【51CTO.com原创稿件】
一, 背景介绍---点播视频源站分发的痛点
点播视频观看的流程与源站定义
点播,是相对于直播说的,英文命叫VOD (Video on Demand),顾名思义,某个观众demand了,才有video看,看到的内容是视频的开始;
而直播呢,是不管有没有观众去看的,视频一直在往前走,某个观众进来时看到的,是当时的视频。
点播视频的内容非常多样化,有连续剧、电影、体育录像、自媒体制作的视频,甚至包含(现在非常火爆的)短视频。
大家有没有想过,每次打开一个点播视频的时候,背后的操作是什么样子的呢?
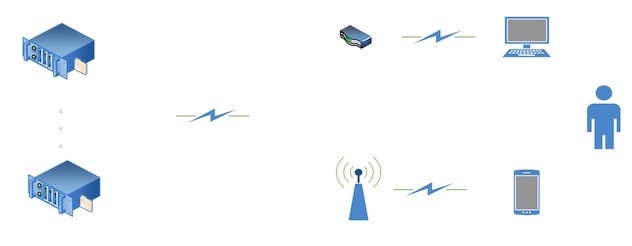
简单的一种观点是图上这样:
- 视频网站提供点播资源,比如说PPTV新上了一个连续剧,一个电影,或是短视频网站新提供了一个新的短视频
- 观众通过网页、app等访问网站,进行视频的观看
实际上,情况没有这么简单
视频网站的提供的点播资源,也就是文件,是放在自己公司的服务器上面的,这个服务器可能是买的,也可能是租的,
存储这些文件的服务器集群,就叫做源站
这些视频文件,实际上不会直接给用户访问,而是通过cdn逐级分发出去的,所以这些存储集群,还要负责对接CDN
所以源站的作用是负责存储和对接CDN,这里有个分工,视频网站拥有视频版权,CDN擅长分发
下面我们来看看点播、包括短视频的视频网站的处理流程,
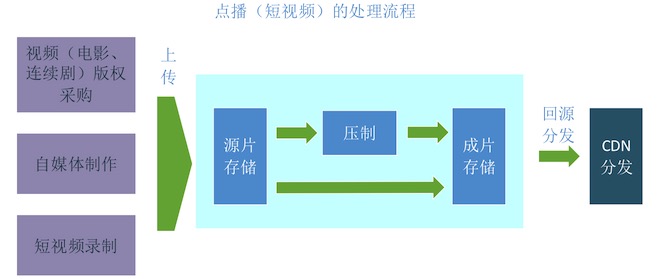
流程如下:
- 内容生成(这一点是在视频网站之外就可以做的)。视频网站采购版权,或者是自媒体作者制作好视频,短视频作者在手机端录制好视频
- 把内容上传到视频网站的源片存储。视频网站的编辑上传采购的版权视频,自媒体和短视频作者上传自己制作的视频
- 选择是否压制(根据特性)。视频网站根据视频的特性,选择是否对视频进行压制处理, 例如短视频一般不需要压制即可在手机播放,而电影连续剧一般会压制多档码率
- 成片存储。压制好(或不用压制)的视频,叫做成片,存储起来
- 回源。CDN从成片存储回源下载这些视频,给观众看
源站与CDN的网络拓扑
我们知道有以下事实:
- 一个视频网站的(成片)视频,一般不会只放在一个机房内.如PPTV的视频,体育类的会放在上海的机房,原因是体育演播室在上海,本地录制方便且无需互联网带宽;影视类的都放在武汉的机房,原因是编辑中心在武汉。
- 一个视频网站会对接多个CDN,也可能自己建设CDN。如PPTV,在自己CDN的基础上,和国内外各大知名CDN厂商都有深度的合作
- 每个CDN(包括自建)供应商对应的网络接入点位置,质量都有很多区别
另外,对于视频网站来说,一个视频文件,只用保存一两份(当然,视频公司会做冷热备份等等操作,所以,实际上落盘的存储不只这么少,这个细节属于存储高可用的范畴,就不深究了),
为了存储在不同机房,唯一的一份数据同时发到多个CDN,源站内部需要使用多级缓存的结构。
