












运维开发这个岗位与普通的业务开发不同,与日常的运维工作也不同,它要求兼顾开发与运维两种能力。
既要掌握不弱于业务开发的开发技术;又要负责 SRE 同学日常的运维能力;上线之前,还要像 QA 同学一样,对自己的服务进行测试和分级变更。
多种能力的交叉,造就不一样的视角,这群人给自己起了一个很简约的名字:DevOps。
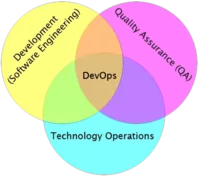
按百度百科解释:DevOps 是开发、技术运营和质量保障三者的交集。在我看来,DevOps 其实只是一种方法论,从这种综合的视角出发,包含一些基本原则和实践方法,仅此而已。
DevOps 从架构、开发、测试、发布、运维、变更整个流程来考量,从这种综合的视角出发,能将部门之间的沟通隔阂消灭于无形,会给我们公司和项目注入新的活力。
DevOps 这个概念,本文暂不做讨论,本文内容只针对运维领域自动化平台开发的工作进行探讨。
运维开发的工作,所需能力的复杂,工作性质的交叉,自然会导致很多同学在其中会有些困扰。
很多刚毕业的同学,接到运维开发的 offer 的时候,很可能是一头雾水:“运维?开发?到底是运维还是开发?”
有很多从业多年的同学,拼命的追求技术与对底层的探索,却忽略了产品层面的思考。
还有很多整天忙忙碌碌的同学,在业务方各种零碎的需求中修修改改,消耗了大多数的时间,最终平台却变得千疮百孔。
本文,我将自己关于这些问题的思考分享给大家。
什么样的平台是好的运维平台?
既然我们是在做平台,那我们要了解的第一点就是:好的运维平台是什么样子的?如果让我们来从头设计一个平台,我们应该如何去考量?
效率 & 成本的均衡
运维平台是服务于运维的。对运维来说,除了稳定性之外,最重要的无非就是效率与成本。
如果我们的平台可以用更少量的时间或资源成本来提高更多的效率,那就是一个非常成功的平台了。至于如何量化比较,就因系统而异了。
体验 & 人性化
为什么我要把体验放在第二位?因为有太多的运维开发工程师,在开发的过程中,过多地注重系统的稳定性和性能,完全不把体验放在眼里了。
我想说的是,有时候,如果不关注用户体验,我们做了再好的功能,没有人用,那这个功能意义何在?用户价值与用户体验在某些情况下,是会画等号的。
优秀的系统架构
在业界,无论是运维系统也好,业务系统也好,优秀系统的架构都是大同小异的:
- 稳定性:负载均衡、多活等。
- 扩展性:每次增加功能,可以很小的开发成本实现,而不是每次都要重构。
- 伸缩性:没有核心的单点,大部分性能瓶颈,都可以通过横向扩展来解决。
- 自我保护:把可能会导致性能瓶颈的点都拆解开,用队列、限流等手段消除流量突增的高峰带来的危害,保护自身。
- 安全性:敏感服务加入权限与认证,Web 服务避免常见的漏洞如 SQL 注入、XSS、CSRF 等。做好操作记录方便后续审计,尽量不要出现短板。
如何运维自己开发的平台?
运维开发在大多数时候,要负责运维自己开发出来的系统,俗称吃自己的狗粮;而很多人跳槽之后,第一件事情,也是从运维别人的系统开始的。那我们如何运维好一个平台呢?
