题:比如说我们现在每天变更,都需要提前把脚本和手册做好,让值班人员熟悉。
操作会有什么后果?后续有什么异常会发生?应对方法又是什么?……这些都是需要提前评估好的。
技能提升
关于技能提升,虽然必要的培训是必不可少的,但我们认为关键还是要靠自己的学习、理解和在实践中的积累,并没有什么好的捷径去实现,大多时候还是要通过不断地解决问题、发现问题甚至包括犯错的代价来提升的。
刘书安,平安科技数据库技术部运维团队经理,当前任职于平安科技数据库技术部运维团队,有十余年的数据库管理经验,有多年数据库架构设计和运维管理经验,熟悉性能调优和故障处理。目前主要负责平安科技数据库运维的管理工作,团队负责运维的数据库种类包括 Oracle、PostgreSQL、MySQL、Redis、MongoDB 等多数数据库的运维管理工作。