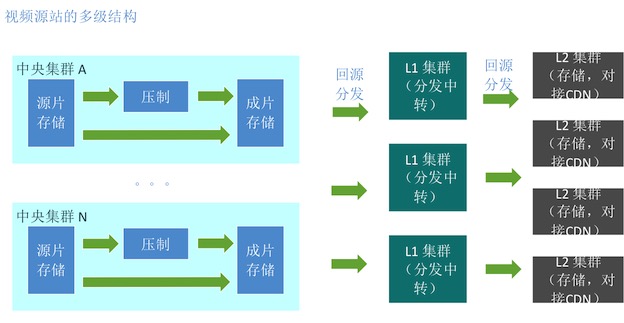
在视频源站内部的多级缓存之间,也就是多个机房之间的分发,叫做内部分发;
视频源站(L2集群)到CDN接入点间的分发,叫做外部分发。一般L2集群对接CDN接入点,在与CDN联调对接时,就会选好优质线路,甚至在一个运营商的机房。
所以,我们介绍的重点还是,如何把视频文件从N个成片存储集群,通过K个L1集群,分发到M个L2集群中。
点播视频源站分发过程中,存在的问题
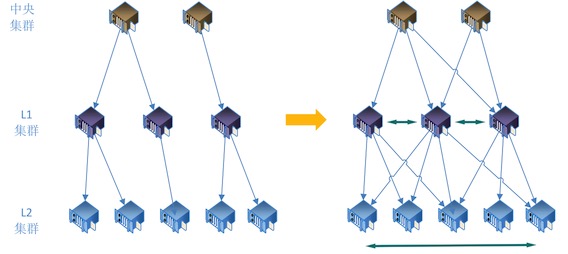
- 点播视频从中央集群向L1,L2集群(机房)分发时,采用树状分发(这个树的建立,会根据经验或者网络本身特性),每个中央节点到不同的L1机房线路质量差距很大,不同的L1机房到L2机房质量也差异很大
- 分发过程走的是互联网线路(专线太贵),互联网线路的稳定性不可预期,有时网络抖动,会造成分发失败,甚至挖断光缆导致某条干网不可用的事故也经常出现,某条线路或者某个机房的问题,可能会造成区域性的不可用
- 不同集群(机房)在规划和建设时,服务器(计算、存储、IO)能力、出入口带宽不一样,不同集群向下分发时对应的节点数也不一致,会出现不同集群间的负载差异较大的情况,俗称忙的忙死闲的闲死,忙的节点,很可能成为瓶颈
点播视频源站分发链路优化的意义
如何解决上面说的问题呢,我们自然的会想到,如果每个文件的分发过程,都能自动选择一个***秀的链路,而不是根据那个配置死的回源树,那么分发的过程将会带来这些优势:
- 更加高效和稳定
- 避免区域性的故障
- 不同集群(机房)的负载更加合理和平均
二, 节点间数据分发质量的评估
为何先评估两个服务器节点间的分发质量
前面提到了优化的办法是选择好的分发链路,那么,到底怎样分发链路才是一个好的链路呢?我们先来看以下事实:
- 链路是由数据通过的服务器节点构成的
- 链路中,相邻的服务器节点传输质量的最差值,决定这条分发链路的质量上限
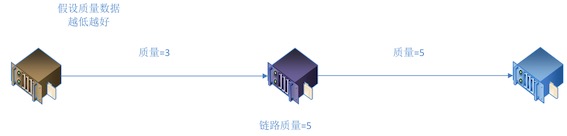
所以,我们首先研究两个服务器节点间传输质量的情况
两个服务器节点间传输质量的评估
那么,用什么的来评估两个服务器节点间的传输质量呢,我们自然希望有一个量化的数据,一个简单的想法就是“文件下载耗时”。
影响两个服务器节点间的传输质量(下载耗时)的因素有这些:
- 文件大小
- 服务器之间网络线路的情况,包括数据延迟、丢包率、跃点数等等
- 发送服务器(接收服务器)的当前负载,包括CPU负载,内存用量,IO负载,当前带宽,存储用量
- 当前时间
我们接下来会简单分析,这些因素会对下载有什么影响
文件大小:文件越大,下载越慢,耗时越长
服务器之间网络线路的情况:两个服务器之间的网络情况,具体有这些指标
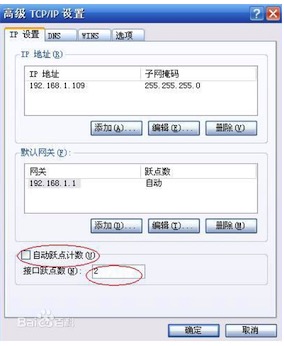
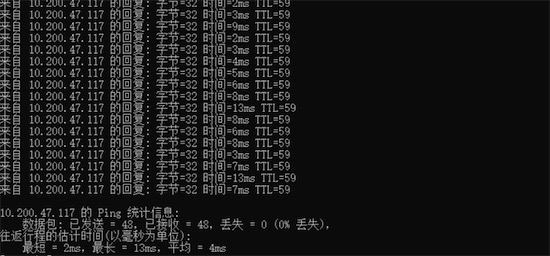
