【51CTO.com原创稿件】七年一剑,华丽蜕变。自2012年起连续6年15场峰会,凝聚大量技术专家,博观而约取,厚积而薄发。2018WOT全球软件与运维技术峰会扬帆起航,围绕12大核心热点,汇聚海内外60位一线专家,打造高端技术盛宴!
在“大数据处理技术”分论坛现场中,宜信技术研发中心高级架构师王东将给听众带来一场名为《实时敏捷大数据在宜信的实践及开源平台DBus+Wormhole》的主题演讲。在会前,51CTO记者采访到了他,请他提前“剧透” ,精彩演讲内容就让我们“先睹为快”吧!

王东,宜信技术研发中心高级架构师,主要负责日志归集、流式处理和大数据业务产品解决方案,包括实时敏捷大数据技术栈基础组件——DBus实时数据总线平台的建设和NLP技术解决方案的建设和探索等。王东拥有多年从事分布式数据库引擎研发经验,在加入宜信之前,曾就职于Naver(韩国***搜索引擎公司),担任中国研发中心资深研发工程师,负责开源项目CUBRID-cluster分布式数据库开发和CUBRID数据库引擎开发工作。
用户对实时敏捷大数据的要求越发强烈
大数据发展到今天,越来越多的实时业务场景涌现,通过流式处理技术实现数据的实时化和从数据中快速发现价值成为趋势。但是,流式处理的实施存在较大难度,包括:人才短缺、开发成本高、上线周期长等,这就导致实时敏捷大数据的要求越发强烈,如何低成本、快速落地数据产品成为很多公司考虑的问题。
王东告诉记者,宜信也面临着相同的需求和痛点,遇到了同样的挑战。在过去两年中,宜信通过建设实时敏捷大数据DBus(实时数据总线平台)和Wormhole(实时数据交换平台)两个基础服务平台,使得实时数据能力和快速实施数据产品能力得到了大幅提升。
据介绍,实时敏捷大数据技术栈组件DBus和Wormhole已经在宜信公司内部宜人贷、大数据创新中心、技术研发中心等多个一级技术部门作为基础设施提供服务,并于2017年9月开源。目前,这两个基础服务平台一直在维护和迭代中,一些社区用户和企业用户也在试用和使用中。
基于实时敏捷大数据理念构建的两大基础平台
前面提到,用户对实时敏捷大数据的要求越发强烈。在本次大会中,王东将结合宜信在实时敏捷大数据方面遇到了问题、需求和挑战等,从多个维度进行分享。
王东表示,大数据应用要快速落地,除了建立大数据思维和数据驱动业务为导向之外,还面临着诸多挑战:
一)大数据技术生态体系庞杂,技术门槛高,需要对大数据技术、架构、算法、业务都懂行的复合型人才;
二)传统商业智能BI应用的失败教训多,存在项目周期漫长、成本高、数据用户参与度低、考验客户耐性等诸多问题,且并没有从BI实施中获得更多的成功经验;
三)大数据应用的标准化和产品化问题。数据的动态性、时效性、多样性怎么进行标准化管理,离线分析、在线分析、实时分析如何融合等。
基于此,宜信对实时敏捷大数据提出了自己的理解:
一)数据是实时计算和实时流转的;
二)通过组件平台化的方式,提供平台服务,让数据从业者能够更多介入并释放数据处理能力,回归数据和业务本质;
三)通过接口标准化方式,使得数据能够在不同组件之间轻松流转;
四)通过可视化的方式进行配置,降低大数据产品开发门槛,同时降低运维成本;
五)基于SQL的方式来实现自助化,能够快速原型验证,与需求方形成反馈闭环快速迭代,证明有效,从实践中快速沉淀大数据产品。
以上,通过实时化、组件化、标准化、可视化和自助化的方式提供技术平台,实现大数据的快速实施、快速验证、快速迭代,从而达到让大数据应用快速落地,实现商业价值。
王东告诉记者,宜信在数据流转中存在一些问题和痛点,包括数据孤岛的问题,数据时效性差、一致性差的问题,无法快速响应业务需求开发数据产品的问题,运维实时数据产品困难等问题。业务方希望方案能够满足低延时、高实时性、接入方案侵入性小、能够快速开发数据产品、运维成本低、数据安全和权限高等。并且,要求方案能够接受定制化,实现数据存储多样化和支持多种目标,例如HDFS、BASE、ES、Mongo、MySQL等。
宜信基于对实时敏捷大数据的理念,构建了DBus实时数据总线平台 + Wormhole实时流式处理平台。其中,DBus作为实时数据总线平台,关注数据的抓取和结构化;Wormhole作为实时流式处理平台,提供基于配置SQL的方式进行各种流式计算,并支持落库到各种常见数据目标中。
