













1. 一句话总结
内存虚拟化解决虚拟机里面的进程如何访问物理机上的内存这一问题。
GuestOS本身有虚拟地址空间,用GVA表示。虚拟机认为自己独占整个内存空间,用GPA表示。
HostOS本身有虚拟机地址空间,用HVA表示。宿主机本身有物理内存空间,用HPA表示。
好,内存虚拟化的问题变成了GVA->HPA的映射问题。
GVA->GPA通过GuestOS页表映射。HVA->HPA通过HostOS页表映射。因此,只要建立GPA->HVA的映射关系,即可解决内存虚拟化的问题。但,这样三段逐次映射,效率低下。
引入软件模拟的影子页表和硬件辅助的EPT页表。
影子页表:GuestOS创建GVA->GPA页表的时候,kvm知道GVA对应的HPA,并偷偷记录下映射关系GVA->HPA。后续需要GVA到GPA映射的时候,根据影子页表就能查到HPA。
EPT页表:硬件层面引入EPTP寄存器。直接将Guest的CR3加载到宿主机的MMU中。同时EPT页表被载入专门的EPT页表指针寄存器 EPTP。也就是说GVA->GPA->HPA两次地址转换都由硬件实现。
2. 概述
我们知道80386引入了保护模式后,内存空间分为虚拟地址空间和物理地址空间。后续引入页表机制,把虚拟机地址送往mmu,mmu查TLB不中的情况下,依次查页表就可以找到对应的物理地址。
在虚拟化场景下情况略微复杂,分为以下几种:
①GuestOS 虚拟地址(guestOS virtual Adress,GVA)
说白了guestos中进程使用的虚拟地址就是GVA,也就是程序访问逻辑存储器的地址。
②guestOS 物理地址(GuestOS Physical Address,GPA)
Guestos认为的物理地址,也是虚拟机mmu查页表得出的地址但是他本质是一个逻辑上的地址,是引入虚化后产生的一个逻辑概念。它必须借助于内存虚拟化映射到宿主机的物理地址上才能访问内存
③主机虚拟机地址(Host virtul Address,HVA)
宿主机中的虚拟地址,宿主机进程使用的虚拟地址空间。
④主机物理地址(Host Physical Address,HPA)
宿主机真实内存地址,真实可以访问的物理内存空间。
至此,在虚拟机场景下,如何由GVA->HPA就是内存虚拟化的工作。其中,Qemu负责管理虚拟机内存大小,记录内存对应的HVA地址(因为Qemu是用户态的进程,无法管理HPA)想要转化为HPA需要借助于KVM内核也就是影子页表SPT(Shadow Page Table)和EPT(Extent Page Table)
2.1 影子页表
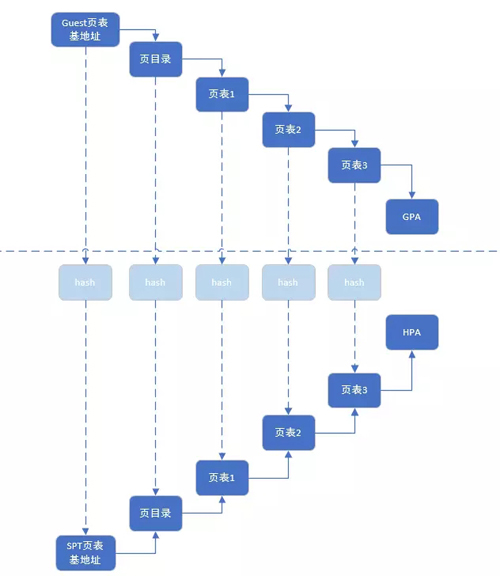
在Guestos建立页表的时候,KVM偷偷的建立了一套指向宿主机物理地址的页表。客户机中的每一个页表项都有一个影子页表项与之相对应,就像其影子一样。
在客户机访问内存时,真正被装入宿主机 MMU 的是客户机当前页表所对应的影子页表这样通过影子页表就可以实现真正的内存访问虚拟机页表和影子页表通过一个哈希表建立关联这样通过页目录/页表的客户机物理地址就可以在哈希链表中快速地找到对应的影子页目录/页表当客户机切换进程时,客户机操作系统会把待切换进程的页表基址载入 CR3而 KVM 将会截获这一特权指令,进行新的处理,也即在哈希表中找到与此页表基址对应的影子页表基址,载入客户机 CR3使客户机在恢复运行时 CR3 实际指向的是新切换进程对应的影子页表。
2.2 EPT
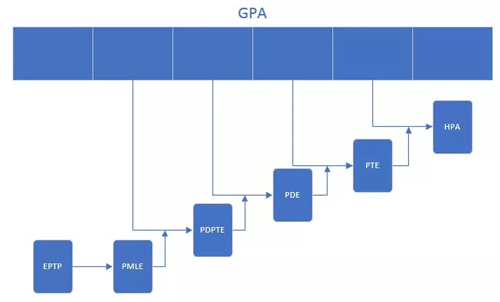
EPT 技术在原有客户机页表对客户机虚拟地址到客户机物理地址映射的基础上引入了 EPT页表来实现客户机物理地址到宿主机物理地址的另一次映射,这两次地址映射都是由硬件自动完成。客户机运行时,客户机页表被载入 CR3,而 EPT 页表被载入专门的EPT 页表指针寄存器 EPTP。
在客户机物理地址到宿主机物理地址转换的过程中,由于缺页、写权限不足等原因也会导致客户机退出,产生 EPT异常。对于 EPT 缺页异常,KVM首先根据引起异常的客户机物理地址,映射到对应的宿主机虚拟地址,然后为此虚拟地址分配新的物理页最后 KVM 再更新 EPT 页表,建立起引起异常的客户机物理地址到宿主机物理地址之间的映射。对 EPT 写权限引起的异常,KVM 则通过更新相应的 EPT 页表来解决。