- 延迟:下图中的ping指令,可以测试出两个服务器间的延迟信息,对于数据传输来说,延迟越小越好
- MTU(Maximum Transmission Unit):是指一种通信协议的某一层上面所能通过的***数据包大小(以字节为单位)。***传输单元这个参数通常与通信接口有关(网络接口卡、串口等),如下方图中所示,传输3000字节,如果mtu设置成1500,需要打成两个包,而当mtu设置为1492,则需要打成3个包,传输3个包当然要比2个耗时更多。
- 丢包率:下图中的ping指令,测试出当前丢包为0个,在网络出现问题时,这个数据可能不为0,视频下载基于HTTP,底层是TCP协议,丢包后要重传,丢包率越低会越好
- 跃点数:跃点数代表两个服务器间通信时经过的路由设备数目,数据通过路由器时,路由器中会有数据包队列,队列过满,数据有被丢弃的风险;路由器在计算数据包下一跳的时候,也会有一定的耗时;
- 服务器的***带宽:服务器***带宽,当然是越大越好(当然成本也越高),例如家里装宽带,500M的肯定比100M的好(也更贵)

发送服务器(接收服务器)的当前负载情况
- CPU负载:CPU负载在不大的时候,对下载影响不大,当CPU负载超过一定值时,会严重影响下载的效率
- 内存用量:内存用量在不高的时候,对下载影响不大,当内存用量过一定值时,会严重影响下载的效率
- IO负载:IO负载在不大的时候,对下载影响不大,当IO负载超过一定值时,会严重影响下载的效率
- 当前带宽使用情况:当前带宽在不接近***带宽的时候,对下载影响不大,当它接近***带宽时,数据包传输阻塞,会严重影响下载的效率
图中为top指令看到的当前机器负载
当前时间:
以上提到的数据,都是随着时间抖动的,例如说带宽数据,视频网站早上看的人少,晚上看的人多,工作日看的人和周末又不一致,而遇到一些节假日,又有新的特点,整体互联网的使用趋势是向上的,所以从一个长期时间来看,带宽数据应该是波动向上的。
这里要提一个问题,正是由于相同尺寸、相同链路的下载速度,在不同时间点的表现差异巨大,才需要引入一个动态的预估机制。
例如,一个文件2G大小,我们在开始下载前,觉得链路A是***的,但是实际上下载了300M后,链路的A的质量已经不好了,这是链路B可能反倒更好,我们想要达到的目的是,计算出下载完2G大小文件的综合耗时***是哪条。
建立两个节点间数据传输质量模型的设想
度量两个节点间的分发质量,我们可以用一个数值,下载时长(Download Time,缩写为DT)来表示,这个数据受到很多具体的、随时间呈现一定规律的因素(变量)影响,那么我们可以有一个美好的设想:用一个模型,或者说是一个函数,来描述这些因素与DT间的关系,后续新的文件下载时,使用这个模型,输入当前这些变量,预测文件下载的耗时。
假设函数如下:
DT = Func(file_size,current_time,defer,cpu_load,mem_load,io_load, …….)