运维与开发的工作,思路其实不尽相同。虽然都是基于稳定性来考量,但可能要想的更多、更广,任何有可能影响到我们业务的稳定性的因素,都要考虑在内。
用我的总监的一句话来讲,就是:我们运维同学与开发同学,最大的不同点,就是稳定性的意识。
架构上的稳定性
这个更多的是比如多活、负载均衡、流量调度、硬件冗余之类的考量:服务在实例挂掉的时候,如何不影响稳定性;专线断开的时候,如何仍然正常的提供服务等等。
快速地发现问题
无论我们的架构多么完善,也很难做到尽善尽美。那么在一些需要人为介入处理的故障中,快速地发现异常,能直接降低服务的不可用时长。
因此,对于一般的服务,将报警配置地更完善是我们能快速定位异常的第一步。
还有,对于监控系统,自身的故障不能通过自身的监控来发现,最好还有一套独立的自监控。
应急预案&演练
在梳理一个服务的运维工作时,我们能很明确的感知到某个地方出问题需要人力介入。而除变更之外的一般的故障,我们都是可预见的。
一旦真的出现这种问题,如果我们没有准备,即使知道如何去做,也可能会因为手忙脚乱而出错。
因此,设定一些可能发生情况的应急预案,定时演练,是一个可以在故障时快速恢复服务的手段。
自我保护
一般的系统,都有上游,如何保证上游的数据异常不对自身产生影响,也是很重要的一点。
总结起来,总共有三类:
- 过载保护:上游流量太大,导致自身服务不堪负重。这种情况要根据场景不同,考虑加入消息队列,或者限流。
- 脏数据保护:上游来的数据,是否应该完全信任?是否有脏数据来影响我内部数据的准确性?比如安全扫描的流量,很大程度上就会对很多系统产生脏数据。这种最好有过滤的规则的配置,能摘除这部分流量。
- 上游变更保护:上游的变更,需要及时知晓和跟进。如果上游不够规范,很可能会修改接口或者数据格式。即使上游规范,也要跟进上游变更容易造成的影响,人为确认没有问题。
容量规划
随着系统负载的升高,系统的服务能力并不是线性下降的。当负载到达临界线的时候,一个逐渐变慢的系统最终会停止一切服务。
因此,要在系统瓶颈到来之前,预估未来一段时间内服务的量级,在量级到来之前,做好应对措施。
笔者公司目前有一个 Topic,就是全链路压测。运维团队与所有业务团队一起建设,压测常态化,每时每刻对系统全链路各个环节的瓶颈都了如指掌。就是在做这件事情。
变更管理
SRE 的经验告诉我们,大概 70% 的生产事故都是由某种部署的变更而触发。
因此要管理好我们的变更机制:
- 采用分级发布机制:先 pre、再小流量、再中流量、再全量。
- 制定全面 Check List:保证变更部分所有功能都有测试可以覆盖,能快速发现问题,第一时间回滚。
- 出现问题,先回滚,再定位:这个不用多说,先止损,再慢慢查问题。
除了开发与运维,我们还要做什么?
运维开发的定位,注定要比业务开发承担更多的责任。因为这群人除了是自己的 RD,还要自己做自己的 PM、OP、QA。
因此,我们要考量的,还有产品和需求层面的东东:
需求管理
作为开发,尤其是没有正经 PM 的开发,管理好需求可以让我们把精力放在最重要的地方,解放我们的精力、提高产出。
流程闭环:从用户每次提一个需求开始,一直到这个需求跟进结束,或者需求被讨论后打回,都要有一个详细的流程管理工具,笔者公司用的是 JIRA。
有了这个工具,就可以很好的看到需求的状态,便于跟进和统计,真正解放我们的笔记本。
把控好优先级:根据项目的定位,来划分需求的优先级。比如,对于一个运维平台项目,一般来讲用户比较固定,针对的是一群高玩 SRE,那优先级考量是:稳定性 > 性能 > 功能 > 体验。
对于优先级的考量,要经常与自己的上级沟通。由于观点和视野的不同,个人考虑的优先级会与小组或者部门的优先级有所偏离,此时与上级及时的沟通,可以将个人的目标与团队的目标对齐,争取产出最大化。
产品视角 & 抽象能力:我们管理好了需求,确认好了优先级,是不是按照我们的优先级埋头苦干就行了呢?答案当然是否定的。
视角、见解不同的用户们提出一堆细碎的需求,如果我们从头来实现一遍,并不能真正让这些用户满意,却只会让系统越来越烂。