由此可以看出,EPT 页表相对于前述的影子页表,其实现方式大大简化。而且,由于客户机内部的缺页异常也不会致使客户机退出,因此提高了客户机运行的性能。此外,KVM 只需为每个客户机维护一套 EPT 页表,也大大减少了内存的额外开销。
3. Qemu到KVM内存管理
3.1 设置钩子
main(vl.c)==>configure_accelerator==>kvm_init(kvm_all.c)==>memory_listener_register(&kvm_memory_listener,NULL);将kvm_memory_listener添加到memory_listeners链表中,将address_spaces和listener建立关联
3.2 内存对象初始化
main(vl.c)==>cpu_exec_init_all(exec.c)==>memory_map_init(exec.c)Qemu中系统内存system_memory来管理,io内存用system_io来管理。static MemoryRegion *system_memory.MemoryRegion可以有子区域。而memory_lister负责处理添加和移除内存区域的管理。
3.3 内存实例化
pc_init1(hw\pc_piix.c)==>pc_memory_init这里主要分配整个内存区域重点关注memory_region_init_ram方法memory_region_init_ram==>qemu_ram_alloc(获得内存的HVA记录到)==>qemu_ram_alloc_internal==>ram_block_add(生成一个RAMBlock添加到ram_list,hva放到host字段)==>phys_mem_alloc==>qemu_anon_ram_alloc==>mmap
3.4 VM-Exit处理
由于mmio导致的退出,相关处理如下kvm_cpu_exec==> case KVM_EXIT_MMIO==> cpu_physical_memory_rw==> address_space_rw==> io_mem_write
3.5 qemu到kvm的内存调用接口
前面我们讲到注册过listener,当设置内存时会调用到
static MemoryListener kvm_memory_listener = {
.region_add = kvm_region_add,
region_add==>kvm_region_add==>kvm_set_phys_mem
①物理起始地址和长度,在kvm_state中搜索已建立的KVMSlot *mem区域
②如果没找到建立一个slot
==>kvm_set_user_memory_region(通知内核态建立内存区域)==>kvm_vm_ioctl(s, KVM_SET_USER_MEMORY_REGION, &mem)
3.6 KVM内存处理
kvm_vm_ioctl==>kvm_vm_ioctl_set_memory_region==>kvm_set_memory_region==>__kvm_set_memory_region内核态也维护了一个slots,内核态slot的管理策略是根据用户空间的slot_id一一对应的slot =id_to_memslot(kvm->memslots, mem->slot);
①通过用户态的slot获取到内核态对应结构
②根据slot中的值和要设置的值,决定要操作的类别
③根据2中的动作进行操作
a.KVM_MR_CREATE: kvm_arch_create_memslot(做了一个3级的页表)
b.KVM_MR_DELETE OR KVM_MR_MOVE:
申请一个slots,把kvm->memslots暂存到这里。首先通过id_to_memslot获取准备插入的内存条对应到kvm的插槽是slot。无论删除还是移动,将其先标记为KVM_MEMSLOT_INVALID。然后是install_new_memslots,其实就是更新了一下slots->generation的值。
4. EPT相关
4.1 EPT初始化
kvm_arch_init==> kvm_mmu_module_init
①建立pte_list_desc_cache缓存结构
②建立mmu_page_header_cache缓存结构,该结构用于kvm_mmu_page
③register_shrinker(&mmu_shrinker);当系统内存回收被调用时的钩子