我们知道一个文件大小为100M,当前时间点已知,节点间这些变量已知,我们可以根据这个函数算出时长来。
三, 机器学习算法的设计和实现
机器学习的引入
前面提出了建立一个模型(函数)的设想,来预测DT,这个模型如何建立呢?
我们先看数学上是怎么做的,在数学范畴里,对于已知一组自变量、应变量数据,反过来求函数的过程,叫做拟合
二维空间里,一个自变量,一个应变量,就是简单的曲线拟合,
三维空间了,两个自变量,一个应变量,就是曲面拟合,
N维空间里, N-1个自变量,1个应变量,也能拟合,
这些具体的算法在数学书里都有,最小二乘法什么的,感兴趣的同学可以自行查看。
而在计算机科学范围内,AI研究的先驱者,提出了利用神经网络做机器学习的办法,来处理这个问题。
机器学习是什么呢,现在网上有很多解释,我们这里简单来说明下
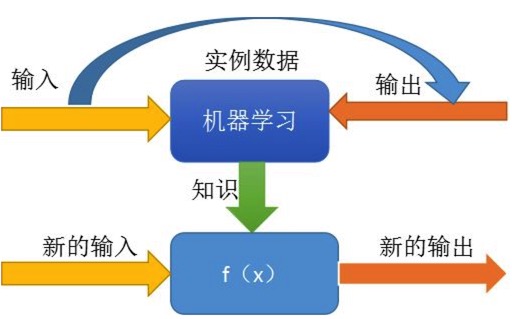
我们给机器(计算机上的程序)已知的输入、输出,让它去找规律出来(知识发现),然后我们让它根据找到的规律,用新的输入算出新的输出来,并对这个输出结果做评价,如果合适就正向鼓励,如果结果不合适,就告诉机器这样不对,让它重新找规律。
其实这个过程在模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
机器学习的本质就是让机器根据已有的数据,去分析出一个模型来表示隐藏在这些数据背后的规律(函数)。
如何实现这个找规律的过程呢?
我们先说数学上是如何建立函数的(如何做拟合),过程如下:
- 选取拟合函数(幂函数,指数函数,对数函数,三角函数等)
- 设定参数
- 比较误差,调节参数
- 迭代
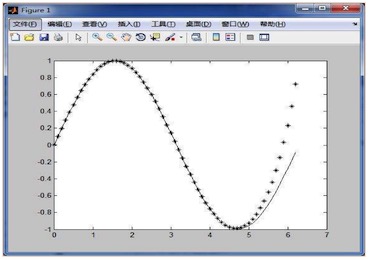
对于图中这一系列点,我们***感觉这些点的排布是符合正弦函数的,那么我们使用三角函数中的正弦函数去拟合它,并且设定函数的周期、振幅、相位等等参数,你和后,发现在x > 5后,还是有一定误差的,这就需要去判断误差是可接受,如果不可,则需要重新做拟合。
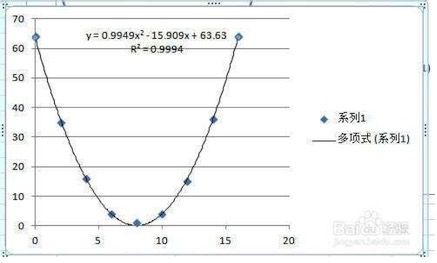
对于上图中的这些点做拟合,我们发现这些点的分布好像是个抛物线,那么根据我们中学的数学知识,抛物线是幂函数中二次幂函数的图像,所以使用二次幂函数做拟合,最终得到一个方程来。
和数学领域一样,AI领域里,输入通过一个模型(函数)变成输出,这个模型(函数)靠什么确定呢,靠猜!
猜不是问题,问题是如何猜的更准?