王东表示,考虑到参会者大都具有技术背景,因此他将从技术层面具体介绍这两个平台的内部架构,重点介绍DBus和Wormhole这两个平台的关键实现原理,例如:DBus 数据增量数据如何生成,全量数据如何切片;Wormhole平台中数据如何进行流式计算优化,如何高效落库等。并结合应用场景,对这两个平台解决的一些实际问题进行介绍,包括:实时营销、实时运营和数仓同步等。
结合场景应用的DBus+Wormhole流式处理引擎
大数据处理技术是一个很大的话题,涉及到数据采集、数据流转、数据处理、数据存储、数据展示等诸多方面,包含批次、流式、AdHoc 、预算等各种访问模式。在实时流式计算方面,考虑到各种计算引擎的特点和适合的场景,DBus+Wormhole采用了不同流式处理引擎。
王东表示,业界流式处理的引擎不少,例如:Storm,Spark Stream,Flink,Samza,Kafka Streams 等。如何选择流式处理引擎,先要考虑各种计算引擎的特点和适合场景。
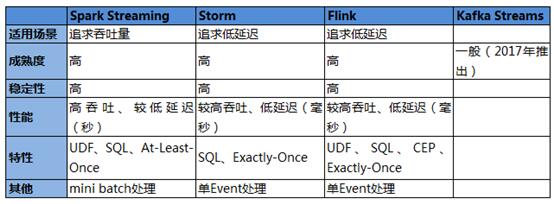
各种流式计算引擎的优缺点
据介绍,自2016年开始,宜信就启动了两大平台的建设,考虑到当时社区比较成熟的情况,DBus和Wormhole两个平台各自选择了不同的流式处理引擎。
DBus关注数据源的数据流出,希望以较低的延迟让后端用户更快的消费到***数据,尽可能的保证数据顺序性。因此,DBus采用了storm作为处理引擎。Wormhole关注数据的实时流转和实时落库。对于数据流转来说,最早支持SQL比较好的是spark;另外,从落库的角度来说,以批量的方式落库比单条落库效率要高很多。因此,Wormhole采用Spark Streaming作为处理引擎。
在保证数据一致性方面,需要在整个设计过程中考虑计算引擎支持这一要点,否则会出现数据乱序的情况。宜信采用了让DBus保证输出的每条日志数据是唯一标示和顺序性ums_id的方案。为了做到这一点,DBus采用了物理文件编号和日志偏移量作为基础,保证了即便DBus重做数据的ums_id_,都不会改变。此外,Ums_id_的唯一性和顺序性带来了诸多好处,比如Wormhole落库时,通过比较ums_id_就能知道哪条数据更新过,哪条数据会被覆盖等。
另外,作为流式Extract-Transform-Load 工具,DBus和Wormhole还做出许多额外的努力。首先,作为数据的采集方(Extract), DBus为了减少对数据源端的侵入性和实时性,没有用trigger或时间戳的方式抽取增量数据,采用了通过读取数据库备库日志的方式获得增量数据。为此,不同的数据源采用了不同的解决方案。同时,DBus还实现了数据源端schema变更自动感知的能力,区分兼容性变更和非兼容性变更,自动将变更体现在UMS的版本上,并提供邮件通知报警的功能。
对于数据的实时转换(Transform),为了提高流上Spark SQL Join性能低下和Join不到的问题,Wormhole重新实现了流上join的逻辑,大幅提高了流上join的性能。并且,引入了时间窗口的概念,对于没有lookup到的数据选择在时间窗内,随同下一批mini batch的数据再次进行join,最终提高join的成功率。
为了更有效的落库装载(Load),Wormhole首先基于主键对batch数据进行repartition,这样合并了不需要的写入,减少了写入量的同时也避免了死锁。另外,采用基于batch和基于预读的逻辑,大幅提高了batch的写入性能。
***,在流式处理过程中,如何验证整个链路数据的畅通性、时效性,在没有数据的情况下如何知道整条链路是正常工作的?DBus从源端引入了心跳机制,通过定时向源端插入心跳数据,并沿路进行实时捕获。整条链路从抓取到转换和最终落库,都提供实时监控和预警,保证在即使没有任何用户数据的情况下,心跳数据也在实时探活和自我证明,进行自我预警和实时监控。
5 月 18 - 19日,北京•粤财JW万豪酒店,全球最值得关注的IT技术盛宴与您不见不散。2018WOT全球软件与运维技术峰会一定是您发现全新思路、挖掘***思想、拓展人脉的重要平台。
目前我们的各项票种已全面发售。需要提醒您的是,购票越早,折扣越大!与KOL零距离交流,呈现不一样的“英雄盛宴”!
点击官网了解详情:wot.51cto.com
7折预售中,抢票从速。