vcpu_create==>vmx_create_vcpu==>init_rmode_identity_map==>alloc_identity_pagetable==>__x86_set_memory_region
4.2 EPT载入
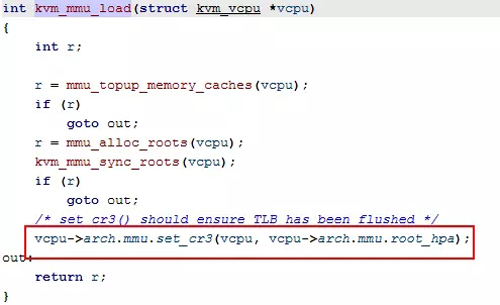
vcpu_enter_guest(struct kvm_vcpu *vcpu)==> kvm_mmu_reload(Guest的MMU初始化,为内存虚拟化做准备)==> kvm_mmu_load==>mmu_topup_memory_caches==>mmu_alloc_roots-->mmu_alloc_direct_roots(根据当前vcpu的分页模式建立 ept顶层页表的管理结构)==>kvm_mmu_sync_roots
4.3 gfn_to_page
该函数处理GPA的页号到HPA的page结构:
- gfn_to_page==>gfn_to_pfn==>gfn_to_pfn_memslot==>__gfn_to_pfn_memslot==>__gfn_to_hva_many|hva_to_pfn==>hva_to_pfn_fast|hva_to_pfn_slow
4.4 分配页表
- mmu_alloc_roots-->mmu_alloc_direct_roots-->kvm_mmu_get_page-->kvm_mmu_alloc_page

4.5 EPT vm-entry
①KVM_REQ_MMU_RELOAD-->kvm_mmu_unload-->mmu_free_roots
②KVM_REQ_MMU_SYNC-->kvm_mmu_sync_roots-->mmu_sync_roots-->mmu_sync_children-->kvm_sync_page-->__kvm_sync_page
③KVM_REQ_TLB_FLUSH-->kvm_vcpu_flush_tlb-->tlb_flush-->vmx_flush_tlb-->__vmx_flush_tlb-->ept_sync_context-->__invept
进入非根模式下,根据不同事件针对内存做相关处理。
4.6 EPT VM-exit
①设置cr3
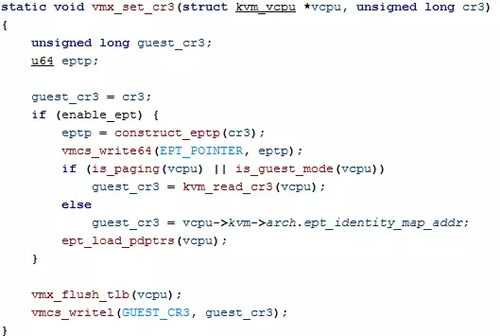
mmu_alloc_direct_roots中会分配arch.mmu.root_hpavcpu_enter_guest的时候会调用kvm_mmu_load==> vcpu->arch.mmu.set_cr3(vcpu,vcpu->arch.mmu.root_hpa)这个函数要申请内存,作为根页表使用。同时root_hpa指向根页表的物理地址。然后可以看到,vcpu中cr3寄存器的地址要指向这个根页表的物理地址。
②handle_ept_violation
- -->kvm_mmu_page_fault-->arch.mmu.page_fault-->tdp_page_fault

__direct_map 这个函数是根据传进来的gpa进行计算,从第4级(level-4)页表页开始,一级一级地填写相应页表项这些都是在for_each_shadow_entry(vcpu, (u64)gfn << PAGE_SHIFT, iterator) 这个宏定义里面实现的.这两种情况是这样子的:
a.如果当前页表页的层数(iterator.level )是最后一层( level )的页表页,那么直接通过调用 mmu_set_spte (之后会细讲)设置页表项。
b.如果当前页表页 A 不是最后一层,而是中间某一层(leve-4, level-3, level-2)
而且该页表项之前并没有初始化(!is_shadow_present_pte(*iterator.sptep) )那么需要调用kvm_mmu_get_page 得到或者新建一个页表页 B然后通过 link_shadow_page 将其link到页表页 A 相对应的页表项中
4.7 EPT遍历操作
for_each_shadow_entry这个是定义在mmu.c中的一个宏,用来不断的遍历页表的层级。
4.8 影子页表
init_kvm_mmu==>init_kvm_softmmu
在上述的ept的过程中,根据参数不同会有不同分支大体逻辑保持一致,毋庸赘言。



