AI的先驱提出了模拟人类大脑神经元的思路,来处理如何猜模型的问题
神经网络和人工神经网络
大脑神经元是这个样子:
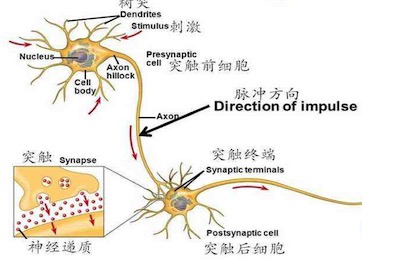
大脑的神经网络是这个样子:
大脑神经元的特点是这样,每个神经元只负责处理一定的输入,做成一定的输出,给下级节点,***组合起来,形成人脑中的神经网络,这也就是动物思考的过程了。
人工神经网络就是,人为的构造出一些处理节点(模拟脑神经元),每个节点有个函数,处理几个输入,生成若干输出,每个节点与其它节点组合,综合成一个模型(函数)。
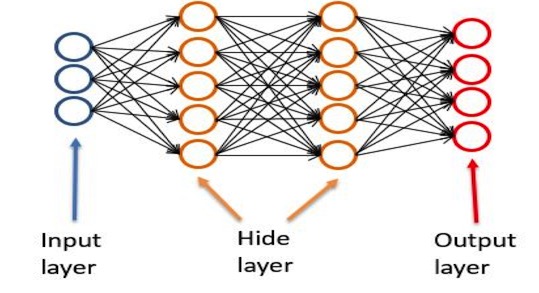
从左到右分别是输出层, 隐藏层,输出层。
输入层负责接受输入,输出层负责输出结果,隐藏层负责中间的计算过程。
隐藏层的每一个节点,就是一个处理函数。隐藏层的结构,也就是层数,节点数,还是每个节点的函数将决定整个神经网络的处理结果。
Tensorflow的介绍
Tensorflow的介绍网上非常多(可以搜索查看),按照本文的上下文,我们简单的介绍如下:

Tensorflow是一个通过神经网络实现深度学习的平台,我们给它输入,输出,约定一些(猜测模型)的规则,让他去帮我们猜测具体模型。
使用TensorFlow的步骤可以简单的概括为,收集训练数据 训练 比较 迭代 …..
训练数据的收集
我们来介绍如何为建立两个节点间的传输质量的模型收集训练数据。
前面介绍过,数据分为输入和输出数据。
输入数据为4类:
- 下载的文件大小-可直接记录
- 当前时间-使用unix timestamp
- 网络情况的统计-来自一些测速工具
- 发送(接收)服务器的负载情况-来自zabbix的记录
输出数据为下载一个文件的时间记录,需要做离散化处理(后续介绍离散化原因)
Zabbix 的介绍:
- 基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案
- zabbix能监视各种网络参数,保证服务器系统的安全运营;并提供灵活的通知机制以让系统管理员快速定位/解决存在的各种问题
- zabbix server与可选组件zabbix agent
- 支持Linux,Solaris,HP-UX,AIX,Free BSD,Open BSD,OS X
Zabbix的anget部署在传输节点上,定期收集机器的负载和带宽使用数据, 并向中心(zabbix server)汇总。
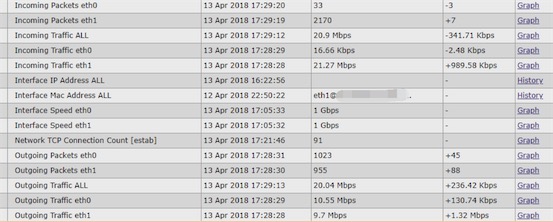
下图是zabbix对于当前带宽的统计情况:
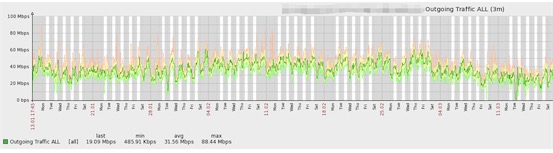
下图是3个月的带宽负载:
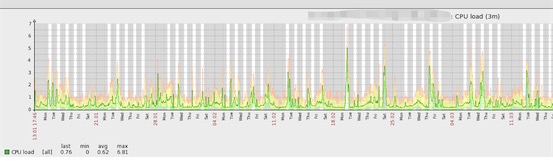
下图是3个月的cpu负载:
使用IPERF工具收集网络数据
IPERF工具可以收集以下数据:
- 当前服务器之间的传输带宽
- 丢包率
- MSS、MTU
- 支持tcp/udp
下图为iperf的使用截图:
Ping工具收集延迟,测试节点连通性:
Tractroute工具收集节点间跃点数信息
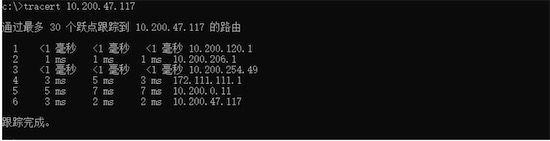
(windows cmd中,命令为tracert)
训练的准备
数据的组合与格式化:
将网络数据,负载数据,文件大小,时间,格式化后组合成一条json。
将下载耗时数据分段后做离散化处理,这里解释下,为何要对结果(输出)做离散化,TensorFlow擅长做分类处理的学习,当分类的结果集合是个连续集的时候,可能的结果就有无穷多个,这将大大加大训练的难度,降低训练的速度。把结果离散化处理好,接近时间的时间处理成一个值,超过一定阈值的时间都化为一个值,这样结果的区间有限,将大大降低训练难度。
训练模型参数的预设定:
我们前面说到数学范畴的拟合时,会先根据自己经(xia)验(meng),从幂函数、三角函数,指数函数,对数函数中选取一种或是多种组合起来作为拟合的基础。
对于神经网络来说,我们也不能一上来啥都不管,就让它乱猜,而是要根据已(geng)知(shi)经(xia)验(meng),设定模型和参数。
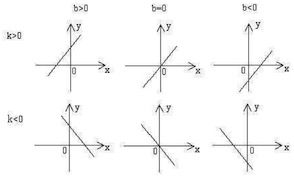
前面提到,每个节点都是一个函数,那么,我们选什么函数呢,我们先考虑最简单的情况,线性函数,我们用一堆线性函数组合起来成为一个网络,这个网络描述的模型,肯定还是个线性模型,它不足以描述世界上大部分的规律。
下图是常见的线性函数:
那么我们考虑,把每个函数再做非线性化,就是在一个线性函数外,再套一个非线性函数(称作激活函数),再组合成一个网络,这个网络描述的模型,基本上能覆盖世界上大部分的规律了(别问我原因,我也不懂。。。)。
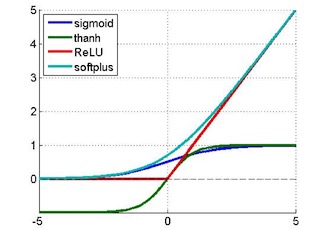
下图是常使用的一些非线性函数:
构成的网络:
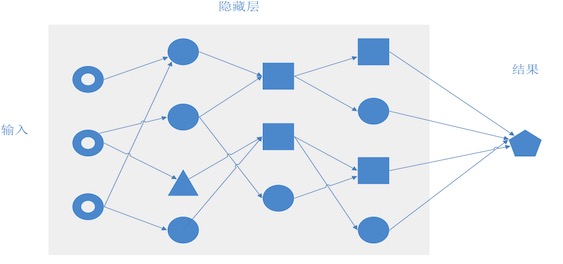
每个节点上的函数类型,我们先猜了一个,那么,网络的结构呢,到底用几层,每层几个节点,这个事情,在做不同领域的神经网络时,选择真是千差万别。
我们在评估节点间传输质量时,先根据(拍)经(脑)验(门)设置层数为15,每层50个节点,节点函数也按照基本经验进行设置。
下面的参数将影响TensorFlow的训练结果:
- 初始学习率
- 学习率衰减率
- 隐藏层节点数量
- 迭代轮数
- 正则化系数
- 滑动平均衰减率
- 批训练数量
- 线性函数、激活函数设置
其中,隐藏层节点数,迭代轮数,批训练数量,线性函数、激活函数设置将影响较大,如何设置,前面已经提及,而剩余参数影响稍小,有兴趣的同学可以自行搜索。