笔者之前就经手维护过这样的系统,勤劳的工程师兢兢业业,满足了一个又一个的需求,各种各样的高级功能。
后来,却由于系统过于复杂,导致最基本、最常用的功能都要找半天。最终不得不重构。
因此,去深度思考用户真正需要的是什么产品,而不是被业务推着走。将用户细碎的需求,真正抽象成平台要建设的一个一个的功能。
经常思考一下:用户虽然提了这个需求,但是他真正的痛点在哪里;多个类似需求之间会不会有什么共通点;是否可以抽象出一个公用的模型,用一个功能来满足多个需求。
量化
If You Can’t Measure It,You Can’t Improve It。量化是优化的前提。
量化有很多方面,比如说量级、延迟、成本,都可以量化。把所有的点量化完之后,我们做事情就不会蒙着头乱撞,所做的事情、所维护的服务,也不再是一个黑盒。
我们可以对它的上下游关系、自身的稳定性作出宏观、统筹的分析。进一步的压测及 SLA 均要依赖量化。
制定 SLA
简言之,SLA 就是在一定的限制条件下我们服务可以保证的质量;是服务的维护者完全的了解了自己的系统,对系统的瓶颈有了深刻的理解之后,所给出的服务质量的保证;同时也是我们服务自身能力的一种说明。
一个系统性能再好,也总会有瓶颈。而把瓶颈和风险让用户知晓,是我们的义务。
对服务的维护者来说,在提供服务之时,约定好服务的 SLA,既能从一定程度上规范使用者的行为,也能在出现问题的时候保护自己。
除了做这些,我们还要思考什么?
制定规范,并让规范在平台落地
规范的制定是一个比较宏观的事情,一般情况是由稳定性负责部门向全公司整体给出的建议。约束的可能是全公司的变更的规则、以及平台的使用方式等。
规范的落地,不能仅仅依靠各方业务的自觉性,也要在平台做好限制与引导。
我们做平台,最终产出的仍然应该是业务的价值:比如效率的提高、成本的降低、稳定性的提高等。规则在平台的落地,可以产生直接的业务价值。
具体的实施方式可以考虑限制和引导两种手段:
- 限制:上线窗口的规范,非上线窗口必须走紧急流程由部门一级管理者审批;监控单台机器上报指标数的 quota,都是使用的限制的手段。
- 引导:通过一些方式,让用户自觉的依照我们的规则来执行。可以使用奖励、通报的一些方式。比如笔者公司的变更信用分、监控健康分都是此类手段。
协调开发与答疑
运维开发的同学们,除了要做自己的 PM 和 QA 之外,有趣的是,还要担任自己的客服。
日常工作中,经典的答疑主要分为两类:使用方式、对平台的质疑。
使用方式的日常咨询,首先可以完善用户手册,把所有的使用方式和常见 Q&A 都写好。
其次可以考虑机器人答疑,目前笔者负责的系统都接入了机器人自动答疑,把一些常见的问题以及文档都加入到知识库里,基本问题都可以解答出来。
除了日常使用的答疑之外,也会有很多的“高玩”来 Challenge 我们的系统。
这些人基本分为两类:
- 对运维平台有深度思考的人,Chanllenge 的同时会带来很多建设性的意见和建议。
- 单纯的小白用户,对系统思考不太深入,喜欢无脑 Chanllenge。
我们也要同时思考如何与这类用户说明,提高小白用户的体验。
因此,给出服务的 SLA、做好服务的自监控、将所有内部状态通过自监控暴露给开发者,而不让自己的服务变成一个黑盒,是我们作为 DevOps 的基本素质。
后记
时光荏苒,倏忽之间,我已从一个小小的实习生,成长到现在勉强可以独当一面的样子。
这些年来,我一直在自动化运维平台开发领域耕耘。从刚开始重构服务树、权限系统模型、堡垒机登录;到后来的流量调度、监控系统报警与存储的深度建设,有很多个人的感悟与成长,这里梳理了一下,分享给大家。
最后附上笔者思考本文时的脑图:
作者:高家升
简介:现任职于滴滴运维部,曾负责滴滴登录系统的建设、监控系统存储与报警链路的重构。曾任职于小米,参与小米自动化运维平台的建设,负责服务树、权限、堡垒机等模块。专注于运维自动化与稳定性建设,代码熟手、Open-Falcon Commiter。