TensorFlow的处理流程
单个节点处理如下图:
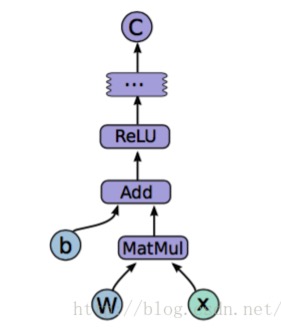
一个节点做了 ReLU(Wx+b)再与其它节点组合,最终生成输出结果。
整体上分为以下几步:
- 数据输入
- 训练
- 训练结果审查
- 调节参数
- 重新训练
- 训练结果审查
- ……
- 训练结果满意
通过Tensorflow的结果,计算***传输路径
当我们经过大量的训练和调优后,得到了每两个(需要的)服务器节点间的训练模型,通过这个模型,输入当前文件大小、时间、服务器和网络的测试状态,就可以算出一个预期的下载传输耗时。

我们把节点间两两计算的结果,代入到网络拓扑图中
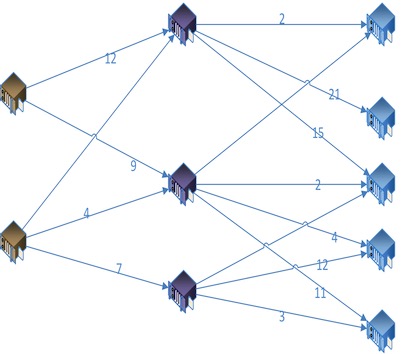
使用最短路径算法,计算***(和次优)的传输路径
这里是的算法为Dijkstra算法 (翻译为 迪杰斯特拉算法)
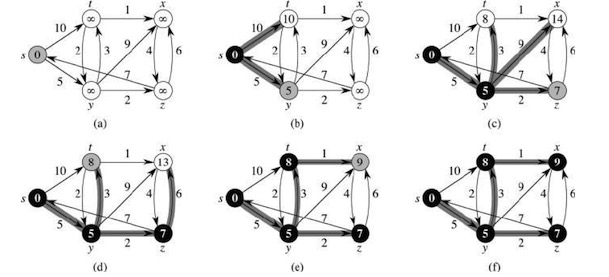
这是一个非常经典的最短路径算法,就不占篇幅介绍了,有兴趣的同学可以自行搜索。
整体处理流程回顾
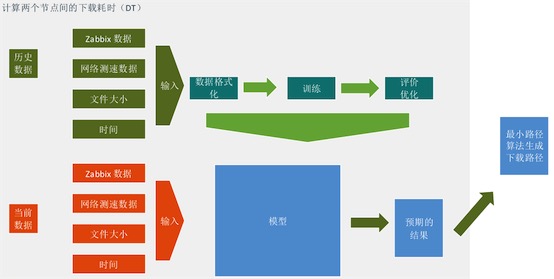
- 首先,收集训练数据,使用zabbix数据、网络测速数据、文件大小、当前时间信息为输入,下载耗时为输出,进行模型训练,并对模型做持续的优化。
- 使用当前的zabbix数据、网络测速数据、文件大小、当前时间信息为输入,使用训练好的模型做计算,得到预期的下载结果。
- 相关节点,两两计算预期结果,构成一个传输网络,使用Dijkstra算法计算传输网络内的最小路径。
四, 未来展望
使用***流算法进行文件分片下载
目前的算法针对的是整体文件进行下载,实际上,流媒体服务器早已经实现了文件虚拟切割,http协议也有range请求,在此基础上,把一个文件分割,通过多条链路同时下载,将提升下载速度,也将进一步提升网络利用率。
具体可参考EK 算法,Dinic算法等。
使用最小费用***流对***流算法进行改进
考虑到每个机房,每条线路建设时,成本不一样。
在***流有多组解时,给每条边在附上一个单位费用的量,在满足***流时的计算最小费用是多少,这样对于成本使用将更精细,机房如需扩容也将做成指导。
在直播领域的应用
目前点播源站内部分发,进行模型训练采用的输入数据是上述数据,结果是下载耗时;对于直播来说,可以使用和直播相关的数据进行组合与训练,结果为QoS,生成新的模型,对直播回源的内部调度预测***链路。
【作者介绍】
曾小伟,PP云技术副总监,图像编解码、高性能计算出身,辅修AI(NLP方向),12年以上流媒体服务端开发及架构设计经验。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】